

Slices instead of components. Or maybe: slices over components. Yes, that sounds better, more Agile-manifesto like: “While there is value in the item on
the right, I have to come to value the item on the left more.”
Slices are the manifestations of Agile requirement analysis increments in code. They are the primary code structures, not the only ones, but the primary. Why? Because structure should mirror demand. And what’s in highest demand in software development is… productivity.
Productivity means churning out functionality at a never decreasing speed, better even at an increasing speed. That’s what customer want. Primarily.
Their primary demand is a trait of software development teams, not software. They want teams to produce ever more in less time.
What does that mean for structuring software?
It’s common knowledge that so called non-functional requirements — e.g. performance, scalability — require software to be structured in a particular way. The shape of software needs to match requirements.
From that follows, if the highest demand is for productivity, then software needs to adapt its shape to that, too. Firstly software has to be structured to support productivity; only then structure may bend to other needs within the constraints of a structure for productivity.
How this basic structure may look I developed in this article:

It’s made up of independent slices each responsible for responding to a trigger event initiated by a user. Slices (ideally) are not knowing of each other; they are not services to each other. Their only connection is through a common, very primitive “data substrate”, an event stream.
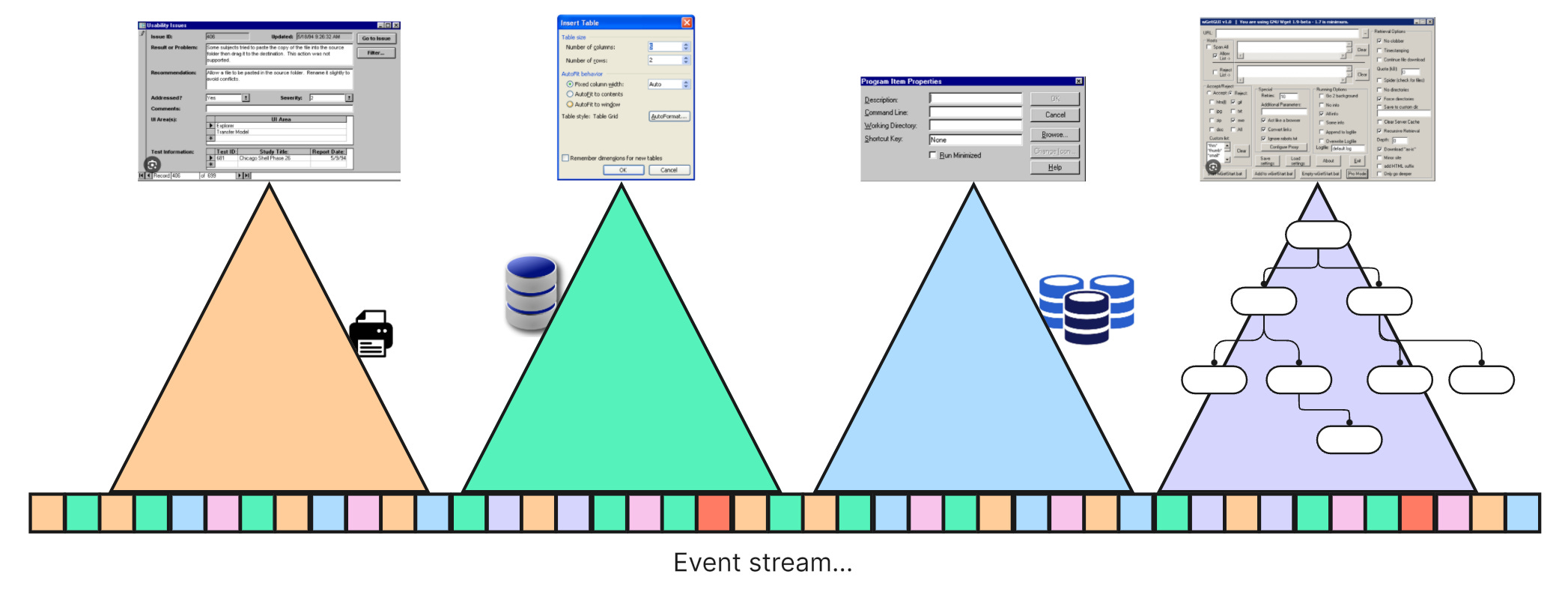
Of course, slices might need to access resources, e.g. call a REST service or write to the file system. But slices do not communicate with each other. Their only means of exchanging information is indirectly through the event stream by appending events and reading events.
The event stream is for recording all the facts about the application state. Its form is primitive on purpose: only that way facts can most easily be interpreted in a multitude of ways depending on the very different needs of slices.
To “pour” events into different “molds” for creating all sorts of highly optimized data structures is the recipe for high productivity as well as high performance and scalability. Each slice’s data structure is a particular view on the application state tailored to responsibilities of that slice.
This is, to me, the fundamental structure for all applications like the von-Neumann architecture is the fundamental structure for all computers today. (Ok, maybe not all, but most of the ones application developers deal with.)
Like in a biological cell a “string” is coiled up at the center — not of molecules but of events. It’s a record of all that happened to/in an application. It’s its memory which is interpreted by what’s around it.

I call this an AQ software cell because the only operations allowed on this fact stream are appending to it or querying it.

Putting an event stream at the center of an application is the idea here. A very, very simple fine grained data granulate instead of an intricate single, one-size-fits-all domain data model.
The intuition behind this is:
The more common something is, the less complex it should be.
Application state is the most common of all data. It’s shared by all parts of code. Hence it should have a trivial structure. Because only a trivial structure will stand the test of time. Only a trivial structure is open to all sorts of changes.
That is the case with an event stream. In an event stream all events stand for themselves. They might relate to each other, but they don’t depend on each other. The next event appended can be anything: for any purpose of any shape and size. It does not have to conform to any overall schema.
Hardly any planning is needed for an event stream. Its basic form is always the same: an append only store for JSON with some meaning attached (event type).1 All entries have the same structure: { eventType:string, payload:string } (plus some meta data).2
Event types are “invented” as needed slice by slice. They are matching the requirements “in that moment”. What is known as facts is encoded in events appended to the stream.
From this single primitive stream all slices can scoop events as needed for their purposes. Each is responsible for its own projections onto data structures matching the results to be produced.
This is so simple, so flexible, I’m still at awe.
But as it is often in life: the easiest things are hard to accomplish. We’re just not used to straightforward, plain solutions.
That’s why I want to take you on a tour from requirements analysis to implementation. How does an AQ software cell look in its simplest form in code? Sure, this will be a simple, small example — but the approach is the same for larger requirements.
Example scenario: a bowling game match
Let’s imagine this:
I would like an application to support my hobby sport “bowling”. Sometimes my friends and I are gathering for a match. I’d like the application to keep track of these matches by recording the games in each match, calculating each players score and show a leader board.
Each match has a title, e.g. “Christmas 2025”, and several participants (players). For each match we set the number of games for each player, e.g. Peter, Paul, and Mary are each supposed to play 3 games. The sum of the scores of each player’s games determines his or her placement at the end of a match after all games have been played.
The application should set up the games to play with each player in turn. Games can of course also be played in parallel on different bowling lanes if we managed to reserve more than one at the bowling center.
Once a game is started, the application should ask for a player to make a throw and enter the pins knocked down. Our little application unfortunately cannot be connected to bowling alley’s machinery and know the number of pins by itself.
Calculating the score during a game should be continuous according to the usual bowling rules: 10 frames, each 1 or 2 roles; spares and strikes need to be recognized to add bonus points to the score and allow for 1 or 2 extra roles after the 10th frame.
This scenario is based on Robert C. Martin’s famous Bowling Game Kata. I just added some features around to make it more interesting and a “real” application. This exercise is not about TDD, but Event Sourcing.
I’m choosing this kata for its popularity (in the past) and because it’s not a so typical CRUD like a todo application. It’s not too small, and its domain is easy to understand.
Trigger-focused analysis
How to deal with such requirements in an Agile way? Analyse it with the goal to identify increments, i.e. small scopes of requirements promising to deliver value to the user.
Each increment then is implemented with as few iterations as possible. The smaller the scope the higher the chance to get it right the first time.
To focus on increments to me means to defocus data models, the overall domain. Of course I better understand the domain, but I am not obsessed with understanding it first. I trust I will learn about the domain while hunting for increments. I will get to know it incrementally.
Whenever I try to look ahead and learn (much) more than I need right now there is a risk of premature optimization and/or overengineering. With regard to the full requirements as they will be implemented in several weeks, months, years I am always ignorant today. True understanding I can only have in hindsight anyway.
To acknowledge this reality I try to focus on the immediate as much as I can. It’s switch between breadth-first and depth-first analysis. I’m trying to find a balance between smartness/arrogance, and ignorance/foolishness.
The initial goal for me is to find the triggers where users kick-off processes, some very short, others more long running. When do users “send a request” to be handled by the application? Which buttons do they want to click, which menu items to select, which keys to press in order for the program to execute a processes changing or reading the application’s state?
If the users and I can agree on that, then I have a list of entry points into slices. Slices being cross cutting code from “just beneath the UI” to resource and state access. It’s cutting across all concerns you might associate with layers in a layered architecture. But to me it’s just the body in a Sleepy Hollow architecture (see also here).

The guiding principle for me is the CQS: each slice is dedicated to either change application state or reading it. It handling either a command or a query. Sometimes triggers initiate just one such request, sometimes several. The trigger point thus might look hybrid — being not a pure command or query —, but behind the UI-facade slices are always either or.3
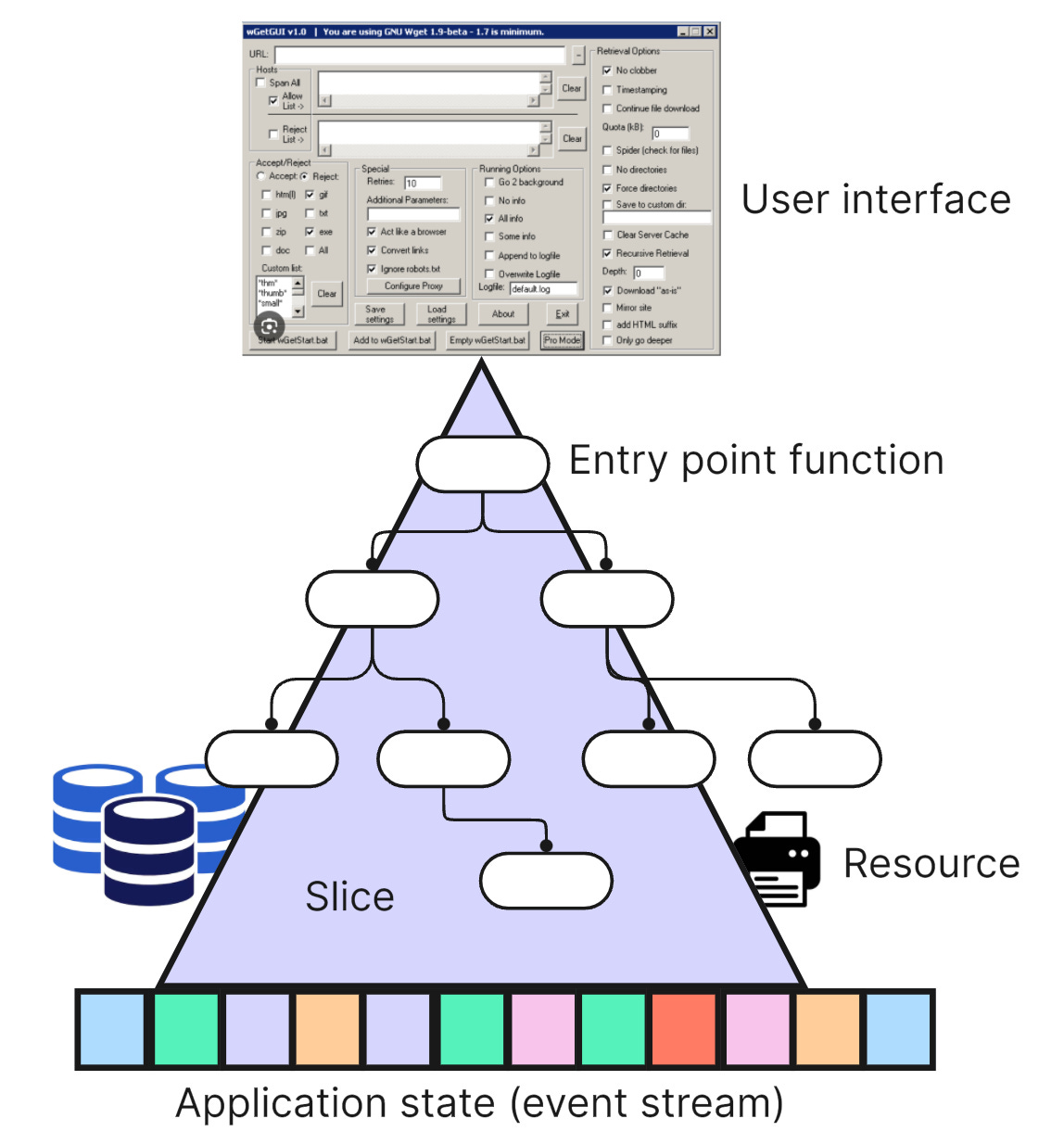
How do I identify slices with their trigger points and focused behavior? I analyse requirements “from the outside in”. I am mainly concerned with the user interface at first. As quickly as possible I want to get an idea of how users want to interact with the application.
Often times that means to start with a big picture because users don’t yet know what exactly they want/need. But the goal is always clear: a list of triggers located on dialogs/screens/pages.
I’ll spare you the “outer layers” of this kind of requirements analysis and jump right to where it becomes interesting: the dialogs with their transitions and interactions.
In the following image you see a snapshot of a sketch of what the (imagined) user and I came up with while going through the bowling match requirements:
there are dialogs (the rectangles), and
there are arrows signifying transitions between dialogs or interactions with a dialog.
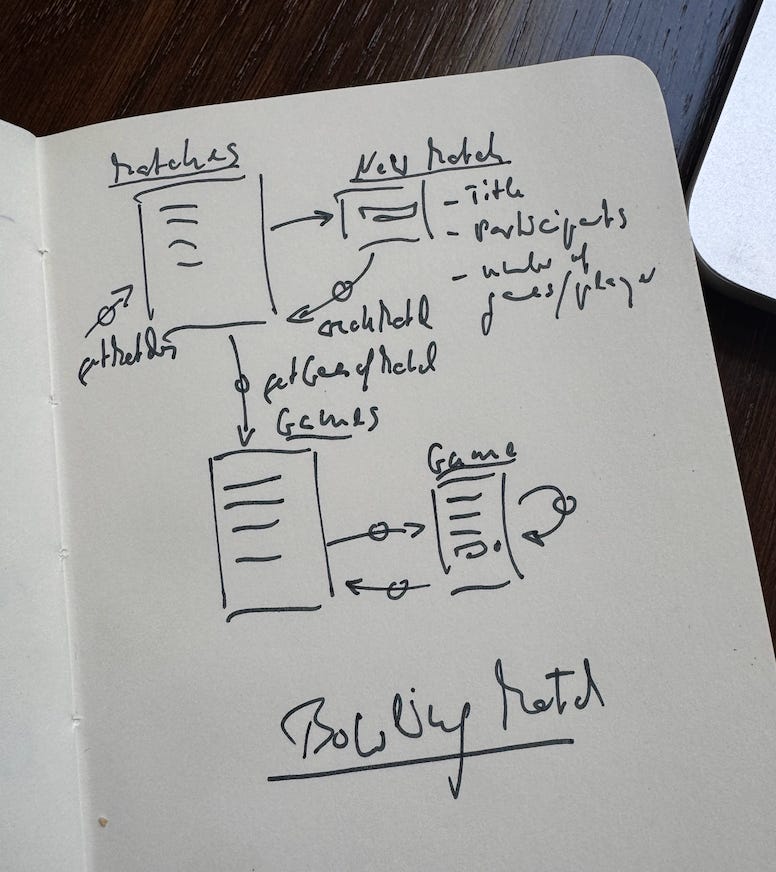
Let me explain how the user envisions to work with the application:
When the application is started it shows a list of bowling matches (dialog MATCHES).
From there the user can create a new match with a title, the names of the players, and the number of games each player should player during that match (dialog NEW MATCH).
Or the user selects a match from the list and gets displayed the list of games in that match (dialog GAMES). Players play in turn until each has played the defined number of games. Games have either been finished with a score or still have to be played.
From the list of games the user selects the next pending game to be played and the application guides the player through the game (dialog GAME): the player gets prompted to make his/her next throw and enter the number of pins knocked down. This continues until all throws have been made according to the rules, or the game is aborted.
From the sketch and the “user’s story” interactions can be derived. Each interaction consists of some input, and a trigger, and some output.
“When the application is started”: that’s the initial interaction.
Input: none
Trigger on command line: starting the application from the command line or by entering its URL in the browser
Output to MATCHES: list of matches
“the user can create a new match”: the user interacts with the MATCHES dialog in some way to open the dialog NEW MATCH.
This is no interaction involving the body of the application; it’s a pure UI interaction without involvement of application state; no slice is required. That’s why there is no circle in the middle of the arrow in the sketch.
Trigger on MATCHES: maybe clicking a button or selecting a menu item
“the user can create a new match”: this phrase has a second aspect to it. It also hints at an interaction with the NEW MATCH dialog to actually create the new match. This also leads back to the MATCHES dialog.
Input from NEW MATCH: title, names of players, number of games/player
Trigger on NEW MATCH: clicking a button
Output to MATCHES: updated list of matches
“the user selects a match from the list and gets displayed the list of games”: the user wants to “drill down” on a match..
Input from MATCHES: the Id of the match to show
Trigger on MATCHES: for example a double-click on a match
Output to GAMES: the list of games in a match
“From the list of games the user selects the next pending game”: the user want to call up a particular game.
Input from GAMES: the Id of the game to show
Trigger on GAMES: for example a double-click on a game
Output to GAME: the name of the player and the prompt for the first throw
“enter the number of pins knocked down. This continues until all throws have been made”: the user interacts repeatedly with the same dialog.
Input from GAME:
when continuing the game: the number of pins knocked down
when aborting the game: none
Trigger on GAME: probably clicking a button
Output:
to GAME: while game is not over: the prompt for the next throw
to GAMES: when game over or aborted: an updated list of games
This is so simple, it’s event boring: Increments as a long list of interactions.
But it’s effective: Each interaction is of value to the user by definition. They are natural increments. Because each interaction, each trigger shouts “I want this to be done!” When the user gets a button, a menu item or some other way to initiate action in an application, he attributes value to the resulting behavior of the software.
Slice-oriented design
But these increments might still not be as small as they could be, because each increment might consist of several requests. What is a single click for the user could best be encoded according to the CQS, with a sequence of commands and queries.
Hence, the next step in requirements analysis is to look even more closely at each interaction increment and identify the top-level requests to be issued, with each request to be processed by a slice.
This drill-down into requirements is already part of software design. It identifies and designs coarse-grained structural elements. It slices up the body of an application into distinct, independent parts—which can then each be implemented as a module of some sort.
Let’s start with a list of interactions:
Start application
Add new match
Open match
Start game
Register throw
Abort game
This is a breadth-first overview of all slice-relevant interactions. For progressing in an Agile way I should order the interactions according to value or “natural sequence” to the subsequent drill-down.
Most interesting, I guess, are “Start game” and “Register throw”. That’s the interactions the original kata revolved around.
What could be next? Probably “Add new match”, since matches are the “containers” for games.
In the end this is my prioritized list of interactions:
Start game
Register throw
Add new match
Start application
Open match
Abort game
If you think, the order should be different, that’s fine, too. The point is ordering for maximum value, not a particular order.
For each interaction now in turn I ask the question: “What requests is it made up of?” Does it require a query, a command, or both?
Before starting with the implementation I can do this refinement for as many increments I like. No need to do it for all of them. Better even to pick just a few or only one from the top to quickly move on to implementation and get feedback from the user.
Interaction “Start game”
A game is started when the user transitions from the GAMES dialog to the GAME dialog. One game in the list is picked and started.
But how can a game be picked if it hasn’t been started yet? Does a game exist before start maybe by planning it? Or are the games listed in GAMES only “suggestions” not existing yet?
The user cannot answer that question. His approach to software development is a phenomenological one: The user is only concerned with what she can experience/observe. Internal data structures she is not interested in.
In this case what she wants is: When a match is selected she means the application shows a list of games to be played. That way the players know when it’s going to be their turn. For example: the match “Christmas 2025” with players Peter, Paul, and Mary each playing 3 games would consist of these games: Peter #1, Paul #1, Mary #1, Peter #2, …, Mary #3. It would be 9 games in total. That’s what the user wants to see when opening a match.
Do these games already in the application state right after creating the match? They are just not yet started. Or is this list only generated for display from the match data, and a game “comes into existence” when started? For the user there would be no difference. It’s my decision as a developer.
Since I don’t want to look ahead and keep my focus only on the immediate as much as possible I decide there is nothing in the application state representing a game before its actually started.
What then are the requests behind this interaction? What data to pass with them, what data to receive back?
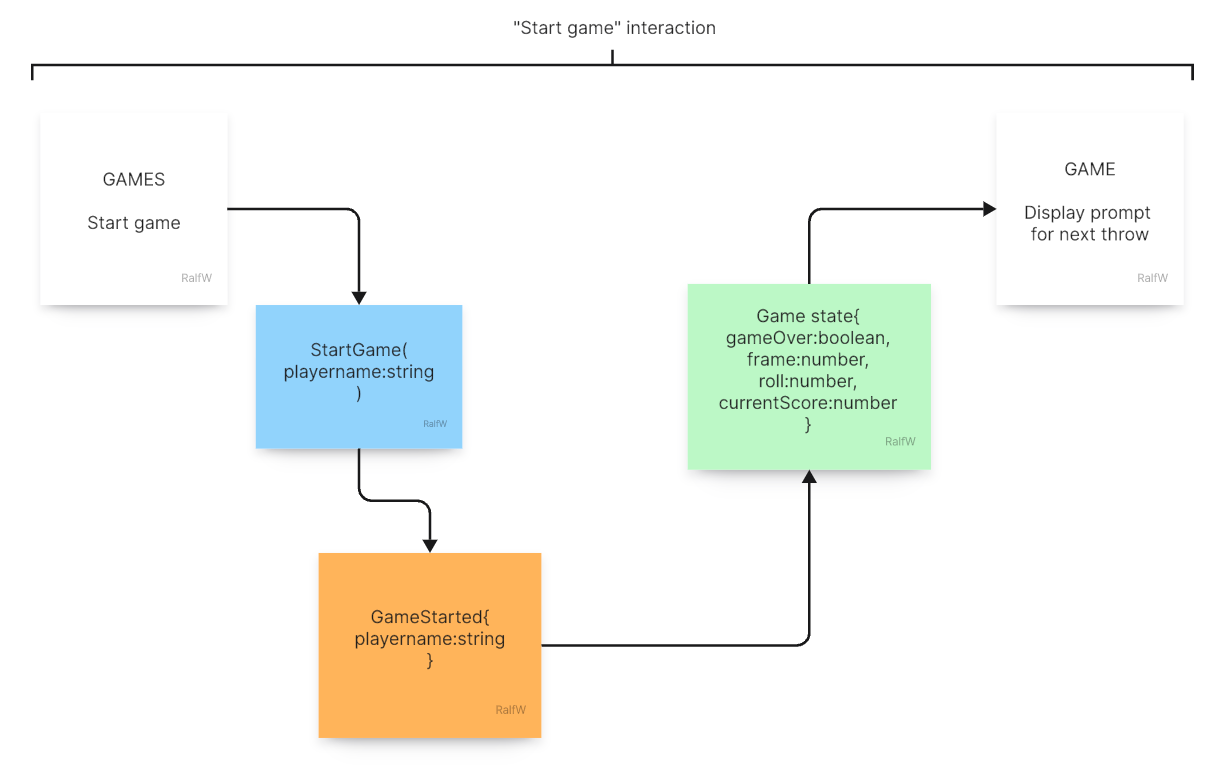
Command
StartGame(playername:string):{gameStartedId:string}: Starting a game obviously is a command. The state of the application is changed. Now there is a game running… Each game is played by a player who should be recorded with the game. And within the scope of the game more will happen; that’s what the id is for.Query:
GetGameState(gameStartedId:string):{gameOver:boolean, frame:number, roll:number, currentScore:number}: For prompting the player some information is necessary; at least the frontend should know if the game is still on or not. But according to the bowling rules the game advances in frames and throws/rolls. How far it has progressed at what the current score is, is the least the UI should show to the user. (Depending on the details of the user interface the query result could look different. For example it could contain a full list of rolls within their frames and indications of spares/strikes and bonuses.)
The id returned from the command hints at the user interface keeping local state. Also the short response from the query suggests, the user interface might keep some state. This of course is a developer decision. It depends on the kind of UI technology used and the user’s preference for information display.
For a first iteration with these two slices I don’t think a full blown GUI (desktop, web, or mobile) as envisioned by the sketch is necessary. Rather a terminal app will do to show the user, the project is moving forward.
For now the UI could be as simple as this:
$ ./bowling Peter↲
Started Peter's game:
Score: 0
Throw #1.1: 6↲
Score: 6
Throw #1.2: 3↲
Score: 9
Throw #10.2: 3↲
Score: 61
Game over!
$Also, here is an opportunity for more division of labor! With the request handlers’ signatures defined, different UIs could be set up in parallel. Work on the real UI with a GUI framework could start — but also a much more lightweight UI could be set up to quickly get feedback on functionality of the slices.
Now, what about the state changes the command should cause? As this is about event sourcing and AQ software cells there is no domain model. The entity is dead! It’s in opposition to productivity.

In an AQ software cell state is not stored in relational databases or NoSql databases with schemas mimicking some image of reality. State is all about facts, i.e. “things” happening aka events.
Events are generated only by commands and appended to the event stream. Which events then would/should StartGame() generate? What is known at this point in time when the interaction is happening?
I think it’s very simple: it’s a fact that a game was started for a certain player. That should be recorded.
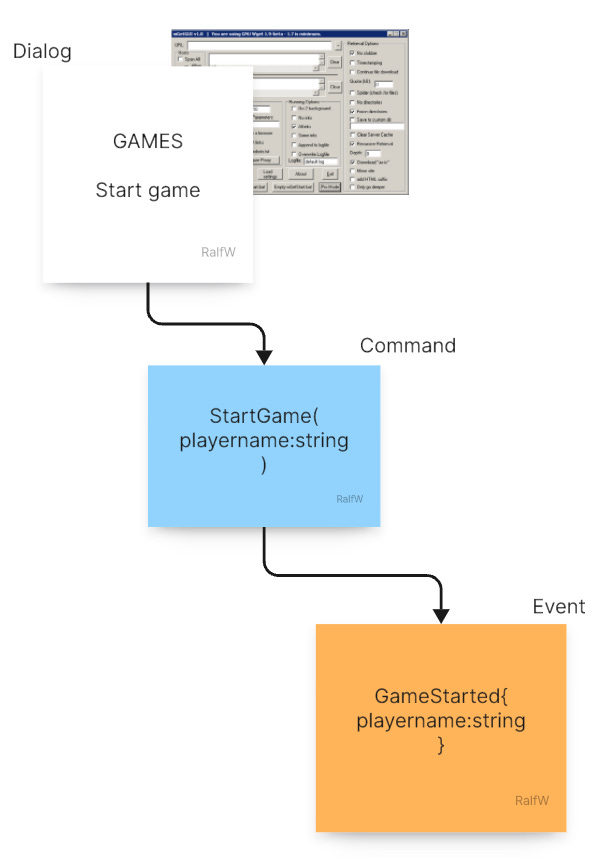
But else? Any additional events that come to mind when thinking about the command? What about the score? Should the game be started with a score, e.g. GameStarted{playername:string, score:number}? I don’t think a score should be part of the fact that a game was started.
But could it be an independent fact? It’s obvious at this point that scoring a game is the whole point of starting it. And the score will change over time. And it’s a matter of the current rules. If the rules change over time (domain logic) the score should not change.
So, how about a separate event to record the current score as a derived fact: ScoreUpdated{score:number}?
It’s a tough decision. I think I don’t know yet enough about the requirements and their implementation. So I stick with just one event.
Now on to the query. Which events does the query expect to return its result? Ah, there is a score — maybe a score update should be written? —, but for determining the current frame/throw more is needed. I think I have to postpone the fleshing out the query for a moment.
Interaction “Register throw”
The second command is about registering a throw. The player got prompted, rolled the bowling ball, knocked down some pins, and entered their number.
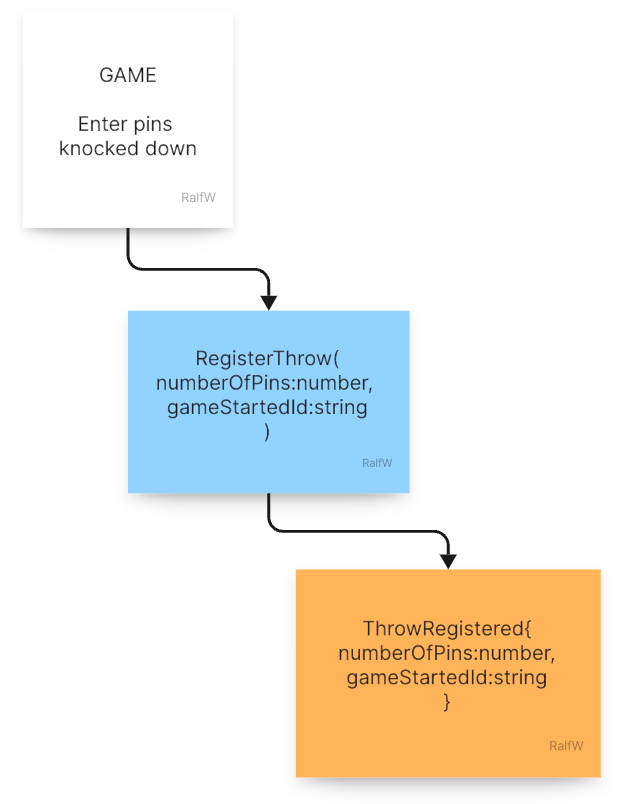
Command
RegisterThrow(numberOfPins:number, gameStartedId:string): The command records the fact of a certain number of pins knocked down during a game:ThrowRegistered{numberOfPins:number, gameStartedId:string}. The game is the scope here. That’s why thegameStartedIdis passed in. It’s the id of the event with which the game was started. All throws in the game belong to it. They happen inside its scope. The game is like an umbrella spanning all throws. A throw only makes sense as part of a started game.Query: Part of the interaction is the same query as in the previous one. After a throw got recorded the game continues with a next throw (until it’s over). The player needs to get prompted again.
With two events in place are there enough facts for the query to work? After a couple of commands the event stream could look like this:
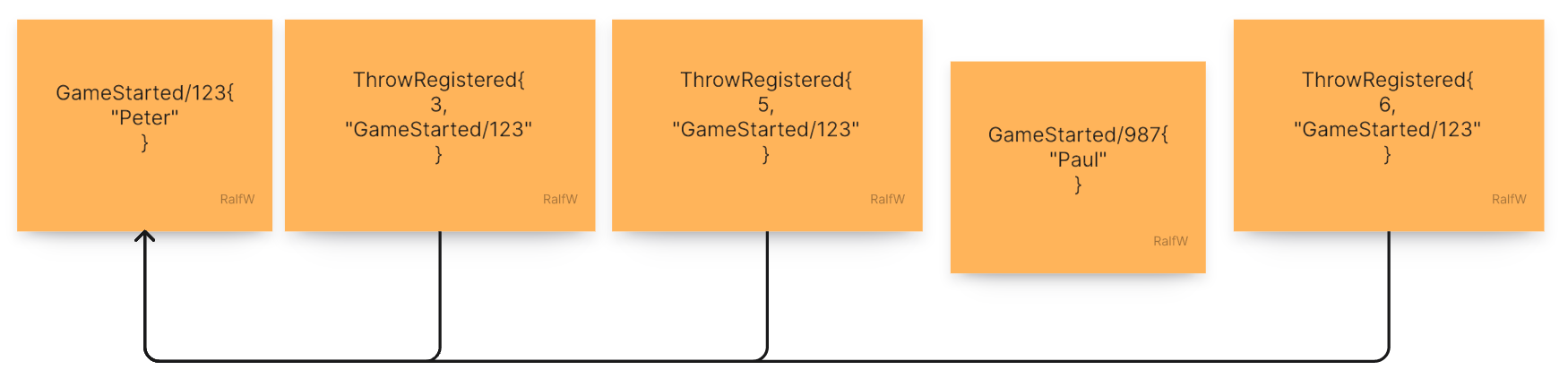
Two games have been started.
Three balls were rolled in the first game.
Could a query determine from this the next number of the next frame, next roll, and the current score? Yes.
So, what about an event to store the score of a game? Should that be written after each throw? That’s not necessary for the query. But it’s certainly worthwhile at the end. Because the end of the game signifies a state change of a game; it’s a “lifecycle event”.
If the end of a game is detected, a closing event is in order, e.g. GameFinished{score:number, gameStartedId:string}. Of course this event is part of the scope of the game, too.
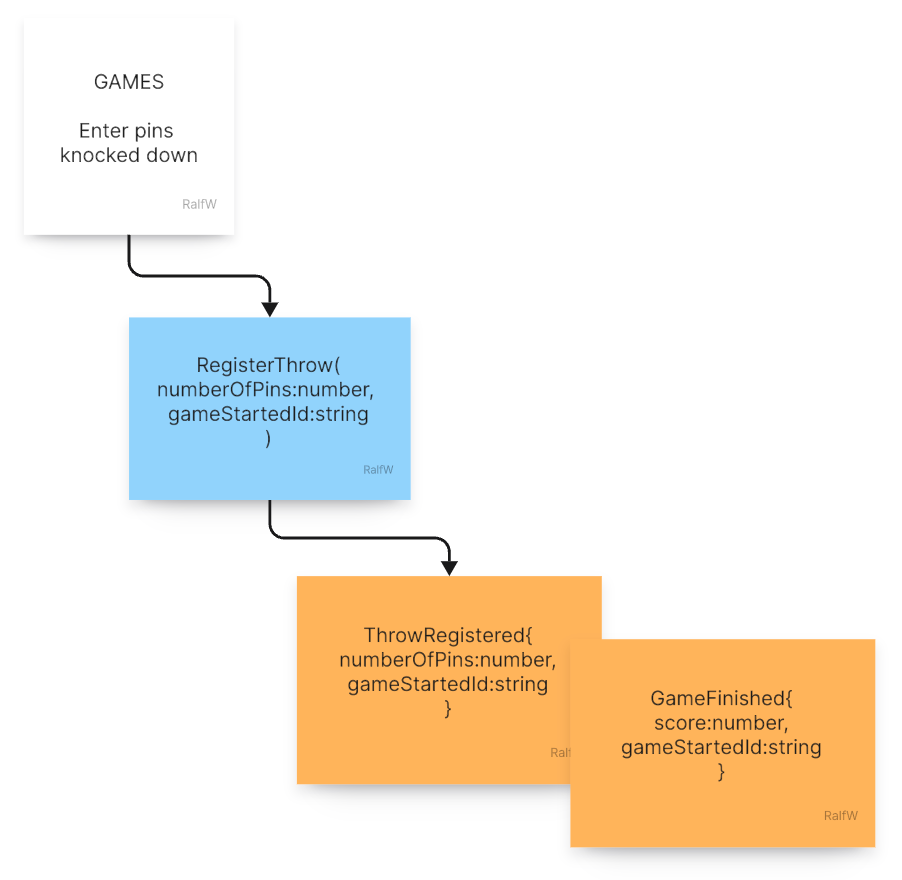
With this event the scope of a whole game would look like this:
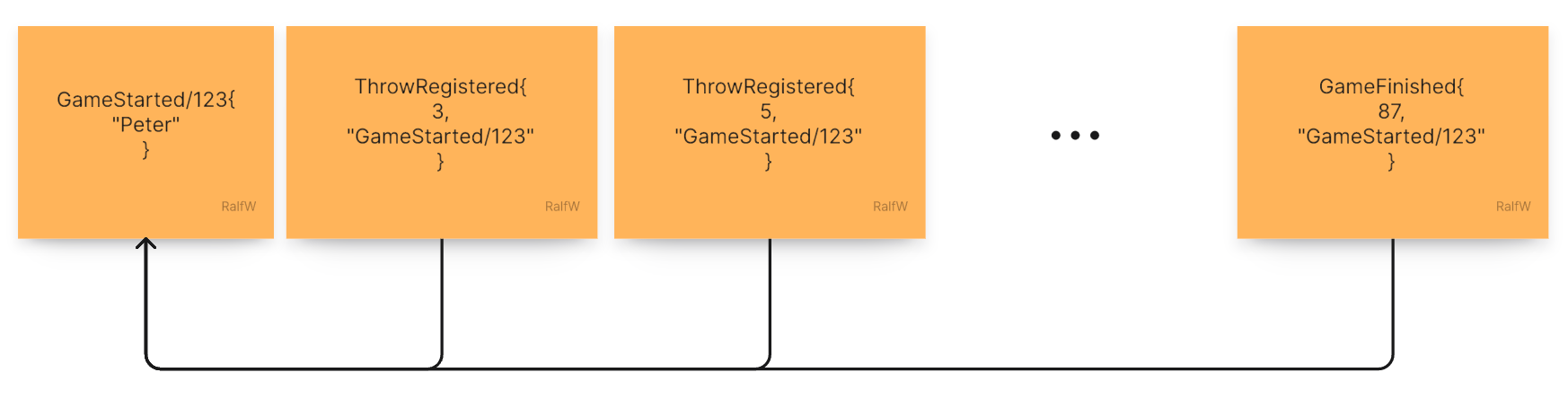
However, to be able to generate the GameFinished{} event, the command has to know the game rules and check if the current throw was the one ending the game. The command has to know about frames, spares, and strikes.
Likewise the query has to know about frames, spares, strikes to generate info for the prompt.
Does that mean the game rules should be implemented in different slices in parallel? Or does it mean both slices should share a code? Or… does it mean even more events should be generated by the command to lighten the burden of the query?
Or… — yes, there is another option — shouldn’t the GameFinished{} event be issued by the RegisterThrow() command, but another command?
The command for registering a throw can straightforwardly issue the ThrowRegistered{} event. It’s the external fact it’s supposed to register. But GameFinished{} is different; this event is not easily derived from a roll. Even though it’s a pretty obvious event, it’s not external. It only happens if a domain rule detects a certain condition. If and only if the end of the game has been detected based on all rolls made so far, the GameFinished{} should be issued.
Imagine a referee checking the list of rolls made after the current one has been recorded. If the referee came to the conclusion, the game is over, he/she would command the application to change its state accordingly.
You see where I am heading?
I am separating the generation of the events ThrowRegistered{} and GameFinished{}. There should not be just one command for both, but two, with the new one being FinishGame(score:number, gameStartedId:string). These commands should be handled in sequence. The interaction is triggering a process with several steps:

Dividing the responsibilities this way relieves the commands from checking game rules. Only the query needs to know how a score is calculated, or how frames are counted, and the end of the game is determined. The query is assigned the referee role, so to speak.
This way no code needs to be duplicated, no code needs to be shared between slices, no additional events are necessary!
The whole arc of the interaction starts at the GAME dialog, spans generating and querying events, and ends again in the GAME dialog (at least as long as the game is running).
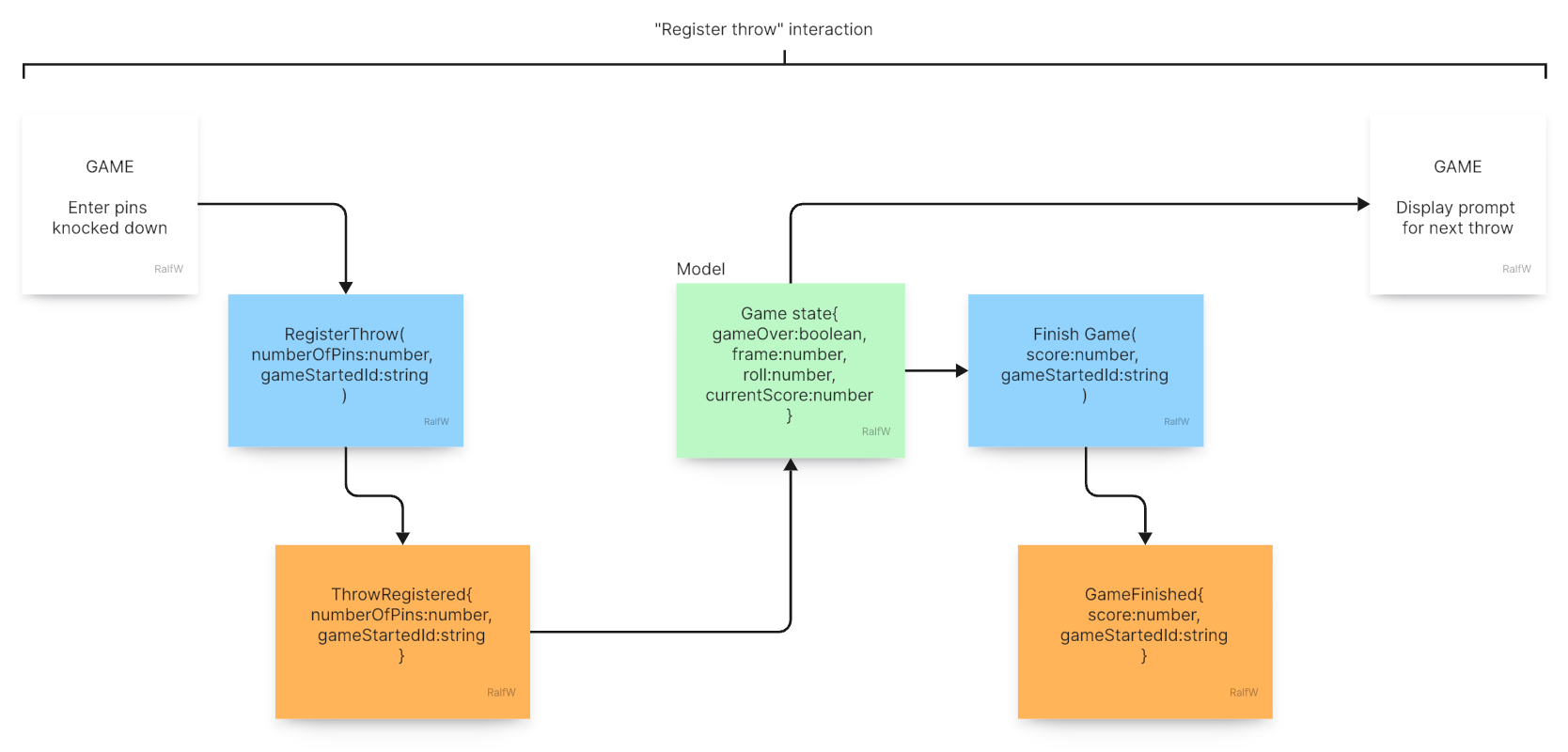
Notice how a command leads to events, and events contribute to a model. This model is local to the slice. It’s the result of the query and (partially) used as input to the second command as well as response to be displayed in a dialog.
The open question for the GetGameState() has been answered. This also finalizes the “Start game” interaction; it’s obvious, the query has not much to do if a game just has been started and no rolls have been registered yet.
The query works on all events in the scope of a GameStarted{} event.
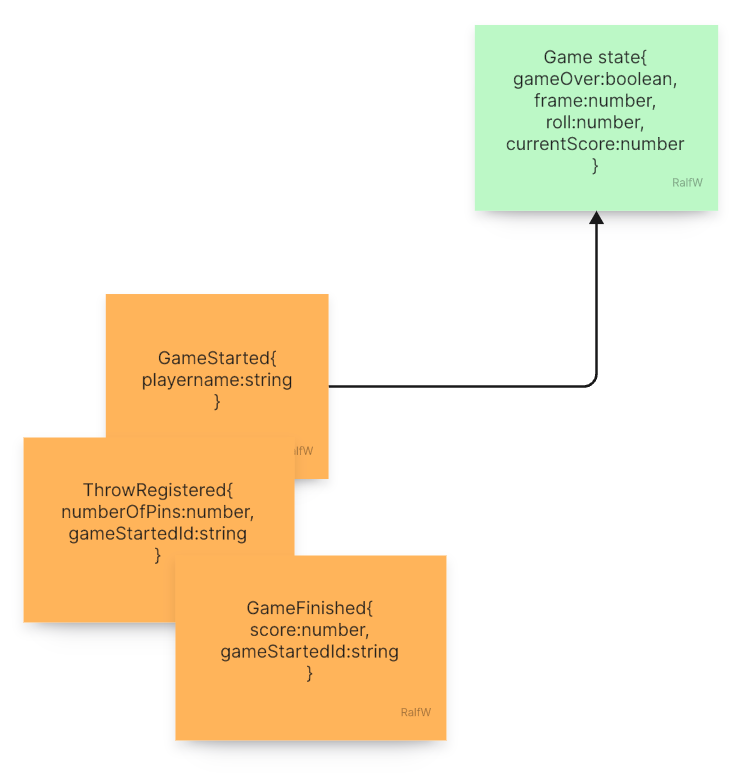
How the query does that, I don’t know yet. But I am confident, these events are all that’s needed for the query to build the model from.
Interaction “Add new match”
So far the application does hardly more than is described in Robert C. Martin’s kata. Matches, though, go beyond that. Matches tie games together into a larger whole. Games are started as part of a match.
The interaction to create a match consists of two requests, I guess:
Command
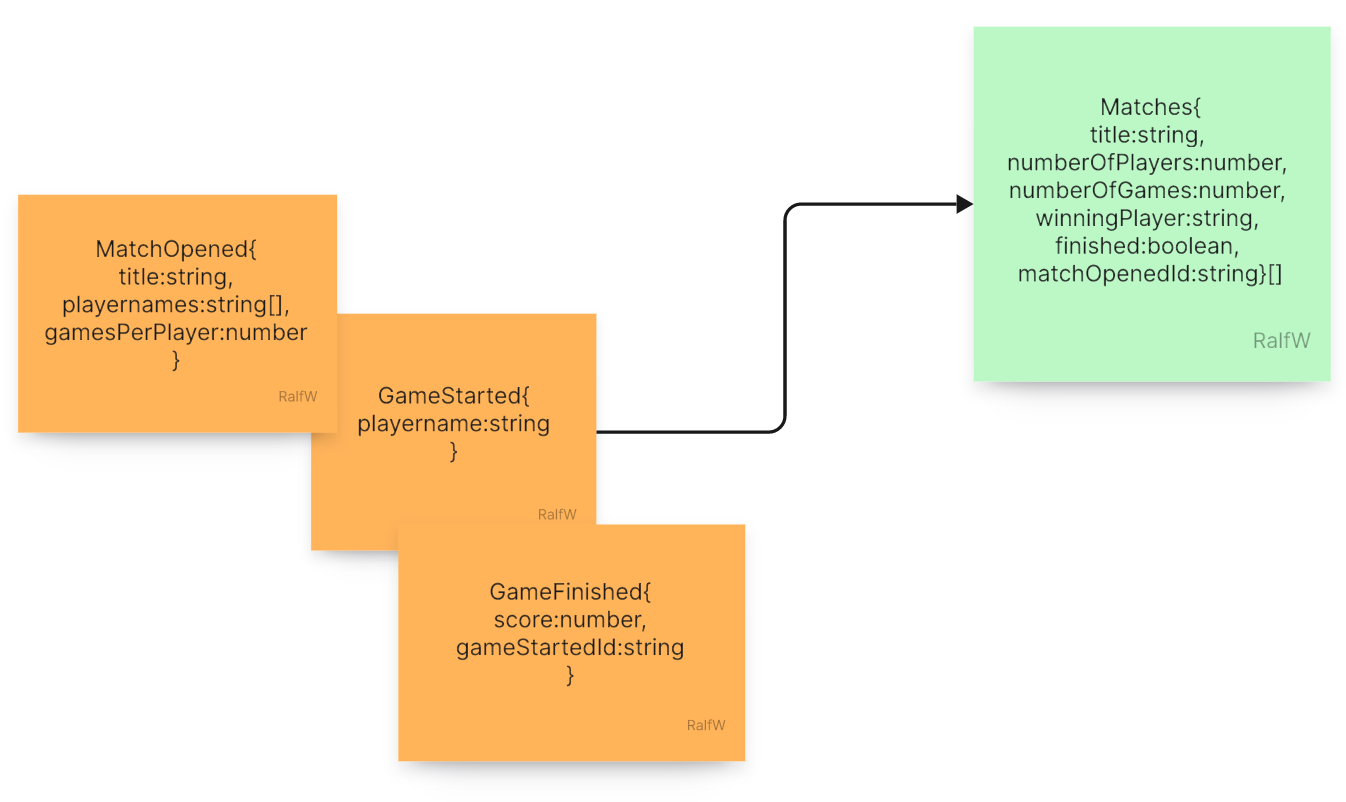
OpenMatch(title:string, playernames:string[], gamesPerPlayer:number):{matchOpenedId:string}: The match is set up with a number of players each playing the same number of games. The games themselves are not yet started, though. This happens only on demand (see interaction above). A constraint on this command could unique player names.Query
GetMatches():{title:string, numberOfPlayers:number, numberOfGames:number, winningPlayer:string, finished:boolean, matchOpenedId:string}[]: After adding a new match, the list of all matches is retrieved for display.
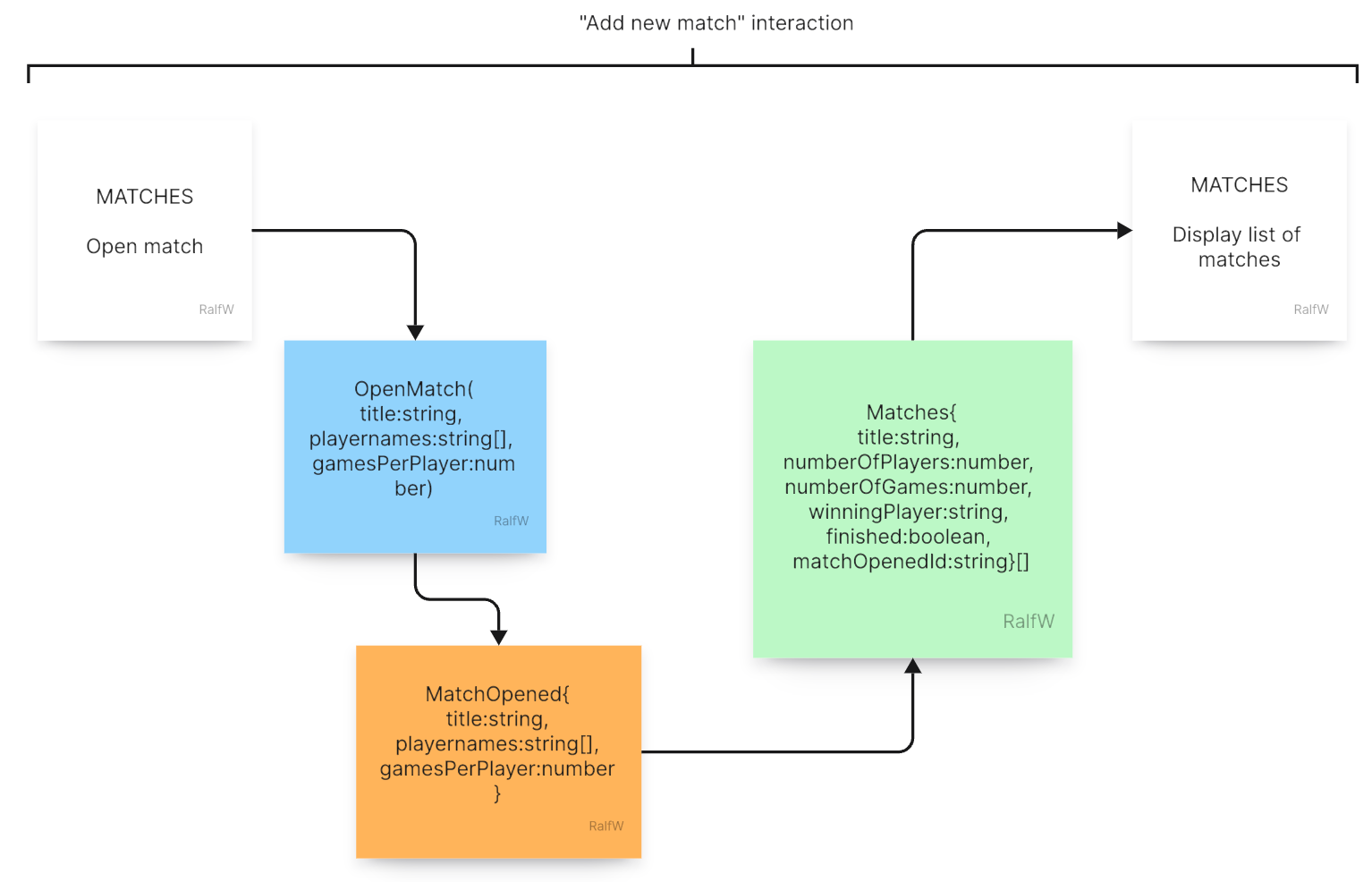
The command itself only generates a single event for the fact that the match was opened. The query works with that as well as game events. Game events happen within the scope of a match.
But I guess, it makes sense to explicitly close a match after the final game was played. It’s a life cycle event like when a game finishes.
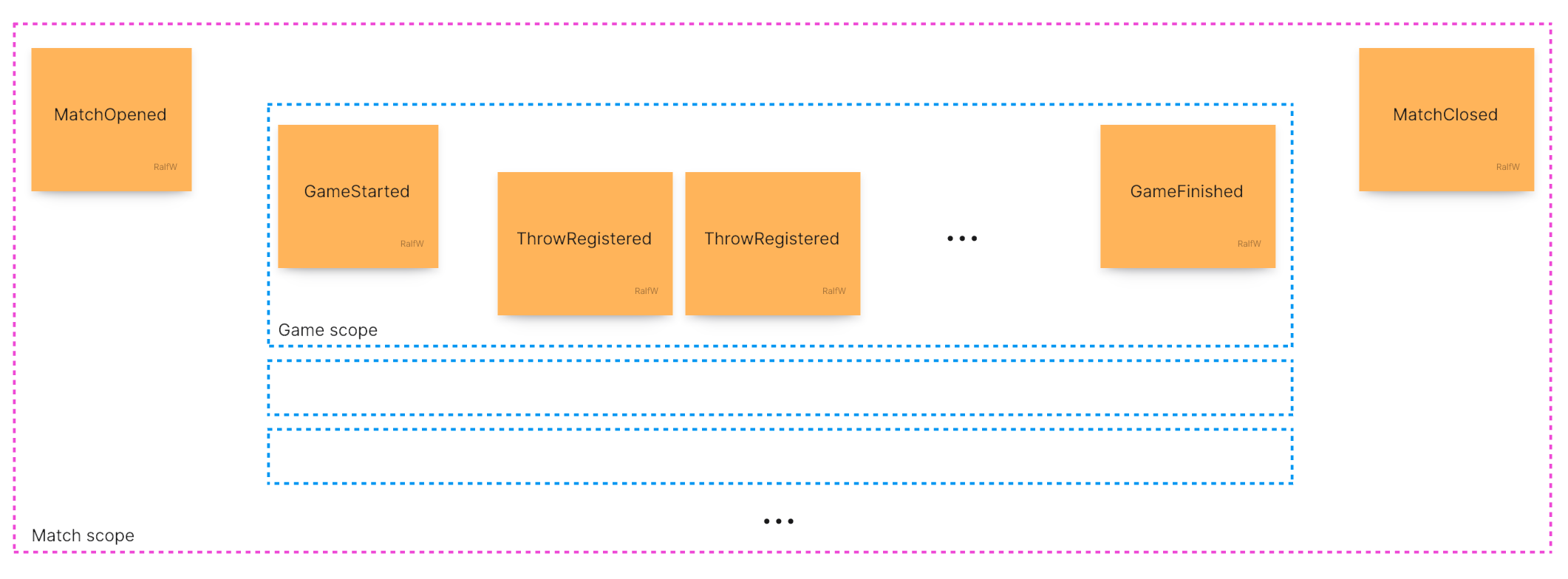
This requires some adjustments to how games are handled:
Each game starts inside the scope of a match; it needs to know the match’s id to reference it as its scope root:
StartGame(playername:string, matchOpenedId:string):{gameStartedId:string}
Whenever a game is finished it needs to be checked if this also closes the match because it was the last game to be played. For that at least an additional command is necessary, e.g.
CloseMatch(matchOpenedId:string, winningPlayername:string). But where does the name of the winning player come from? The command should not be burdened with that kind of domain logic. A query preceding the command is required to answer the question, e.g.CheckIfMatchIsFinished(matchOpenedId:string):{finished:(“open“|”closed”|”toBeClosed”), winningPlayername:string}. Only if the match hasn’t been closed and is finished it should be closed (“toBeClosed”).
This extends the process inside the “Register throw” interaction.

Wow, so much happening in one interaction? Yes, I think, it makes sense. Here is where “the domain rules”. Here is where most external facts (throws happening) are recorded and consequently internal facts created.
Please note: For this process to work, no cross-slice or cross-interaction models are needed. It’s just about local models flowing through the process. Or maybe I should call the interstitial models? Because they are filling gaps between slices?
Let me stop here my interaction refinement. Three interactions with several slices are piling up; I think I need to start implementing them to get some feedback from the user and get a feel for my understanding of the requirements for mapping to slices.
Slice-driven implementation
I won’t be able to go into every detail of the implementation. You can check it out in my Github repo here. The event store implementation it’s using is this (open source for Postgres and in-memory).
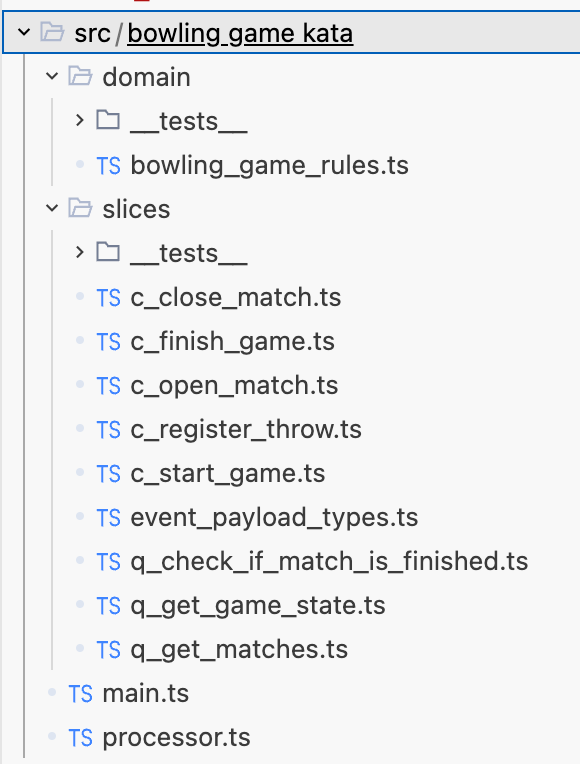
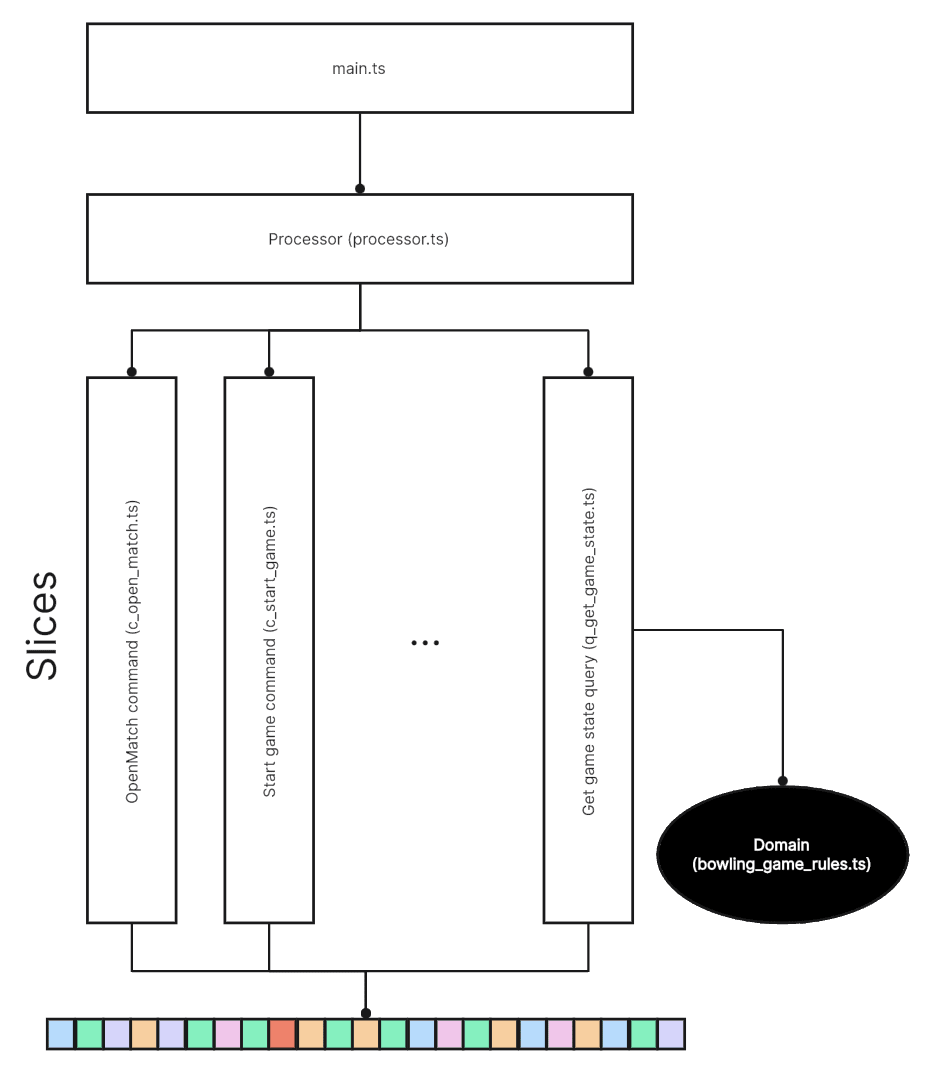
As you can see, most of the modules are dedicated to slices: for every command and every query there is a file.
Some slices (queries, to be precise) are not self-sufficient. They call domain functions in a separate module, e.g. for calculating the current game score. All domain functions are pure functions.
Then there is an integration module —
processor.ts— actually implementing the interactions. Each interaction consists of one or more slices.Finally,
main.tsis where the interaction happens. It’s a console implementation of the UI calling theProcessor.
Each slice is implemented as a class injected with the event store, e.g.

Notice the simple, very regular structure of the command slice:
First the events for the slice’s relevant part of the application state are pulled from the event stream. Each slice only is concerned with a small section of the overall state. That’s the context of the slice.
The context then is projected into a model, the context model. It’s a data structure specifically designed just for this slice. It does not have broader relevance. It’s not shared with other slices. (At least not initially. Maybe at some point a pattern appears and multiple slices can share the same context model. Just maybe.) A context model can be anything from a single value to an intricate large object graph.
The context model is checked for some constraints. Or maybe some data gets calculated based on it and the command’s parameters.
Finally new events are appended to the event stream. If need be this can be done in a conditional way (conditional append for consistency’s sake).
For an extended discussion of this structure see:

Commands and queries are integrated by the Processor into interactions. It hides the details of composing slices into workflows. To its client it presents a clean interface without any trace of event sourcing. As an example the “Register throw” interaction (sorry for the rename to “throw pins” in the code).

The designed flow of commands and queries is retained in code (with some added case distinctions).
Slices are not sharing any stateful data structures; all are just connected to the event stream and create on-demand whatever they need. But they are sharing small data structures in the flow to be handed downstream. Example: A gameState is created in the second line of the interaction and used subsequently as input to other slices. That’s an example of the application of the Principle of Mutual Oblivion (PoMO) which is at the heart of object-orientation according to Alan Kay, its inventor.

Command are purposefully kept small. Domain logic is run in queries. But it’s not necessarily part of the slice. That would be overburdening the slice. Rather the domain logic is separated out into a module of its own. As a pure function (see also functional core, imperative shell) it’s easy to test. As an example see the GetGameState query:

Testing a pure function (domain logic or other) is easy. But testing slices is easy, too. Even though they depend on a “database” — the event store —, no database has to be set up or kept around for testing slices.
Since an event store “database” is so easy to implement it can be kept around in two versions: a persistent one for production and a functionally equal one working just in memory. The latter one can be used for testing where it’s populated inside the test with the events needed to check the system under test. See this example from testing the GetGameState query:
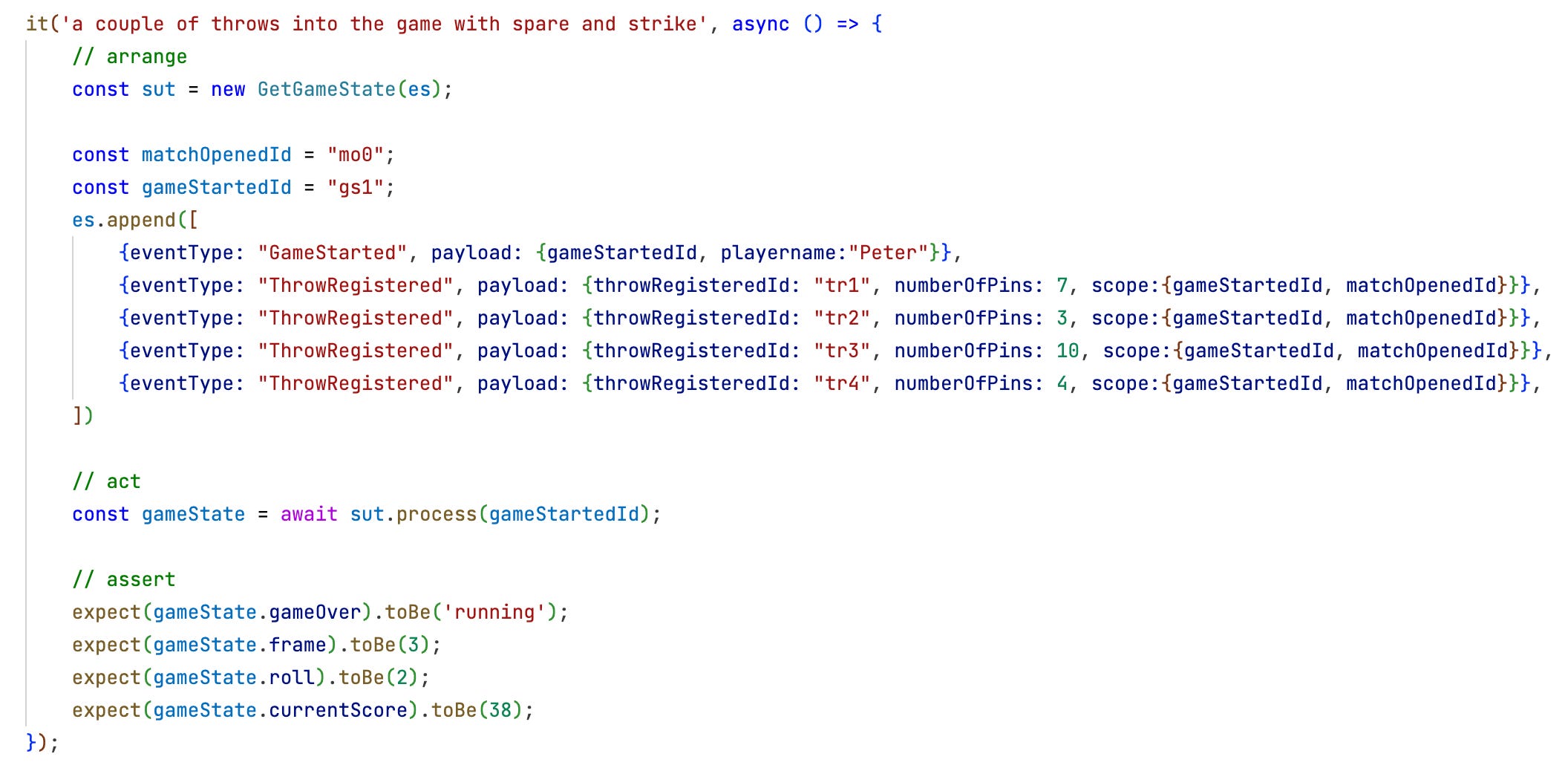
As part of the arrange section of the test the in-memory event store is filled with a couple of events the system under test (sut) is expected to produce a result from.
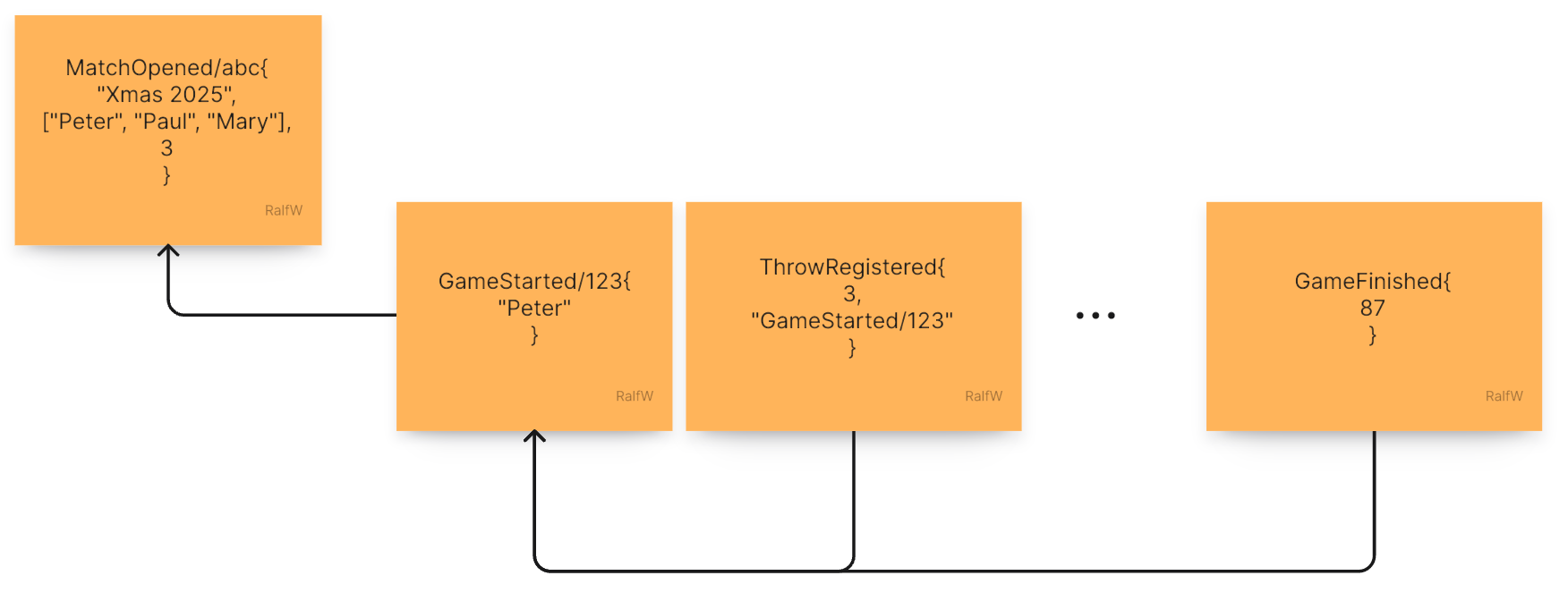
Since here the structure of an event is sticking out let me quickly explain how scopes are implemented. Remember: Each event can be the root of a scope, i.e. a “space” containing related events. Above the GameStarted event is opening such a scope. But that does not have to be planned; it’s a matter of subsequent events like ThrowRegistered. If they refer to an upstream event, that event “retroactively” becomes a scope root.
In order to reference an event each event gets an id, e.g. gameStartedId. The event’s id is part of the payload. It’s not a matter of the event store. There is nothing special about an id. It’s effectively optional. But if present, it can be used to link back to previous events.
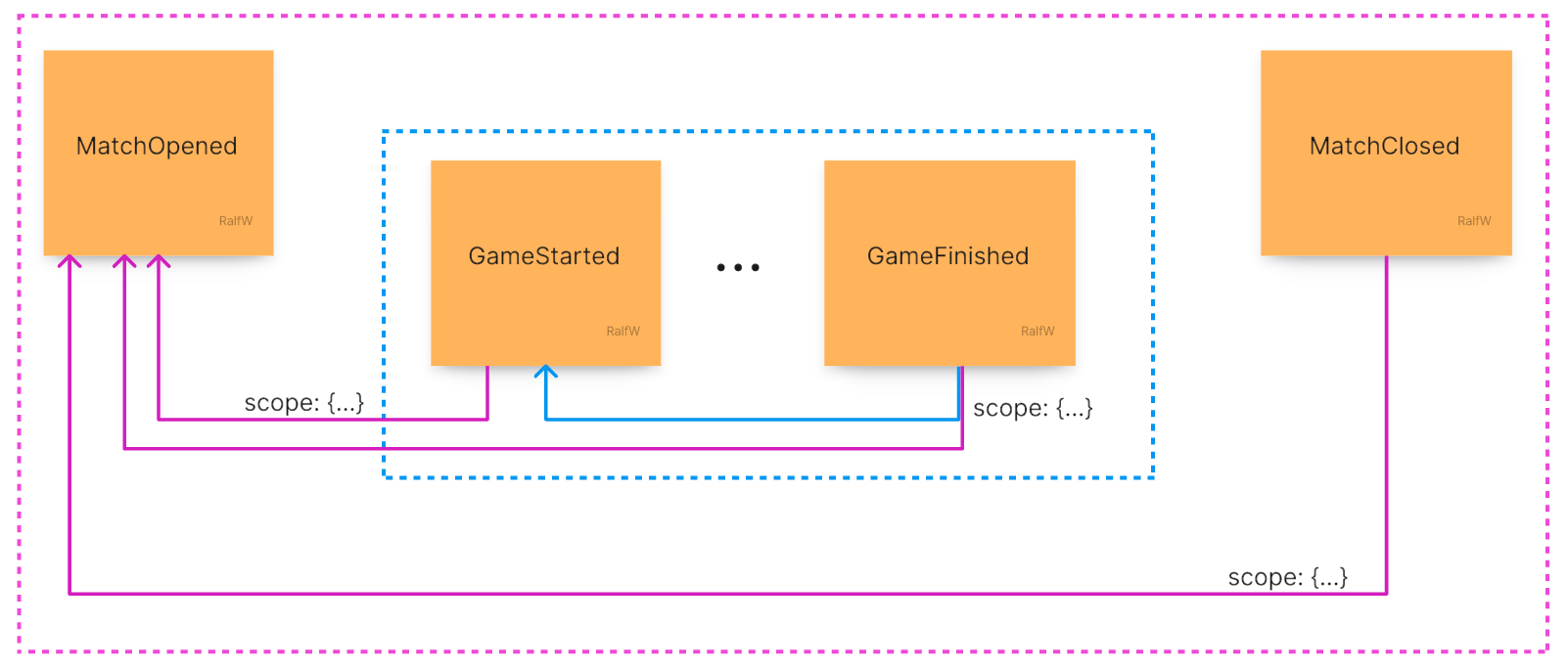
Such backlinks are put into the scope section of the payload. In that section all scope roots are referenced with their id. That way a query can retrieve events on all levels of scopes. Here is an example:

The opening bracket of a match is MatchOpened. GameStarted as well as MatchClosed are referring to it as the scope root by putting its event id into their scope in their payload: scope: {matchOpenedId}. This is queried for when retrieving the context for checking, if a match should be closed.
GameFinished, though, is not directly part of the MatchOpened scope. Its scope root is GameStarted which is creating a nested scope. Nevertheless GameFinished is indirectly part of the MatchOpened scope. That’s why it too includes matchOpenedId in its scope and can be queried for like GameStarted.
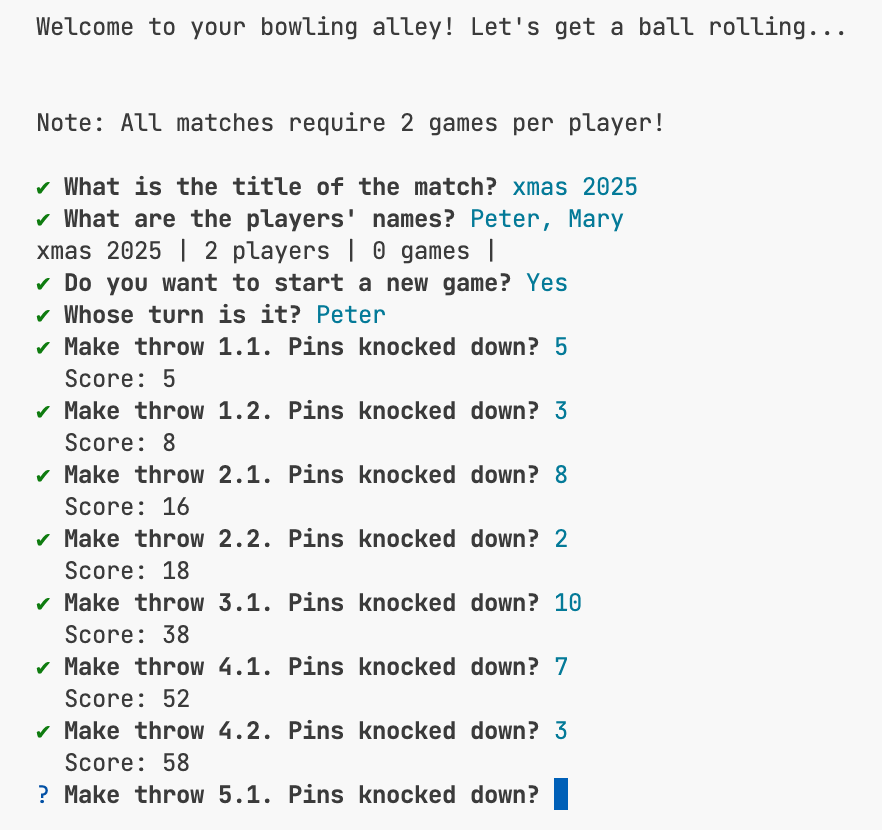
From the depth of the code back to the surface: The user interface is very simple. It wasn’t the focus of the implementation. Based on the same Processor more elaborate user interfaces can be built easily.
Conclusion
Again I am surprised by the flow of project. It’s so easy, it’s even boring. The fun is in the domain — where it’s supposed to be. All else… is just one increment, one slice after another.
The lack of a single, central data model might feel strange for a moment. But it really helps to focus. Just look at what’s needed for the slice to be implemented right now:
What’s the context? Which events are relevant?
What’s the best shape for the context model?
What to produce as a result? Which events to write by a command, which response model to project from the context model by a query?
Concentrate on one slice after another and get things done. Application state management won’t get in your way anymore. That’s a great relief!
I can only say: I don’t miss the intricate object graphs of mainstream object-orientation. I am perfectly fine with “anaemic objects”. Their relevance is very limited; their existence temporary.
That said: The AQ software cell and slicing are open to whatever appears to be better. If you spot patterns in your slice in which events are pulled into a context or how a context model looks or what operations are run on a context model, then by all means extract those patterns for slices to share their implementation.
Yes, that’s effective reuse — but not as a premature optimization. It’s reuse born from experience where it actually makes a difference because the demand is proven. That kind of evolution of code to me is organic.
Now it’s your turn! Give the AQ software cell with event sourcing and slicing a spin! The structure is trivial. The process is simple. You can do it!

If you don’t store events as JSON that’s fine, too. I’m using JSON here just as an example; it’s universally understood as a data format and supported by many database engines. But of course you could use XML or YAML or whatever you like to encode/store your events.
This is great for multi-tenant applications. Instead of adding tenant information to a database schema in multiple places, you can just create an event stream for a tenant. Tenant A appends all events to stream A, tenant B appends all events to stream B etc. That way tenant data is easily and naturally separated.
There might be cases where for performance reasons a separation of changing and reading state should be avoided. But they are rare in my experience.