
IODA Architecture
Decoupling concerns even more by getting rid of functional dependencies

The common software architecture patterns MVC, layered architecture (LA), Hexagonal Architecture (HA), Onion Architecture (OA), and finally Clean Architecture (CA) are all doing basically the same:
They separate concerns they deem fundamental to software.
They define the relationships between those concerns.
The purpose of this is to save programmers a discovery process. They speed up the software development process by suggesting to start with a tried-and-true basic structure which has turned out to be beneficial for many projects before.
Nevertheless, as it’s obvious, even the image of “tried-and-true” changes over time. What was “best” in the 1970s (MVC) was not good enough anymore from the mid-1990s on (layered architecture). And that was superseded by yet another even better pattern (Hexagonal Architecture) etc.
But the pattern behind the patterns stayed the same: concerns related in a particular way.
Concerns
The Separation of Concerns (SoC) principle is foundational to software development. It states, that the logic of a program should be aggregated in distinct modules:
“A program that embodies SoC well is called a modular[1] program. Modularity, and hence separation of concerns, is achieved by encapsulating information inside a section of code that has a well-defined interface.” (Wikipedia)
Each module focusses on a particular “topic” — thereby giving its logic high cohesion — and is separated from other modules by a clearly defined “wall”, an interface — thereby decoupling modules from each other.
But which kind of logic to gather in modules? What should be the “focus”, the “objective” of the modules be? Architectural models differ in detail in that regard:
HA suggest only two kinds of modules: core and adapters.
MVC suggests three: model, view, and controller.
CA recommends five: entities, use cases, controllers, gateways, presenters.
This might seem confusing, however, there is a pattern behind the patterns: they all separate at least peripheral concerns — i.e. communicating with the environment of a software system — and core concerns — representing the purpose of a software system.
Peripheral concerns are called for example adapter (HA) or view (MVC) or persistence layer (LA) or presenter (CA).
Core concerns are called core (HA) or model (MVC) or business layer (LA) or entities and use cases (CA).
Relationships
By defining which concerns should be separated (at least) the patterns are putting building blocks on the table. As an example here are those of the LA:
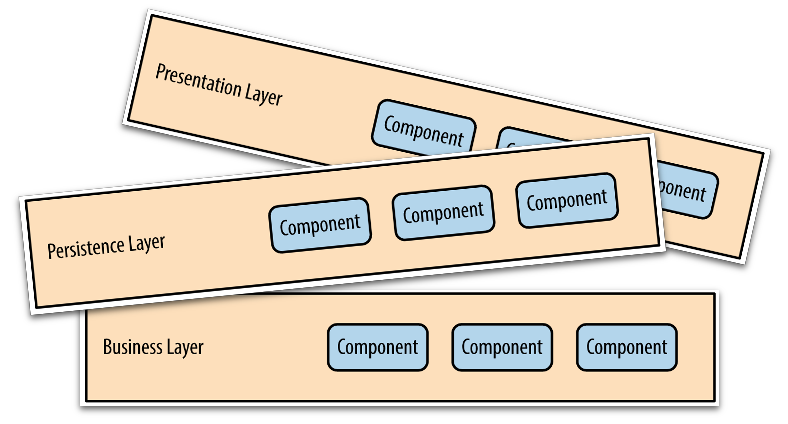
But what to do with them? Only all together cooperating will make a working software.
That’s why the architecture patterns also define the relationships between these building blocks. They connect them in usage patterns which are often visualized with arrows:
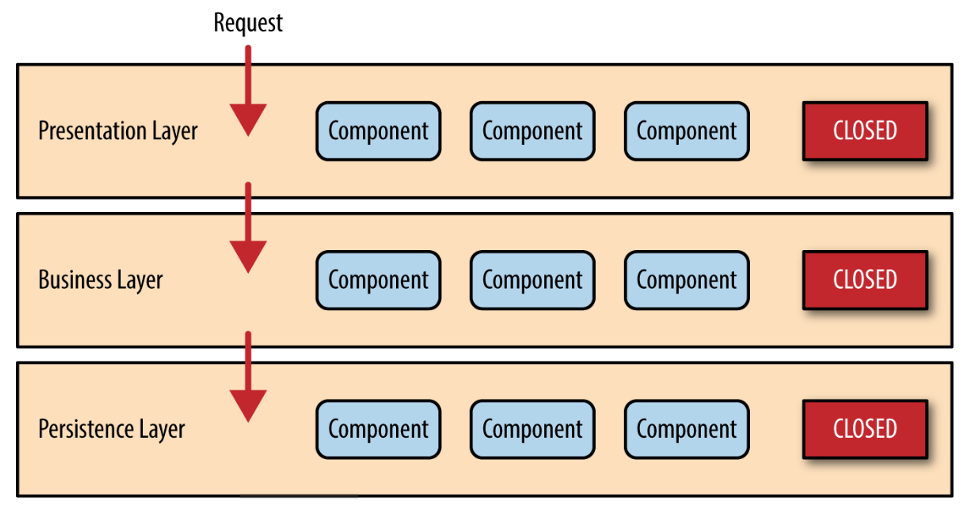
The arrows point from the using/dependent concern to the used/independent concern. Requests flow along the arrows, responses in the opposite direction. At runtime that means a requesting module calls a function on the responding module.
Arrows are obvious relationships, but can feel not very compelling. Or can be drawn all over the place making a mess. That’s why later architecture pattern diagrams try to avoid them by making them implicit. The HA was the first in that regard. It used a concentric arrangement of concerns and declared dependencies to “flow from the outside to the inside; only outer modules must depend on inner modules, never the other way around.
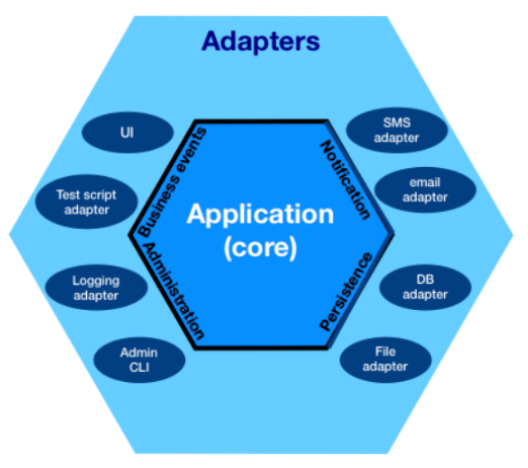
This change in depiction isn’t terribly important, though, as it turns out. Just a visual simplification/clarification.
What’s much more important is a differentiation of relationships that occurred some time in the late 1990s.
Design Time Relationships vs Runtime Relationships
Relationships between modules can be of two kinds. One kind is the obvious one: the usage or call relationship. Which module may call a function from which other module? That means, which module depends on which other module at runtime?
Example from the LA: the business logic layer calls the persistence layer at runtime to read or write data. A calling module thus cannot do its job without a called module. The calling module’s logic depends on the called module’s logic.
Architectural patterns have done a great job in disentangling such runtime relationships. They straightened them out to run only in one direction. They made it clear that circular dependencies must be avoided at all costs.
However, runtime relationships are posing a problem to testing. How to test the business logic without also testing the persistence logic which gets called by it?
Here’s an example: Even the trivial lines of business logic inside the business layer function cannot be tested without also calling whatever logic is inside the persistence layer function Load.

If an unexpected result is returned, it may be hard to determine which module the culprit is. Even worse, a test would require a whole database to be put in a defined state as input to the business layer function through the persistence layer.
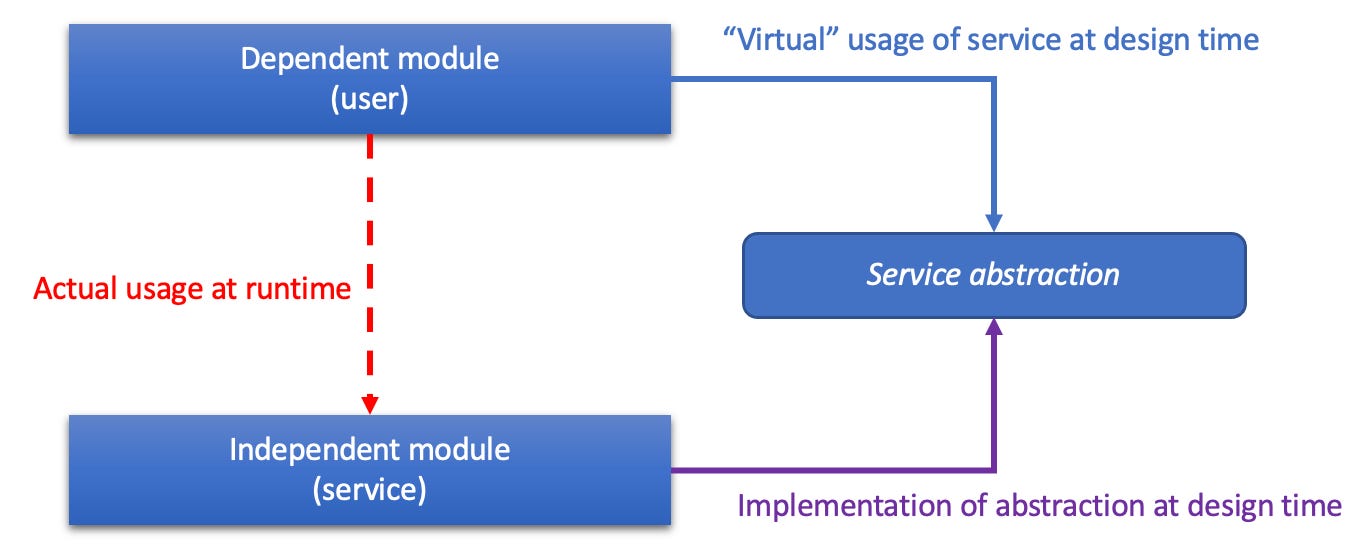
This is why since long dependencies on implementations have been warned against. Instead a using module should do the following:
Depend only on an abstraction of an implementation of a used module, e.g. an interface (Dependency Inversion Principle (DIP)).
Not instantiate a particular implementation, but get one handed from the outside (dependency injection).
Amended example:

The business layer is still using some data source, but now does not know anymore which kind exactly. Maybe it’s a persistent data source, maybe something else. As long as the data source implements the interface IDataSource all’s fine from the point of view of the dependent business layer.
What the code shows is only a design time dependency. At runtime things become more concrete:

The class PersistenceLayer implements IDataSource and is instantiated and injected into an object of the business layer. That way, during a test a special kind of data source could be used to avoid running real persistence logic:

In summary: The design time relationship is always the same, but the runtime relationship can change. That’s the flexibility needed in order to be able to test dependent modules.
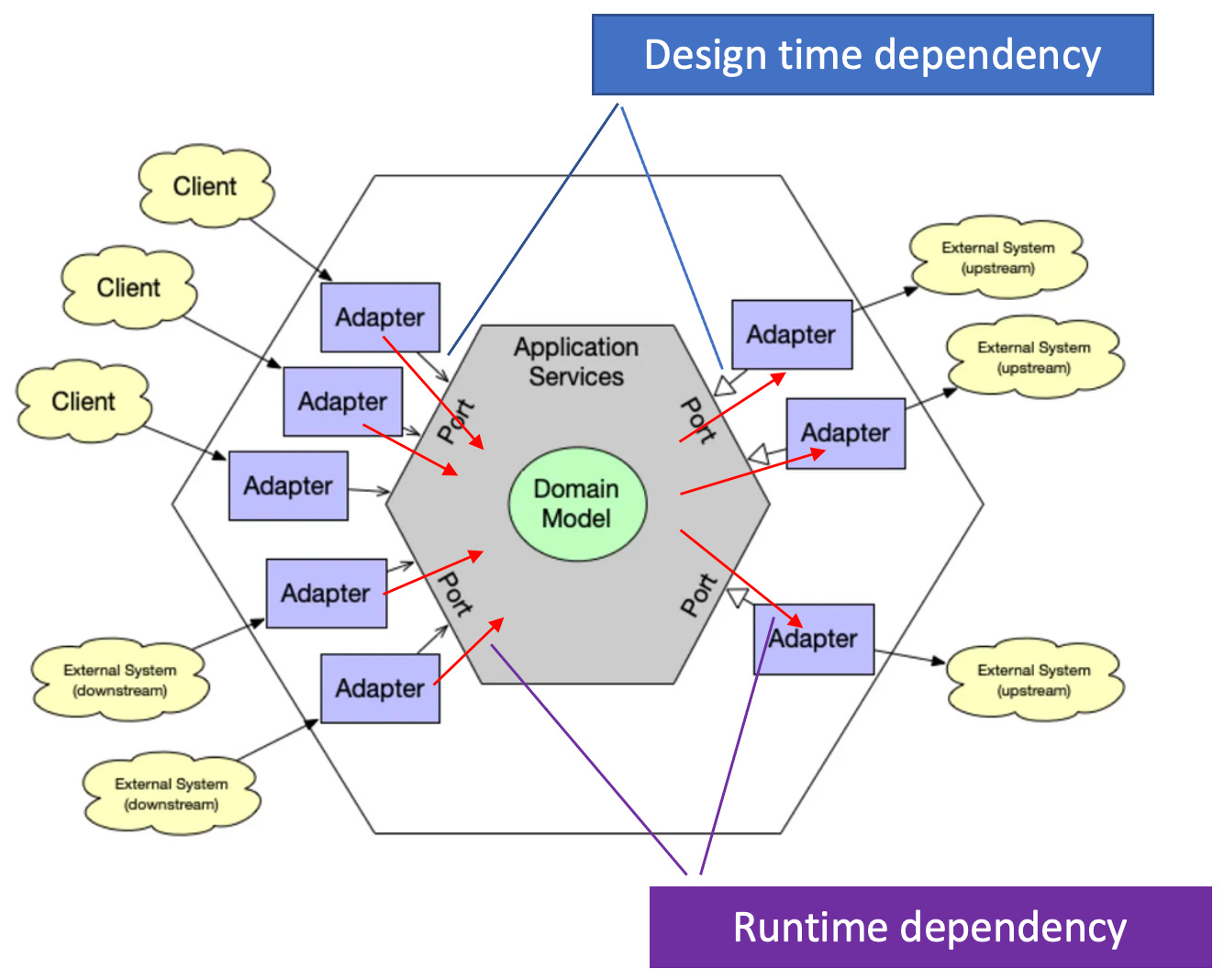
What does this differentiation mean for the architectural patterns? They need to be clear which kind of relationships they define. And the answer is: they are all about design time relationships. Well, at least from the HA on, that’s the case.
Here’s a more detailed depiction of the HA now with arrows:
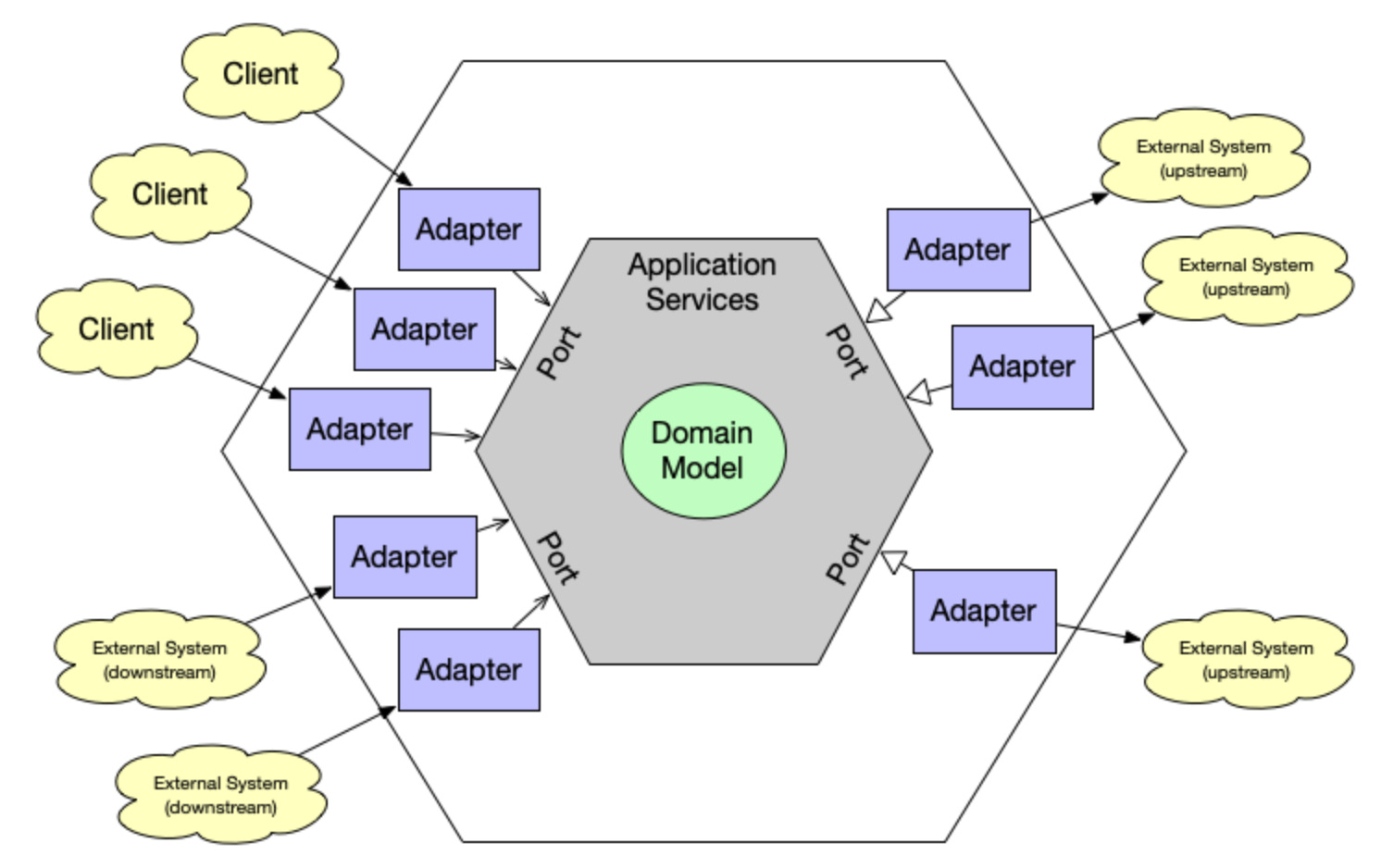
As expected, all arrows are pointing inwards. Outside modules depend on inside modules only.
But the type of arrows reveals that they are about design time relationships:
On the left side it’s simple arrows from adapters to code signify a usage relationship.
On the right side, though, it’s arrows signifying implementation of an abstraction. The right side adapters are not (!) using the core, but only implement an interface provided by the core.
It’s true, the relationships are clear and non-circular in the architectural patterns. But even in the modern ones they are still pointing from “frontside” interaction surface (user interface, frontend, presentation layer) to “backside” (database adapter, persistence layer etc.) while going through the core (domain, business layer). Nothing much has changed with respect to the runtime view.
But an indirection was introduced and for good reasons: to increase testability and changeability.
It’s About Who Owns the Abstraction
The DIP is not all that new, though. It was already in use while the LA was in favour. So, why all the fuzz about HA or CA? It’s about who owns an abstraction. Which concern actually defines what an interface should look like?
In the days of the LA it was usually the service, the independent module which implemented it:
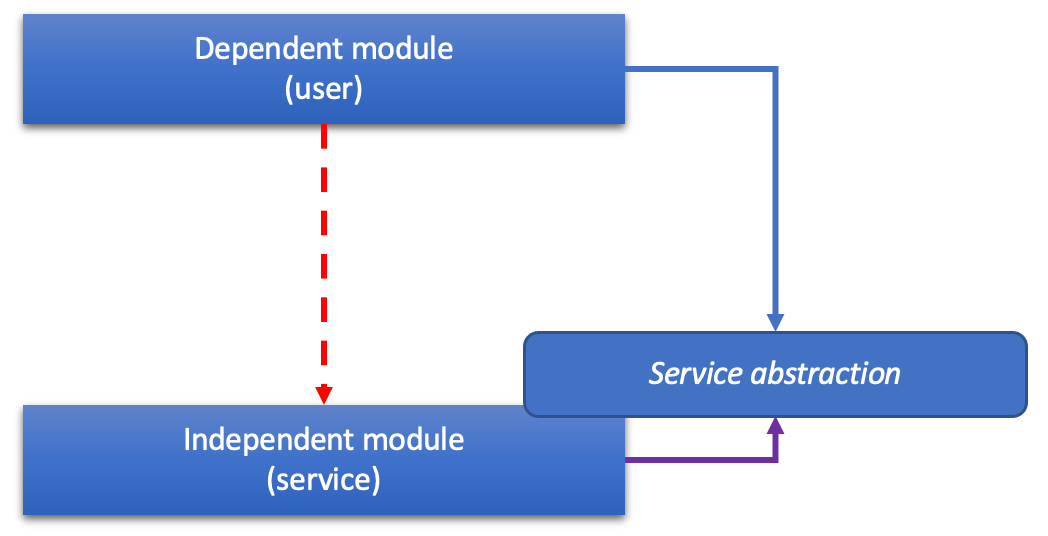
That way both runtime and design time relationships pointed in the same direction. DIP was in place, but conceptually this was unsatisfying in the end. Why should a business layer, the core, the domain depend on a “lower” layer at design time? Why should it “suffer” from low level, technical abstractions?
This dissonance was healed first by the HA, and later by the CA, by simply moving ownership of abstractions from service to user, i.e. dependent module:
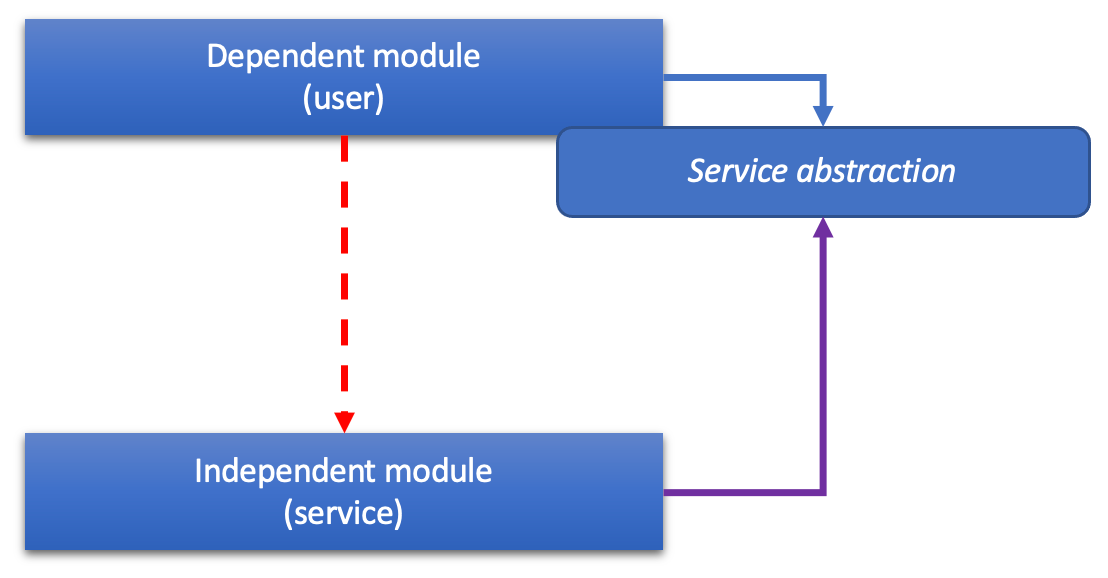
This is what the above HA image shows:
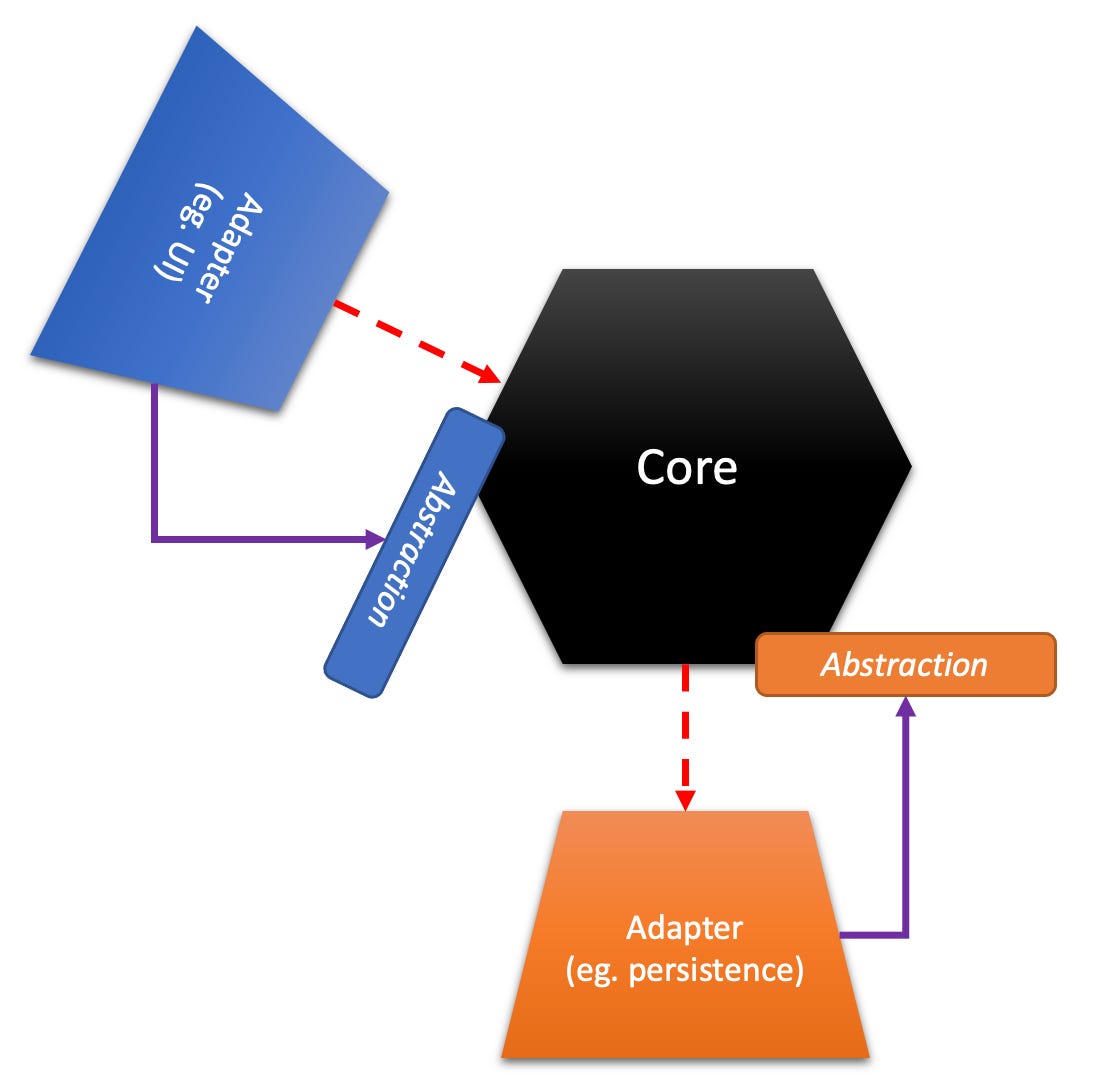
The runtime usage arrows “point through” from left to bottom; you could say, the HA is a LA by another name. The design time implementation arrows, however, point towards the center. It’s the core owning the abstractions! The core defines how it can be used, as well as how it wants to use.
The Elephant in the Room: Functional Dependencies
The evolution of the architectural patterns certainly has made things better:
Explicit concerns with non-circular relationships (1970s).
Differentiation between design time and runtime relationships (DIP) (1990s).
Moving ownership to the center of an application (2000s).
But there is something that none of the pattern has addressed. It’s the root cause of all the problems which level 2 and 3 in this evolution tried to mitigate. It’s the elephant in the room.
That is: Functional Dependencies (FD).
FD exist, when a function contains logic and also calls another function (from the same application’s codebase) for some service.

Why is that a problem? Isn’t that the most natural thing to do? Sure it is — but it poses three problems:
Mixing function calls and logic violates the Single Level of Abstraction (SLA) principle.
Mixing a function’s own logic and logic in a called function makes it hard to test just the function’s own logic.
Mixing logic and function calls leads to ever growing functions despite all refactoring efforts (extract function). There is no physical limit to the length of a function; and there is no hard-and-fast rule to stop expanding a function.
The second problem is supposed to be solved by DIP. But at what cost? Complexity is added for abstractions and injection of implementations at production and test time.
For a more in-depth explanation of FD see this article:

For the current purpose suffice it to say: the detrimental effects of FD abound even in codebases following the presented architectural patterns:
they are difficult to reason about,
they are still difficult to test.
A New Take at Software Architecture: IODA
Now, that the elephant has been made visible and named, how can it be addressed? Can FD be conquered? DIP’s defusing is but a drop in the bucket.
Yes, functional dependencies can be conquered by removing them. Working software can be built without functional dependencies — albeit for convenience’s sake some might be kept here and there, if they don’t pose hurdles for testing and/or understanding.
The IOSP as a Guiding Principle
The solution to the problem of functional dependencies lies with yet another principle: the Integration Operation Segregation Principle (IOSP). See here for a thorough explanation:
As a TL;DR it can be boiled down to:
either a function only contains logic (Operation),
or it does not contain any logic, but only calls to other functions (Integration).
The above example rewritten according to the IOSP:

The CalculateAverage function is more concise and conforms to the SLA.
The test-worthy business logic has been isolated into Process which can be tested individually if need be.
Injection of the persistence layer implementation is still in place. The IOSP is perfectly compatible with DIP. DIP has its value — however it can be used less frequently.1 (Please note: The refactoring to IOSP has been minimal to just quickly show a before/after comparison.)
Initially the IOSP is targeted at function composition. But it can be extended to modules thereby proving to be a great guiding principle for software architecture.
IODA I: Separating Functional Concerns
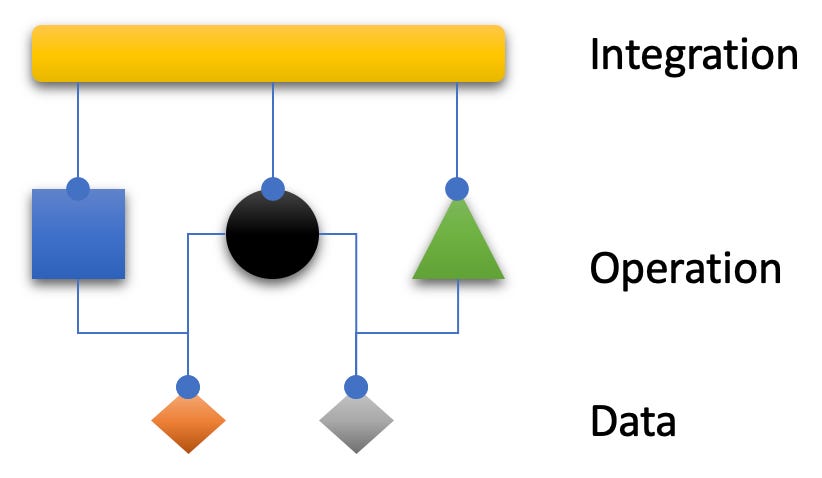
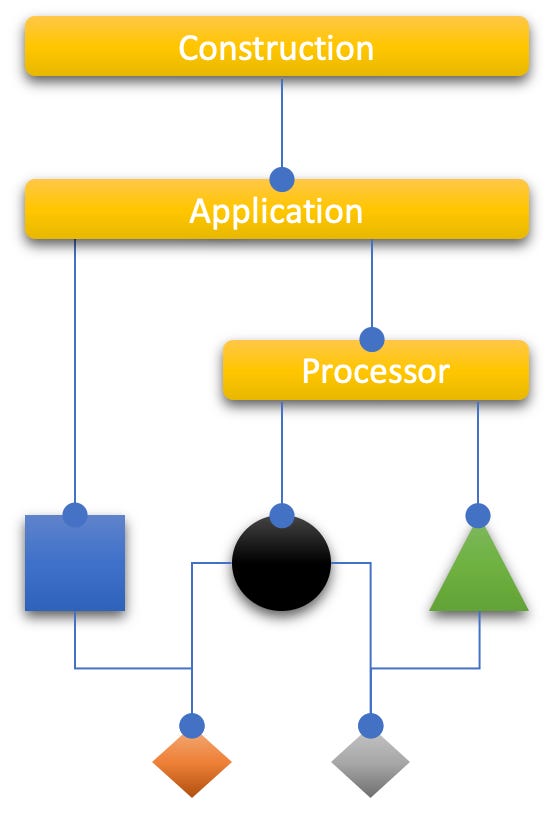
The IODA Architecture (IODA) as an alternative to the previous patterns is rooted in the IOSP from which it inherits the I and the O. But I and O now refer to modules. IODA, too, starts out by separating concerns. In that is does not differ from LA, HA etc. It even favours a concentric depiction called software cell:
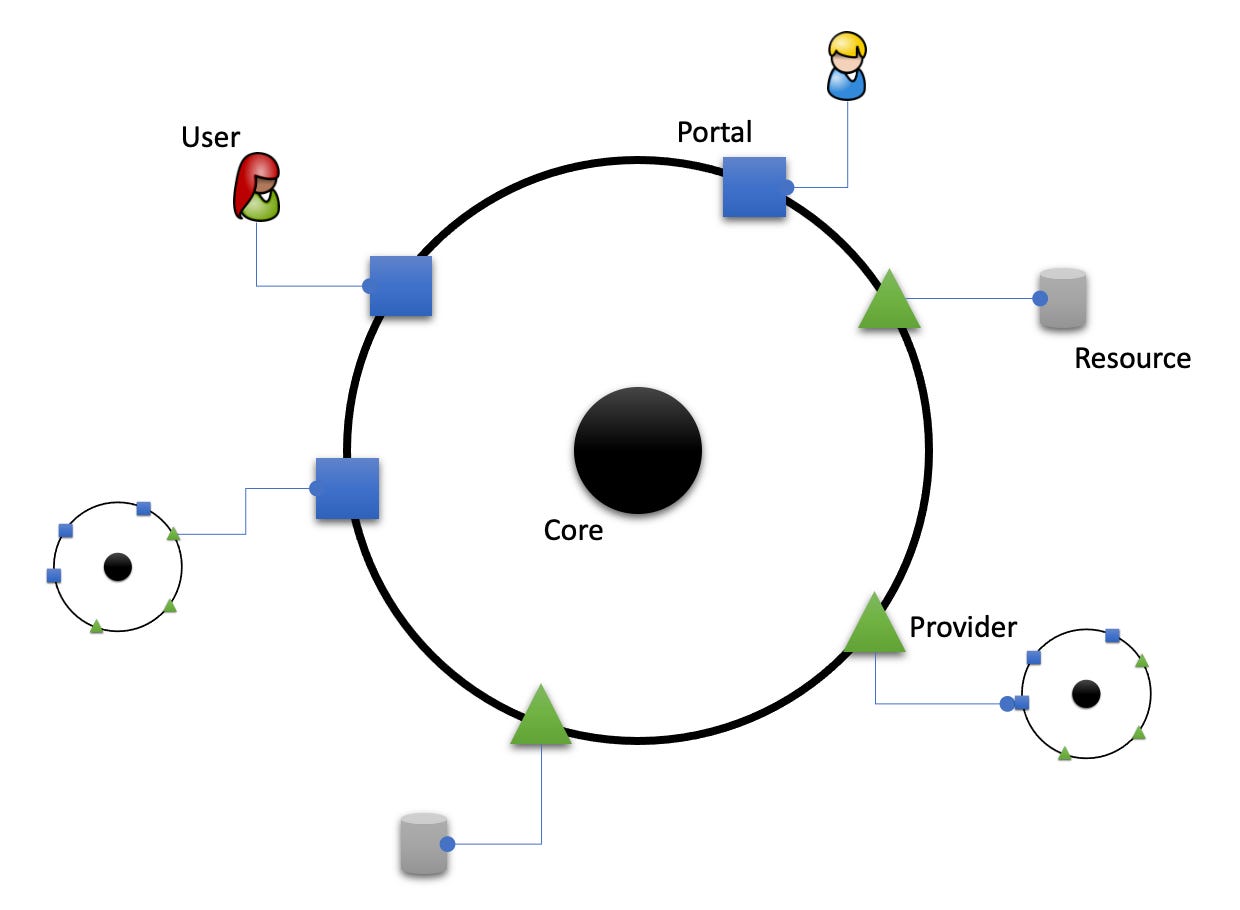
A software cell is the depiction of a software system which runs autonomously; this can be an application consisting of many macro/micro services, or just a single micro service.
At the core of a software cell is “what’s core” to the software system in question. It’s the logic the whole is revolving around independently of the environment.
The core is “in touch” with the environment though a “membrane” consisting of adapters controlling what enters/leaves the software cell.
Adapters facing the users of a software cell are called portals. Users can be human or other software.
Adapters facing services or infrastructure, e.g. databases, system timer, are called providers.
So far the software cell seems pretty similar to the HA hexagon.2 It differentiates basic concerns:
domain
communication with and isolation from the environment through adapters
However, there is a fundamental difference to the HA and all other architectural patterns: no functional dependencies exist between the concerns! No usage is implied, no relationships are drawn between the concerns. They exist in no hierarchy. They are all on eye level.

Yes, no usage relationships between the modules for the fundamental concerns! In the spirit of the IOSP they are considered operations. Or to be precise: modules with a focus on operations. Zooming in on them might reveal they contain integration functions as well as operation functions. But from higher up the purpose of the module as a whole is to contain just logic, i.e. to actually do something at runtime.
To test the implementation of these concerns, no mocks/fakes/doubles need to be employed. No dependencies have to be replaced with surrogates and injected.
But how can a software work if its constituents are not connected to each other?
IODA II: Integrating Concerns
The secret of the IODA architecture is “in the space between” the concerns. It’s not considered to be empty! Rather it’s like fascia in the human body “holding things together”.
In common architectural patterns there are explicit relationships between concerns. In the IODA architecture on the other hand there are no relationships between them; instead they are “tied into a whole” by an additional integrative concern, which is at least one module.
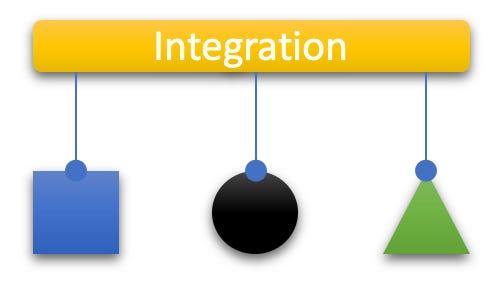
A module with the purpose of integration does not contain any logic (or if, then that’s “accidental” and minor). It’s focused on composing a “workflow” out of the operation(al) modules.
Yes, the integration depends on the integrated modules. But since it does not itself contain logic, its code is trivial; there are no functional dependencies. It hardly warrants testing.
Testing is a must for operation(al) modules, especially their operations (functions with logic). But on integrations testing can go easy. Logic is hard to get right, integration is not.
IODA III: Common Data
There is no usage dependency between operation(al) concerns. Nevertheless they need to know something about each other; some kind of agreement has to be in place. Otherwise an integration would not be possible or at least be much more complicated.
What the basic concerns are sharing is data and data structures. The result of one concern flows through the integration into another concern for further processing.
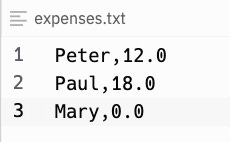
To make that tangible here’s another sample scenario: a tiny app to help splitting the costs among members of a party. All expenses are collected in a CSV file:
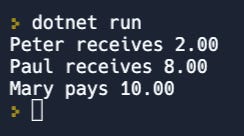
And the application prints who’s to still pay and who’s to receive money so all are even:
The concerns identified according to the software cell are:
a UI adapter (a portal) to print the results to the console for the user to see,
a persistence adapter (a provider) to read the expenses from the CSV file and transform them into a data structure the core can easily deal with, and finally
the domain (core) to calculate the payments.

The data structures (Expense, Payment) are used across concerns; they are shared between producers and consumers; they define the data contract.
(Please note that the domain module (Splitter_Core) is a static class. The reason: Since it’s not accessing any resources, i.e. has no side effects, it never needs to be replaced for testing. The IODA architecture favours a functional core, imperative shell structure - and goes beyond it: not even the shell is calling the core.3)
Integration is done by yet another module: SplitCosts_Integration. This is in line with the Single Responsibility Principle (SRP), since “how to do stuff” (operation) and “how to piece together stuff” (integration) are very different (technical) decisions and thus require a separated implementation.

SplitCosts is a pure integration function. No logic to be found. It’s easy to read/understand and barely needs any testing: to get an integration wrong is difficult. If the modules integrated are correct, then the integration is correct.
Technically the integration also has to know the data contract between the operation(al) modules. But since it does not really do anything with the data, that’s neglected. The task of the integration is to pass on data produced by one module to the next module consuming it. The integration’s composition constitutes a data flow.
Indeed one of the influences behind IODA is Flow-based Programming (FBP). But over time the rigidity of FBP was shed. Only the essentials was kept: to build software as data flows.4
Operation(al) modules depend on data, but integrations don’t. What does that mean for logic? May data types contain logic, may they be true classes/objects? Strictly speaking, no. Operations as the leafs of a function decomposition tree are the only functions to contain logic; hence they must not depend on other logic located yet on a lower IODA level in the data structures. The reason: testability.
But… since data finally really is not depending on any APIs it can be tested fairly easily. For that reason IODA “allows” some logic on data modules, too. Simple, easy to test logic which should focus on data consistency and data access. Abstract Data Types (ADT) are valuable and are part of the IODA picture. IODA is opposed to primitive obsession. (That said: IODA clearly distinguishes between data modules and functional modules. The purpose of the former being to compose data with little logic — i.e. to be data —, and the purpose of the latter being to compose logic with little data as state — i.e. to have data.)
IODA IV: Accessing the Environment
Access to the environment is confined to adapters — like in HA. Adapters do that by calling APIs of some service/infrastructure outside the application. Such calls of course are logic and can only be done in operations in operation(al) modules.
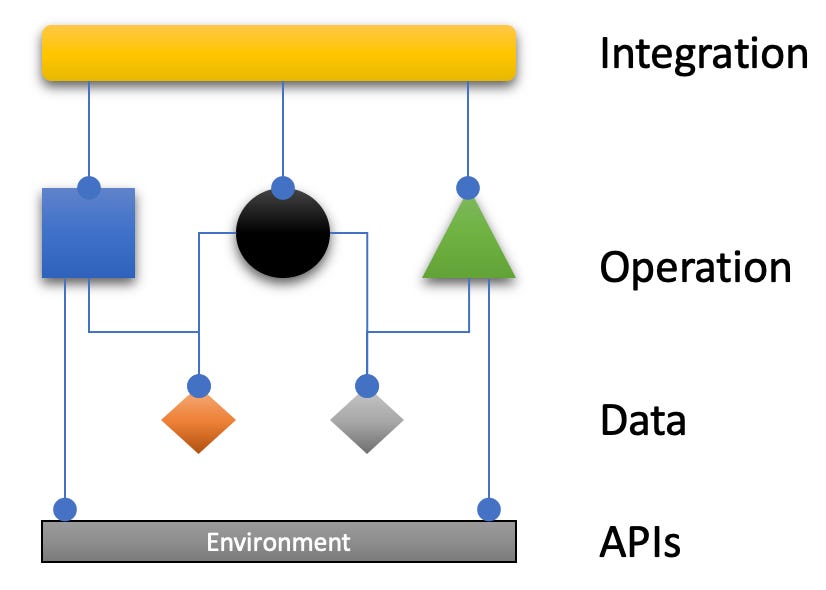
And there you have it: the acronym IODA represents all of the code categories in the architecture pattern:
integration modules as the authority to compose work flows from operation modules,
operation modules as the work horses of an application,
data modules to be used by operations to exchange data, and
APIs to be used in operation modules to cause side effects.
Or as Master Yoda might put it:
"The IODA architecture pattern, a wise choice it is. Integration modules, operation modules, data modules, and APIs, together they form a harmonious flow of the code. Understand them, a master developer must, to bring balance to the application."
IODA V: Recursive Structure
The common architectural patterns provided a quick start with a rough outline for a software system. All the major bases were covered. But it’s hard to apply them to larger code bases.
IODA is trying to improve on that by being recursive right from the start:
software cells can be nested in software cells,
IODA hierarchies can be nested inside operation(al) concerns.
The macro structure of a software system is one of software cells which can be decomposed into software cells with the leafs in this hierarchy actually being (micro) services. Here’s an example:
The top cell represents the whole software system.
It’s decomposed into two software cells maybe representing two bounded contexts in the domain of the software system.
And the left bounded context then is decomposed into three (micro) services actually constituting it at runtime.
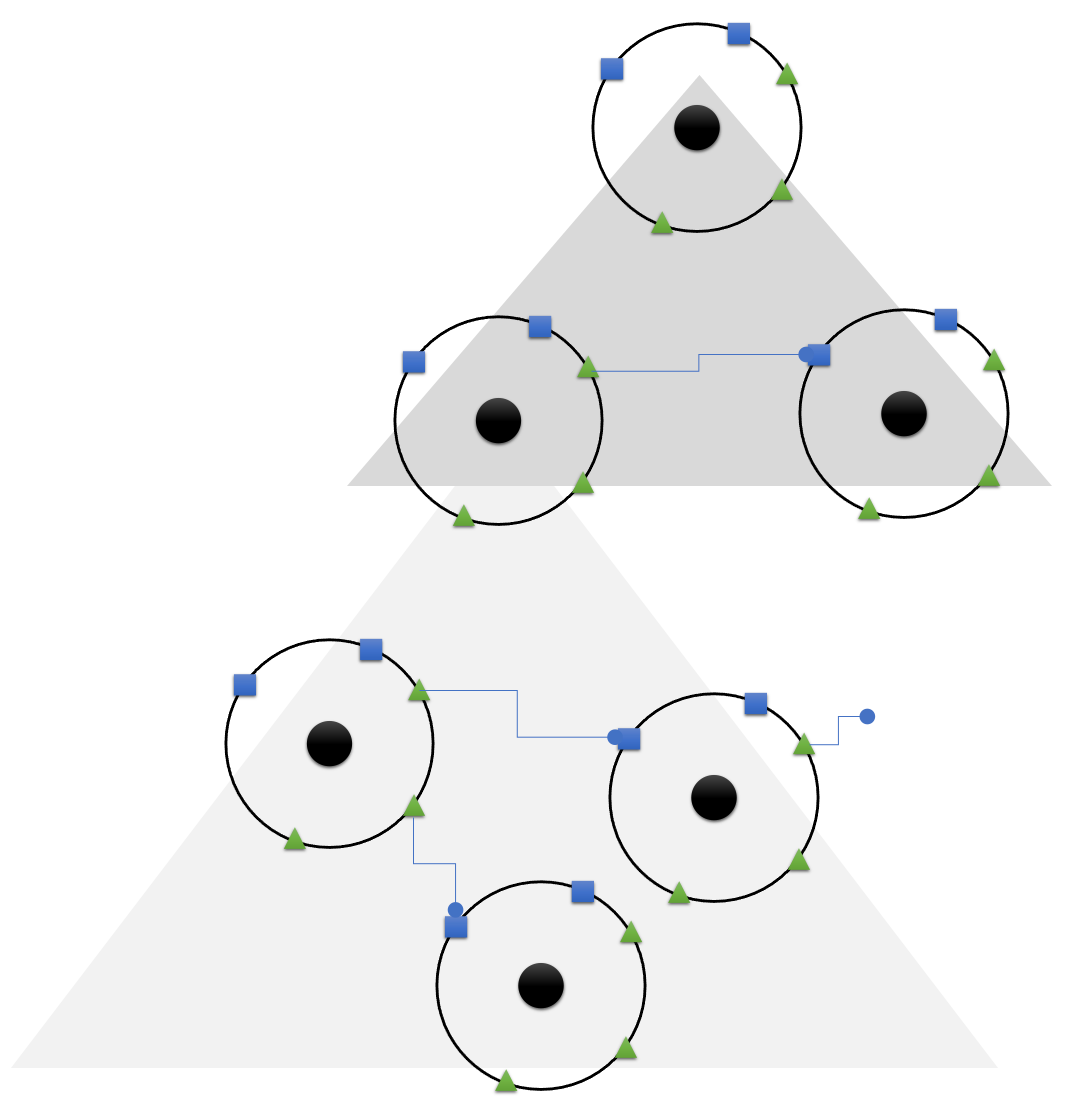
On each level the core is important as a reminder of what the whole purpose of the software cell is, it’s own domain. Portals and providers stand for the connections to the environment to be aware of. They are important because infrastructure often requires special skills, additional resources, and makes testing harder.
Likewise the concerns can be nested: integrations may exist of a hierarchy of integrations when you zoom in on them, operation(al) concern may consist of integration-operation hierarchies.
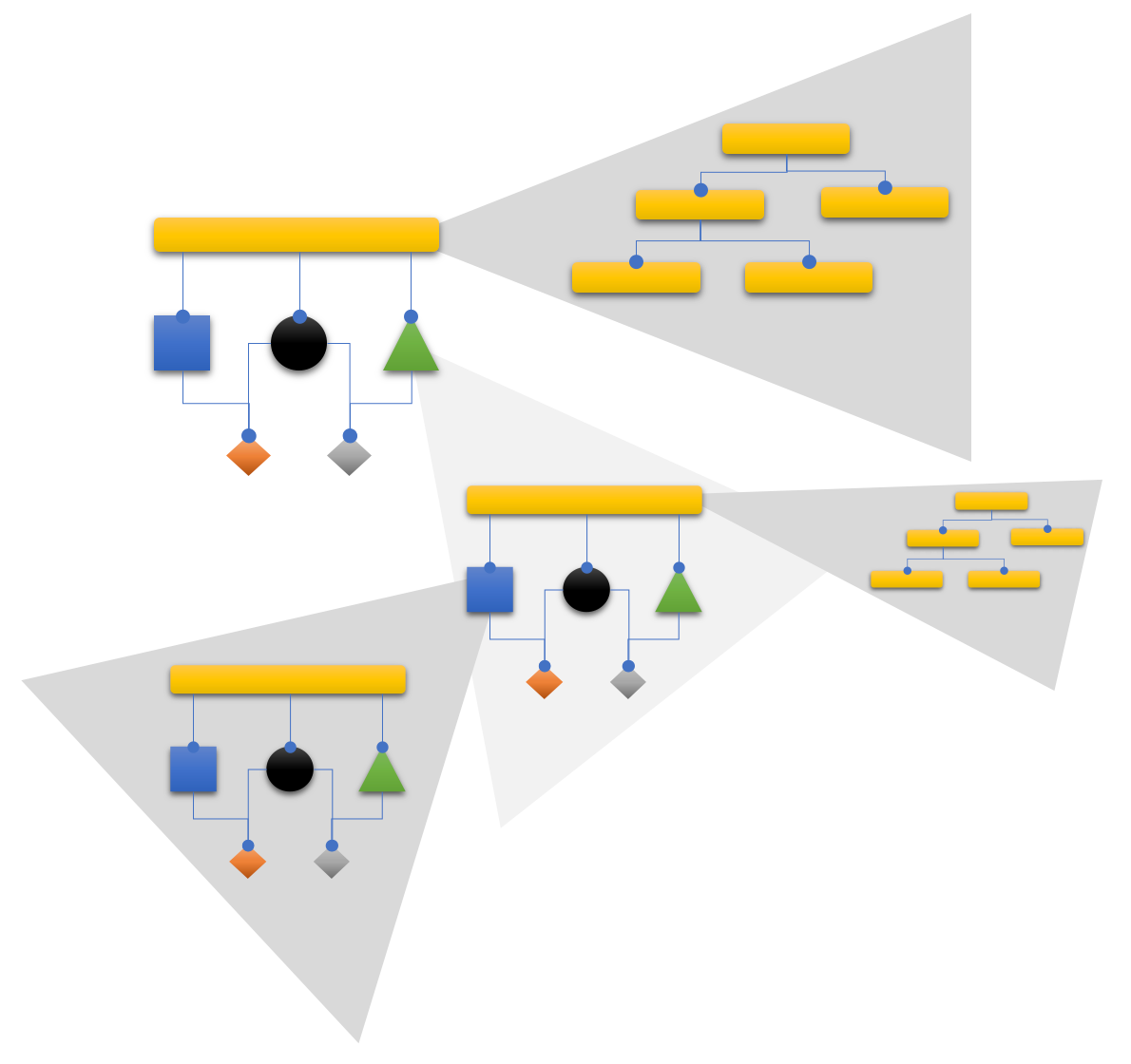
Operation(al) concerns on one level are leafs to make understanding at a certain level of abstraction easy. But when looking more closely it might turn out, that the operation is more complicated and warrants yet more decomposition.
IODA supports the honorable technique of stepwise refinement - but with a twist. The twist being: a decomposition has to conform to the IOSP.
Sleepy Hollow Architecture
IODA is the basic architectural pattern to go beyond the common ones by getting rid of functional dependencies. It’s applicable to all sorts of domains and different size software systems. Even very small applications already benefit from its approach to separating and relating concerns.
How many different portals and providers an application needs, how many layers of abstractions adapters should have, into what kind of sub-concerns the core is divided… all that is up to the developer. IODA merely has a clear opinion about how to deal with functional dependencies: Just don’t use them!
However, over time a pattern on top of the IODA pattern has been found. It supports an outside-in test-first approach by preparing roots to apply acceptance tests at.
Construction assembles the skeleton of the program. That’s where instantiations and injections happen to start-up the program.
Application represents the whole of the running application where portals and “the rest” are composed into high level flows transforming data collected from users in the environment into data to be projected to users in the environment.
Processor finally is where the action happens. It integrates providers and core modules into a whole doing the actual work — but without any dependencies to interaction technologies like UI or REST frameworks.
This refinement of the IODA pattern is called Sleepy Hollow Architecture because it separates a head from a body — with the body being the most important and active part.
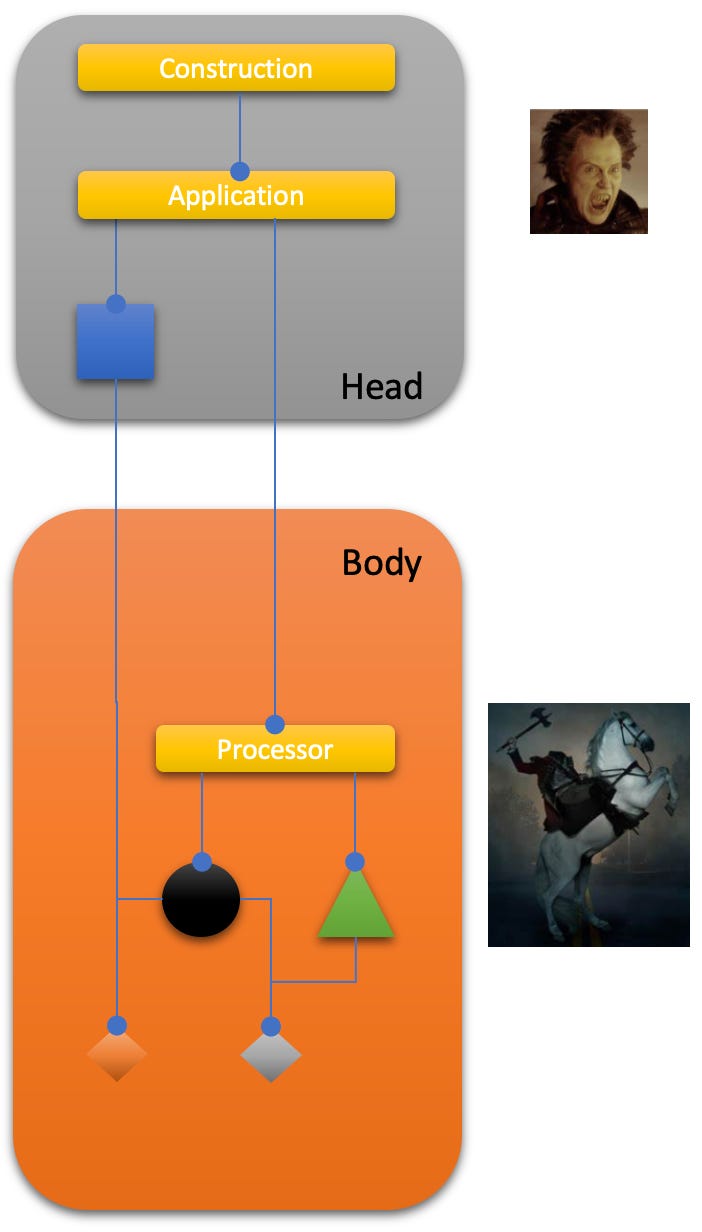
The head is hard to test automatically. To simulate user interaction is possible — but little fun. The UI is notoriously volatile and difficult to “remote control”, backend heads require infrastructure (e.g. a running server). Of course the head, too, has to be tested — but the approach differs from the one for the body.
The body is where things are happening. This is the home of the domain. This is where data is pulled from and pushed to resources.
Extracting the processor makes all this comparatively easy to test. Acceptance tests can be attached to the processor and exercise all of a program’s logic except the portals. They can mock providers if they want. They can check single functions on the processor’s interface or run scenario tests including multiple functions.
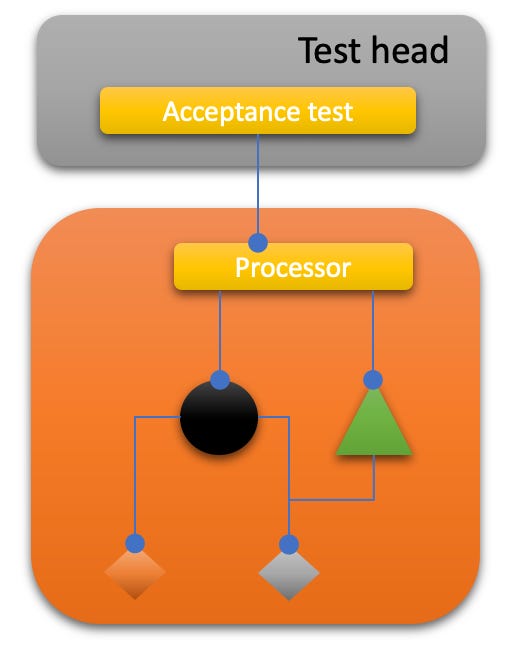
To cover a maximum of code with tests it’s important to separate head from body very closely “under the chin”. Only portal technology specific code should be kept in the head. As much logic as possible should be placed in the body.
Following is a manifestation of the Sleep Hollow Architecture. It’s still the same tiny example as used above. Hence it’s a bit over engineered, maybe. But who knows… larger applications grow from small ones.
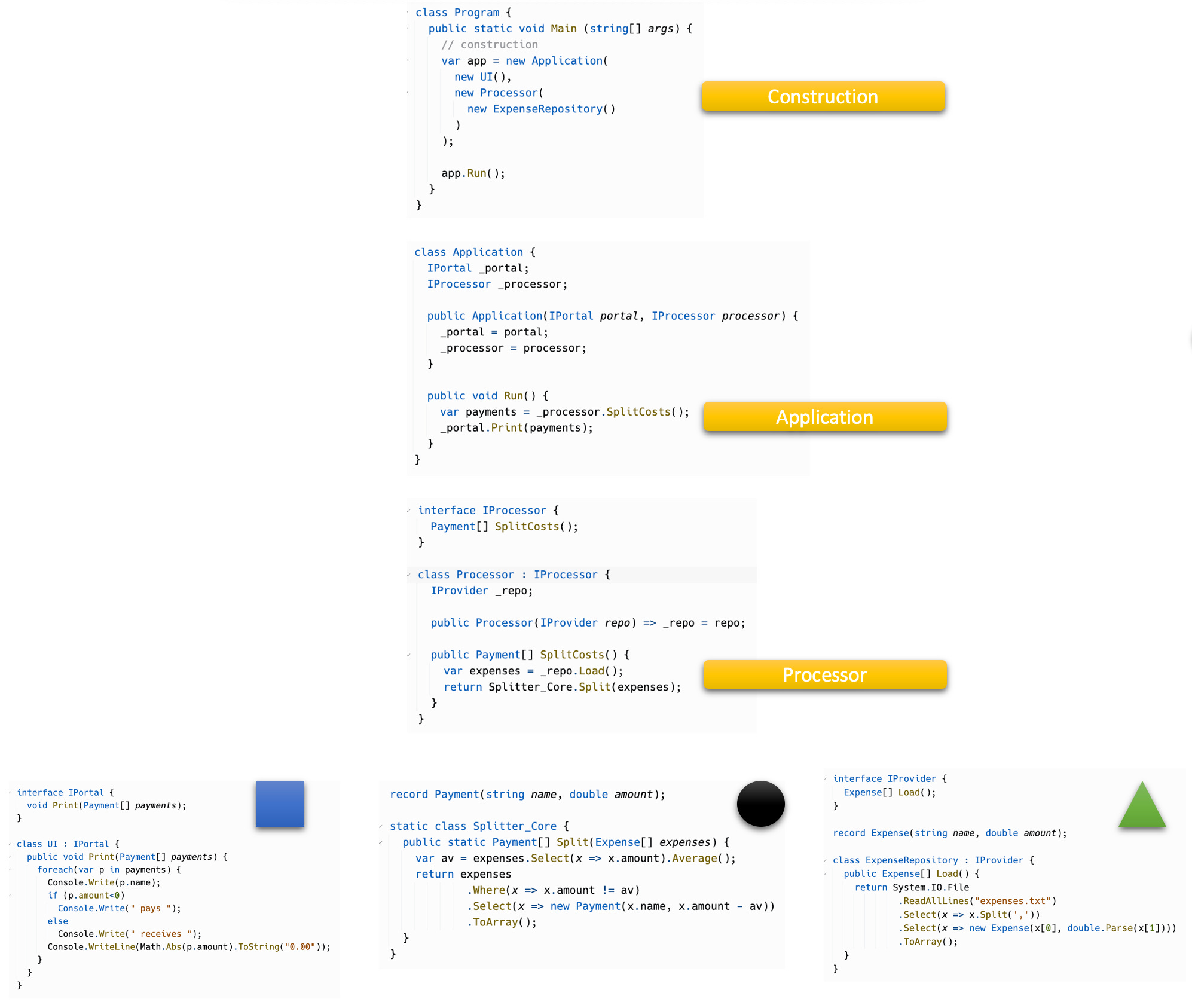
To make the code testable, the DIP is still employed. IODA is not against its application — where is really makes sense.5 The DIP should just not be used to defuse functional dependencies.
Construction of the static “object framework” happens in the main function. To piece together all parts into a whole and then kick-off the application is the sole purpose of this entry point.
When run, the application calls the processor and passes its results on to the portal for display to the user. A simple data flow.
Please note how this straightforward responsibility is surrounded by DIP noise! DIP is adding complexity! But in certain cases it might be worth it. Care should be taken, though, to minimize its use.The processor asks the repository to load the data and passes them on to the domain module whose results then “flow out” from the processor. Another data flow.
Summary
Here are some key takeaways from all of this:
Software architecture patterns have evolved over time and are designed to separate and define the relationships between fundamental concerns.
Design-time relationships and runtime relationships are different and architecture patterns are concerned with design-time relationships.
Functional dependencies (FD) pose a major problem in terms of testability and changeability. Removing functional dependencies can conquer many of the issues faced after implementing traditional software architecture patterns.
The IODA Architecture is a new take on software architecture that separates functional concerns and integrating concerns; it has a recursive structure.
The Integration Operation Segregation Principle (IOSP) is used in IODA to solve the problem of functional dependencies by separating functions into those that contain logic and those that don’t.
Give IOSP and IODA a try. You’ll be surprised how much easier software development can be on all scales.
For more context see my blog on Radical Object-Orientation:

A deeper discussion of the IOSP and its ramifications for the application of a number of principles (e.g. DIP, OCP) is unfortunately beyond this article.
However the circle for the membrane and core with the rectangles and triangles for the adapters makes it easier to draw.
A lot can be said about when and why a class should be made static vs instantiable. But that’s beyond the scope of this article. In any case, IODA welcomes both ways to use classes.
Which in turn is rooted in the original idea of object-orientation as proposed by Alan Kay in 1968.
That usually means where it’s hard to test an integration otherwise.
Hi Ralf, I am currently trying to learn Flow Design, IODA, IOSP etc. with your book Flow Design Programming with ease and with your colleague Stefan Lieser´s book Flow Design. I also read your articles in the DotnetPro magazine and investigating the github repos of you and Stefan. I find your ideas interesting, and I am excited if I can introduce these concepts in our brown field projects (more or less).
But I am little bit disappointed about the less reaction of the community here and your other posts. It would be great to see if others could implement these concepts in their business applicatons successfully and what challanges they had to solve.
It would be great to have others to talk about questions, ideas etc. Is there any community place where IODA/IOSP is discussed?
Regarding Sleepy Hollow Architecture and the Interactors, it seems that you and Stefan have a different definition of a flow design based software structure. In Stefan´s book (page 177) it seems that the Interactors class is that what here in your post is the Processor. So Stefans Interactors is integrating Domain and Provider. His Interactors is not integrating UI. In Stefans architecture he has a Controller class that integrates UI and Interactors.
Can you give some clarification of my confusion please?
Are you both still working together or do you have different opinions?
Why two books and not one book together?
Regards,
Christian
Coming from the "True agility needs event sourcing" thread and arrived reading this one due to your hint. Very interesting approach and I might try to design the inner world of a slice like this. What would help me is to see a recursive example of IODA. When a larger cell is dependent of a smaller cell, is the smaller cell then called via a provider?