

The time for the Entity is over. I’ve come to kill it. The Aggregate has lost its last fight already. But the Entity was still begging for merci. No more!

Object-orientation (OO) and Domain Driven Design (DDD) have ruled software development long enough. Their approach to design seemed natural, even inevitable. Yet, is has caused immeasurable harm. It was another multi-billion dollar mistake.
I am done with that!
What’s wrong with OO and DDD you ask?
For decades we tried to convince ourselves that a proper, well thought out domain model was essential for good, long lasting software. But we lied to ourselves. We did not acknowledge the persisting pain we were suffering from. Despite all our Agile efforts.
“I am done with living the lie!”
Pain? Yes. Pain, because those single domain models require pretty big design up-front.
They ask you to sit down and come up with intricate models of the domain: domain models consisting of OO objects, that is. And these models are supposed to consist of Entities and Aggregates.
Sure, good reasons have been brought forward for all of that — but to no avail. Software development has stayed very hard. The tell tale sign of that is the exclamation “Couldn’t you have told us earlier?!” when facing new requirements.
Whenever a dev makes an exclaim like that she is frustrated because she realizes her intricately designed domain structures are not fit for a requirement just revealed. WTF!
Agility already has discovered the futility of Big Design Up-front (BDUF) and tried to remedy the situation by changing the pace of the process of software development. But this wasn’t matched by a change in the basic software architecture.

Well aware of Agility DDD, the Hexagonal Architecture, and the Clean Architecture were proposed without really getting rid of “big designs”. Open any book on DDD and you’ll find central single domain models for any example scenario as a testament to that.
This practice needs to stop! If software development really wants to become Agile, then all such “well laid plans” need to go out the window. Not only the Aggregate needs to die, Entities as well have to die.
No more Entity-Relationship Diagrams (ERD) or the like for all business logic in an application to share.
I am done with that!
To do a thorough job I want to quickly describe the enemy, though:
Event Sourcing with Entities
Agility requires Event Sourcing. That much should be clear by now. But Event Sourcing has been pretty tightly coupled with OO and the notion of Entities and their consistency keepers, the Aggregates.
To recap: Entities are the “things” with an immutable ID for their identity and multiple mutable other properties. They are easily manifested as OO objects and can be persisted to JSON documents or even RDBMS tables. For decades O/R mappers have tried to overcome the impedance mismatch between object layouts in memory and their persistent counterparts in RDBMS.
These Entities are what developers all over the world are hunting for when facing requirements. According to DDD they divide them up into different domains (wrapped in Bounded Contexts (BC)) with their own domain languages (Ubiquitous Language (UL)) — and then sit down to come up with a plan for a model of the “things” they perceive inside the domain, the Entities and their properties (Value Objects (VO)) and relationships, plus possibly overarching structures called Aggregates to guarantee consistency during change.
Take this scenario for example:
At a school there are teachers and students. Students register and pay a tuition fee. Teachers get signed on for a semester and teach courses. Students enroll themselves in courses and get grades for their performance.
Does that sound reasonable? Now, what would you do if you were tasked with developing an application for this domain?
I imagine you’d talk to the domain experts some more and then try to come up with a domain model. In that domain model you’d lay out which Entities you spotted with what kind of properties and how they all are connected. Right?
Entities pretty obvious from the above description are, I guess:
STUDENT
TEACHER
COURSE
And relationships between these Entities? Some seem natural, eg.
A COURSE is related to a single TEACHER teaching it.
A COURSE is related to many STUDENTs, a STUDENT is related to many COURSEs he’s taking.
Sounds spot on, doesn’t it?
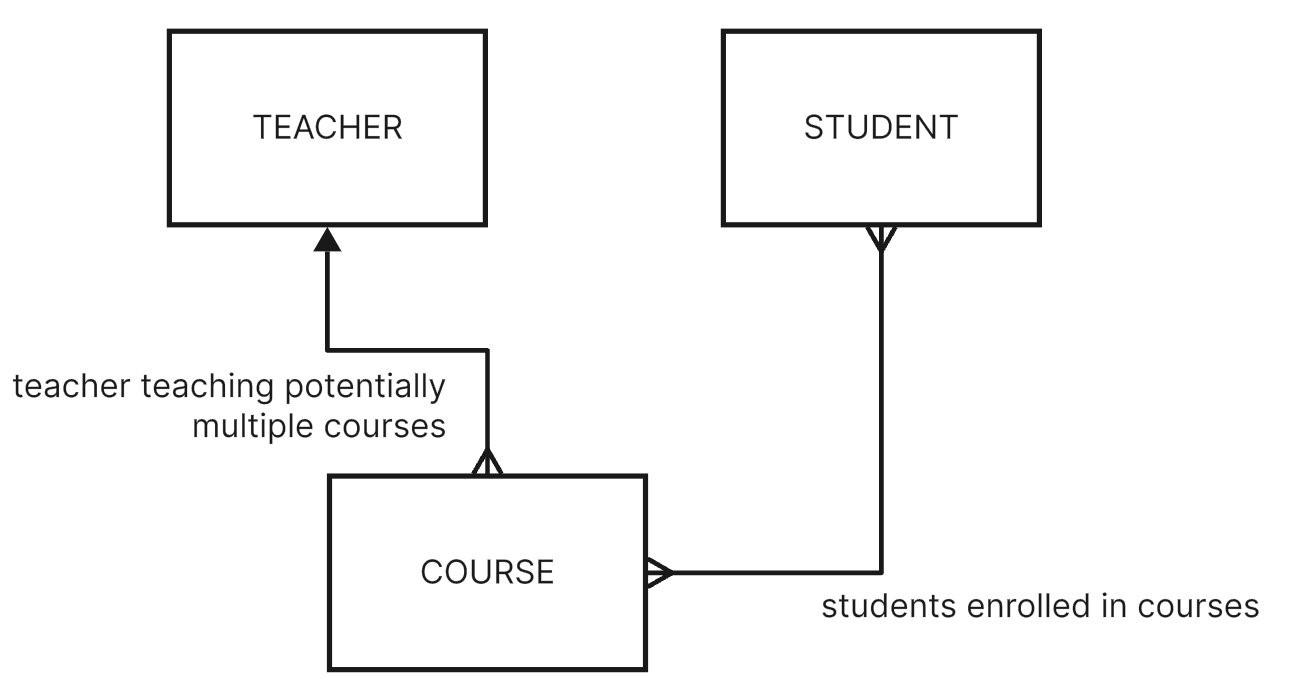
What a paragon of domain models!
And then you map this to a RDBMS… or you’ve been enlightened already and go for an Event Store.
In an Event Store you’re sure to map all Entities to separate streams for quick access. And all events get assigned to an Entity by referencing it with an ID. Entities have IDs, right? That’s how you tell them apart even if they should (incidentally) contain the same values.
Examples for events pertaining to the example domain:
TeacherSignedOn{name: "Tom", teacherId: "123"}
...
StudentRegistered{name: "Steve", studentId: "987"}
...
TuitionPaid{amount: 1500, studentId: "987"}
...
CoursePublished{title: "Event Sourcing 101", teacherId: "123", courseId: "abc"}
...
Enrolled{courseId: "abc", studenId: "987"}
...Does that look reasonable? I hope so.
Please notice that Enrolled does not have an ID of its own. Enrollment is not an Entity, likewise paying the tuition. Rather it’s an event connecting two Entities like a join-table in RDBMS.
When an Entity is created in the domain model, a corresponding event is written to a stream. In this example that’s TeacherSignedOn, StudentRegistered, and CoursePublished.
Entities in the outside world (or domain) need to be properly represented in the event stream, don’t they? Only then these Entities can accumulate data through other events.
This seems so normal, so inevitable, so mainstream, so every-day… why not do it like this?
To me the answer is obvious:
Designing domain models is premature optimization.
Premature optimization is the root of all evil in software development. Hence, it’s also the root of dirty, hard to reason about, hard to test code.
Why is designing a domain model premature optimization?
It’s an optimization because it’s supposed to be useful for many requirement increments to come. And it’s to be useful across a wide are of the growing codebase.
It’s premature because there are so many unknown unknowns. What the customer wants tomorrow, next week, next month, next year nobody knows — not even the customer herself. Hence to try to come up with a stable single data structure at the center of a BC is… premature and bound to fail sooner or later.
How does failure look like? One of the signs is growing frustration with code already present; developers are sensitive to being hampered by structures resulting from past decisions not fitting the current needs. This then leads to declining productivity. It also leads to inability to truly work in parallel on code. Or it looks like conflicts between team members: some want the domain model to look like this for their purposes (eg. functionality), some want it to look like that for other purposes (eg. performance).1
This is what makes up much of the tediousness and stress of software development. Coming up with domain models takes a lot of effort. So much communication, so many decisions… all for just a model which never will hold what it promised.
To that I say: No more!
I am done!
Event Sourcing without Entities
Designing object models supposed to be shared by many features and wide areas of code takes a lot of time and is highly error prone. The reason: it’s speculative. It’s almost science fiction.
You’re looking at known requirements, trying to extract invariants, extrapolate into the future, throw in some experience you think you’ve accumulated… and divine a pretty intricate model of “all things relevant to the domain”.
Haven’t you ever felt this to be not only frustrating, but even enraging for it’s futility? Haven’t you ever felt like Sisyphus?
I have. And I don’t want to feel like that again. Ever.
That’s why the Entity has to die.
Because the Entity, the notion of something stable, which can and should be discerned as early as possible “once and for all” is at the root of this fallacy.

As long as we software developers believe in such a mystical being it’s not an angel but a monster. It’s coming for us to eat us alive. It’s sucking our precious limited energy from us.
We must not let that happen anymore!
We owe that to ourselves and our customers.
It’s just frigging expensive. Planning Entities comes with a horrible cost.
But fortunately we can rid ourselves of them. We don’t have to fall into the trap anymore. It’s just a matter of using an Event Store in a different manner.
This is how envision it:
There is no outside, there are only events inside
Killing the Entity is as simple as negating the notion of an outside world. Once there is no outside world there are no Entities anymore. Because entities are “living” in the outside world, in the domain. Events in the usual Event Store refer to Entities “out there” (“specific instances in the domain”); that’s where their IDs are pointing to.
I propose to view events differently:
Events are all there is.
There is no outside world. There are no references to “instances in the domain”. There are no instances. There is only an Event Store with a single stream of events.
Looking back at the above domain description you don’t hunt down Entities. You don’t become a collector of nouns.
You just focus on “what’s happening”, on events. One event at a time. Then the next one and so on.
But no Entities.
Verbs over nouns!
Events are telling a story
Once you focus on events only in the domain, the language shifts from nouns to verbs.
It all starts with signing on teachers, like Tom. He came on the other week to teach computer science. Teachers are teaching courses they plan on their own and then publish in our catalog for all students to see 6 weeks before the next semester. Students then enroll themselves in courses — up to a certain limit per course —, and in the end get graded for their performance.
This is much more like domain experts talk about their work. They know what they are doing. They know, what’s happening. They know how one “thing” leads to another.
Sure, they understand that a student (noun) is different from enrolling in a course (verb). But they don’t distinguish that much; they are preoccupied with transitions, transformations, changes (activities represented by verbs). Developers on the hunt for nouns seem to be misunderstanding that; they are so preoccupied by their programming paradigm (OO).
Reality is so much simpler, though. Why not just listen and take for real only what domain experts actually are saying. That is: What kind of story they are telling.
Instead of pressing domain experts to define the Entities of their domain comprehensively, developers should focus only on the immediate. Their task is not to develop a domain model, but to deliver functionality.
Functionality is a story of a limited set of events happening. Stories are events unfolding. Stories are events related to other events.
Once we start to use Event Stores to record this reality, Entities are dead.
They have no more air to breath. They get deflated. They vanish. Because they are simply not needed anymore. There is no use for design up-front, i.e. beyond what is immediate, right at our feet during requirement analysis.
No more divination! Let’s stick to what domain experts are telling us that happens:
Teachers SIGN-ON
Students REGISTER
Students are PAYING a tuition
Teachers PUBLISH courses
Students ENROLL in courses
Finally students get GRADED for what they accomplished during an enrollment
Of course you immediately see where this is leading to: events. And that’s on purpose! If you’re using an Event Store to boost your Agility, then you should know which events are relevant as quickly as possible.
And even the above is already too much. It’s not focused on the next increment to implement. So, look even closer. Reduce the scope to the absolute minimum for delivering value quickly. Remember the Agile Manifesto?
“Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.”
This is still true and so important. But designing domain models does not support that in any way. No customer wants a domain model, i.e. a data structure. Customers want software to behave in a certain way when triggering it. They want functionality.
So, don’t go on a detour trying to carve out Entities! There are none to find. Not anymore. You don’t have to reference instances in a fictitious outside world. The inside world consist just of a stream of events.
Putting activities, verbs, actions into the past tense is easy; events can only be recorded after they have happened. Lining them up in a temporal sequence is easy.
TeacherSignedOn{name: "Tom"}
...
StudentRegistered{name: "Steve"}
...
CoursePublished{title: "Event Sourcing 101"}
...
TuitionPaid{amount: 1500}
...
Enrolled{???}
...
Graded{grade: "B"}But doesn’t that look like Event Sourcing with Entities? At least almost. Because there is something missing: IDs.
Of course IDs are missing. That’s the whole point. After Entities were killed there are no objects with identities in the outside world that can manifest themselves in the event stream. There is no teacher, no student, no course. There are only events.
Events in a certain temporal order are but half the truth, though. Events are not just differences in data (payload) with a meaning (event type) one after another in time (append only sequence).
No, there is more to events! And that has been neglected so far in Event Sourcing. It has been overshadowed by all the attention on Entities.
Not anymore!
The neglected aspect of Event Sourcing are relationships between events.
Events themselves are connected. Forget about connected Entities. Look at what’s much more obvious and does not require much imagination: relationships between events.
Events follow each other. One leads to another. In real life — and hence in the Event Store. The domain experts are very eager to tell you about that.
Sometimes such connections between events are causal, sometimes they are just correlations. Regardless, events should be connected where it makes sense.
Ask yourself: Which precursors does an event have? Which other events does it “embellish”, annotate? Does an event connect previous events? Does an event add detail to others, extend them, or continue them?
The above sequence of events is not complete without connections between events. Also the “???” in Enrolled is telling there is something missing.
Here is the full picture of how some stories at the example school unfolded:
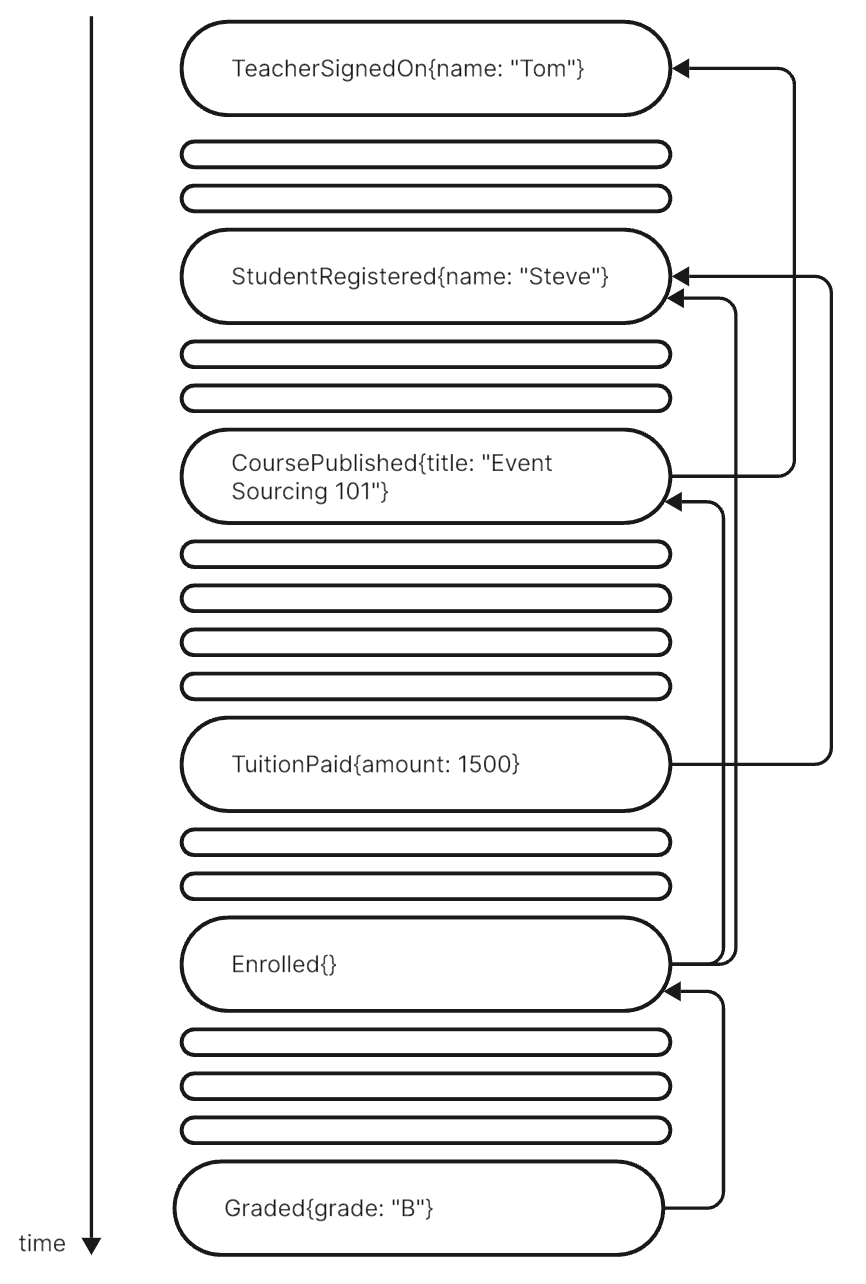
Events happening in time, sometimes in parallel, sometimes consecutively. Some are connected, some not.
How they are connected is kind of hard to see in the event stream, though. Let me pull them out and arrange them in their “lineage”:
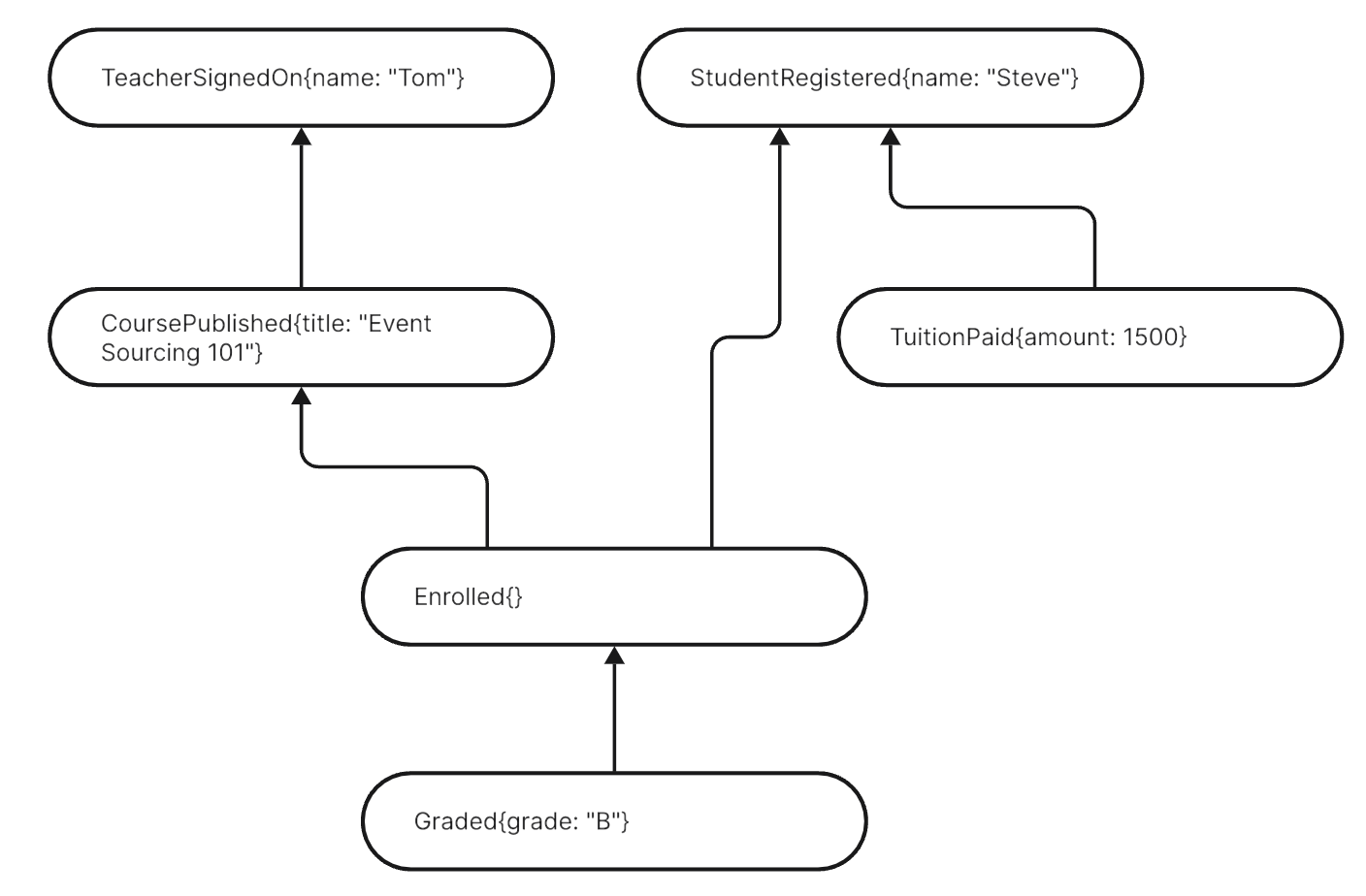
Here you can see how some events depend on each other, eg.
TuitionPaiddepends onStudentRegistered. And others are independent, eg.TeacherSignedOnandStudentRegistered.Some events have only one successor (eg.
TeacherSignedOn), some several (eg.StudentRegistered).Some events have only one predecessor (eg.
Graded), some several (eg.Enrolled).
This is a proper Acyclic Directed Graph (DAG) of events documenting the sequence of events as they happened.
There are no Entities here. But I guess you feel where you formerly would have designed them: it’s the independent events (TeacherSignedOn, StudentRegistered) that seem to hint at Entities.
But this pattern fails already with CoursePublished. It’s not an independent event although in your design you’d probably modelled an Entity for it (like I suggested above). However, there is nothing special about CoursePublished. It’s an event like any other depending on another and others depending on it. No signal to design an Entity.
Even worse Enrolled. You’d probably not have thought about that as an Entity (like I did not above).2 Here however this event is a predecessor to another just like the independent StudentRegistered. There is no difference. And why should there be? It’s all just events…
What’s encoded in this event graph to me are stories. Stories of what happened. They can be told following events downstream:
Tom signed on with the school. He thought about what would be a fun subject for computer science students and came up with “Event Sourcing 101”. He published a course for that and right away student Steve enrolled. As it turned out, he was a pretty good student and Tom gave him a “B”.
Or they can be recounted upstream:
The “B” for the achievements while participating in course “Event Sourcing 101” taught by Tom surprised student Steve.
Notice how in this story there is no mention of a tuition paid by Steve. That’s not part of the story leading to the grade or starting with the grade. There is no direct or indirect relationship between the Graded and TuitionPaid events.
This kind of using an Event Store I call Story Recoding. An Event Store supporting this paradigm to me is a Story Store.
Implementing event relationships
As soon as you’re facing the first increment in a project you can start recording stories. Just focus on what you know:
What’s happening?
How does that relate to what happened before?
You only look upstream. You look backwards. You look at facts.
You do not look into the future. You do not speculate and imagine. You do not try to abstract anything from activities. You don’t need to build models when recording events. Just faithfully continue the stories already started, or start new ones.
You can do this easily with an Event Store of your choice. It only needs to support the conceptual basics of Event Sourcing:
Event type
Payload for data associated with the event
Depending on your Event Store implementation events might come with some kind of sequence number or index and timestamp to keep them in a strict temporal order to which new events are always appended at the end. This is of no concern for relating events, though.
What you have to do is, you have to add an explicit event ID to each and every event. The ideal and natural ID for an event is its hash. Why the hash? Because it removes the last traces of Entities from events. Entities cannot have hashes because they change all the time. Events don’t; their whole purpose is to be an immutable record of what happened. It is a compressed version of an event that can easily be used for referencing it somewhere downstream. Hashes by definition are not pointing to anything anywhere outside the Event Store; no fiction in them. They are calculated from what is present.3
With a hash “as the address” of an event in “event space” (where each event is unique by definition) events don’t turn into Entities all of a sudden. Yes, they are getting an ID; but that is just a convenient name. Don’t get confused by it. Use “address” or “hash” instead, if you like. Events are no “things”. They never change. Once they come into existence they stay the same “for all time”. But in order to point at them — “Look, this event there!” — it’s convenient for have a shorthand for them.4 That’s what an ID is.
Entities are gone for good. They are dead. You’re wasting your time looking for them. Go through the stages of grief quickly. There is a new life waiting for you: a happier life without Entities.
The event’s ID is not a condensation nucleus for accumulating properties and allowing change. No, it’s just the prerequisite for relating events to each other.
In dependent successor events you reference an event by mentioning its event ID. That can be none, one, or multiple depending on the story unfolding.
Here is the event stream from above now with event IDs and references:
TeacherSignedOn{name: "Tom", teacherSignedOnId: "123"}
...
StudentRegistered{name: "Steve", studentRegisteredId: "987"}
...
CoursePublished{title: "Event Sourcing 101", coursePublishedId: "abc", teacherSignedOnId: "123"}
...
TuitionPaid{amount: 1500, tuitionPaidId: "qyp", studentRegisteredId: "987"}
...
Enrolled{enrolledId: "38x", coursePublishedId: "abc", studentRegisteredId: "987"}
...
Graded{grade: "B", gradedId: "9y2", enrolledId: "38x"}Every event has an ID. Notice how I named the IDs: they are the event name plus the suffix “Id”; a very simple convention.
With their own IDs, now every event can be a root for a dependency graph. You do not need to think ahead. No need to go through “What if?” scenarios. No design up-front for any models that may or may not be needed in a certain form in the future.
Focus on what you really know when crafting new events. Be an epistemic developer.
Working with stories
This is a paradigm shift for you, I imagine. You thought you knew what Event Sourcing means — finding Entities and Aggregates, crafting events, optimizing with streams —, and now I am telling you to throw that over board.
I am not doing this lightly, believe me. But the traditional, the mainstream approach to software development in general and Event Sourcing in particular does not cut it anymore for me. It’s taking too much time. It does not really make me as productive as I want to be. And I identified the up-front modelling effort as the root cause for that.
Agility was right. However, it wasn’t brave enough. It did not push through to basic code architecture. It was content by rattling the cage, not breaking out of it.
Any model bigger than what I need right now for the current increment is too big.
It is a premature optimization prone to cause more problems than benefits in the future.
My conclusion: I need to focus more on the now. On facts. On what is certain. Just model and build for the moment based on what I know. What I know is the past and the immediate requirements. Nothing more, nothing less.
So, let’s go through some increments in the example school management application to see what this approach feels like. I’ll skip the trivial scenarios (onboarding a teacher or publishing a course or registering a student); consider them implemented with the respective events.

Remember: There are no Entities! It’s all events related to events only. Events are all there is when analyzing the requirements of a next increment.
Enrolling a student in a course
Let’s imagine the next increment is about enrolling a student in a course:
A student browses the catalog of published courses. Each is displayed with its title and teacher. If a student finds a course interesting, she hits a button and is put on the list of participants.
This is of course subject to the course capacity. If that has maxed out already, the student cannot enroll herself. Also enrollment is of course only possible once.
If enrollment is not possible for one of these reasons, the courses should not even allow it in the user interface and signal so (e.g. by being grayed out).
I will leave aside UI details and focus on the relevant CQS requests (commands and queries).
As a basis for design and implementation of this increment I first compile the relevant events, existing and not yet existing:
CoursePublishedis an obvious part of the contexts of request handlersTo also show the teachers of courses the predecessor of
CoursePublishedevents has to be pulled from the event stream:TeacherSignedOn.
Both event types allow building a sort of context model to be handed to the UI for displaying all published courses.
But there is something missing: the information about remaining course capacity and whether the browsing student already has been enrolled.
The
Enrolledevents also have to be pulled for eachCoursePublishedevent. Counting and comparing them to the course capacity shows if there is room left for another student.
What about the student herself? I am assuming she has been authenticated already.
For authentication the
StudentRegisteredevent is relevant.5
Interestingly there are no Enrolled events yet. But in my search for relevant events I naturally came across it. It’s the event to produce, as well as an event important to satisfy user interface requirements.
Since it’s relevant on both sides of the increment (command and queries), I think it’s a hint at a requirements split. The given scope should be separated into at least two smaller increments:
Displaying a course catalog without constraints and let the student enroll herself.
Displaying a course catalog with greyed out courses which are not eligible for a student.
For increment #1 only CoursePublished, and TeacherSignedOn are relevant for building the context for a query to return a projection to be displayed as a course catalog, e.g. GetCourseCatalog().
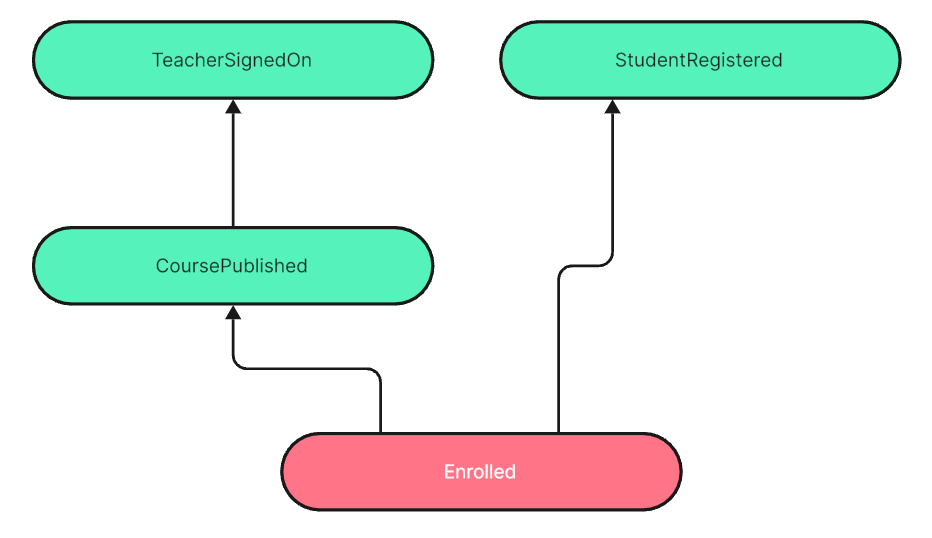
And Enrolled is the event to be generated by the command Enroll() which also requires a reference to the student to be enrolled. That requires the StudentRegistered e.g. during authentication.
From the course selected in the catalog the coursePublishedId is known, and from authentication the studentRegisteredId ist known. Both together form the core of the new Enrolled event referencing a CoursePublished and a StudentRegistered event as predecessors.
GetCourseCatalog(){title:string, teacher:string, coursePublishedId:string}[]Enroll(studentRegisteredId:string, coursePublishedId:string):{enrolledId:string}
For increment #2 the studentRegisteredId would also be passed to the GetCourseCatalog() query. The query would then also retrieve the Enrolled events into its context, compare their number per course with the course’s max. number of participants and check where the student is enrolled already.
GetCourseCatalog(studentRegisteredId:string){title:string, teacher:string, eligible:boolean, coursePublishedId:string}[]
It’s pretty straightforward to implement the increments, isn’t it? I only need to focus on events: What has been recorded already? How are events related? What do I want to record in addition and how to related it to existing events?
That*s it. Not a single thought about Entities. None. Not for a second. I don’t need to tease out of a domain expert beyond what’s of immediate use for the increment. No musing about whether enrollments should be something special. Do they have attributes? Are the Value Objects or Entities? What’s their Aggregate?
In Story Recording I am spared all of that!
Sure, when building a context model some nouns might pop into my head. “Ok, the customer wants a course catalog to be displayed. It’s a list of courses. Each with a title and a teacher’s name.” etc.
That’s perfectly fine. I’m not done with data structures or even “smart” data structures (aka mainstream OO objects) in general as programming constructs within a limited scope.
But I am done with comprehensive planned Entities woven into intricate models independent of events.
Deriving data structures from events as projections is totally fine with me. Go ahead and construct whatever fits the bill for each request. Here’s a more elaborate example for GetCourseCatalog():
interface CourseCatalog {
courses: CourseCatalogEntry[]
}
interface CourseCatalogEntry {
courseId:string,
title:string,
teacherName:string,
eligibleForStudent:boolean
}Do it very specifically, very local. Do not try to generalize, i.e. look ahead and imagine what might be needed in the future. Only look at what there is already. Look to the past, not the future. Find patterns and build abstractions from them. That’s all great.
Just don’t fall into the trap of premature optimization. Don’t fall for the Sirens’ song of DRY at all costs.
Entrust your progress to the stream of events.
Grading a student
One more increment to give you an impression of how to work with a Story Store:
At the end of each semester teachers grade the students who participated in their courses. The teacher chooses one of his courses from a list and enters for each student enrolled a grade.
What’s in this description in terms of requests and events? As a prerequisite I am assuming the teacher has been authenticated; her teacherSignedOnId is known when she grades students.
A query delivers a list of the teacher’s courses,
GetTeacherCourseCatalog(teacherSignedOnId:string):{title:string, coursePublishedId:string}[]Another query delivers the students enrolled in a particular course,
GetStudentsInCourse(coursePublishedId:string):{studentName:string, enrolledId:string}A grade is assigned to a student in a course by issuing a command,
GradeStudent(grade:string, enrolledId:string)
It’s so easy to come up with this because I just have to focus on immediate needs. There is no overall big domain model to consider. I am just interested in relevant events for the increment under development.
For each request I pick existing events to build context models from. Plus I design new events and relate them to existing events as I see fit.
Here are the events sufficient “to tell the story” of the increment:
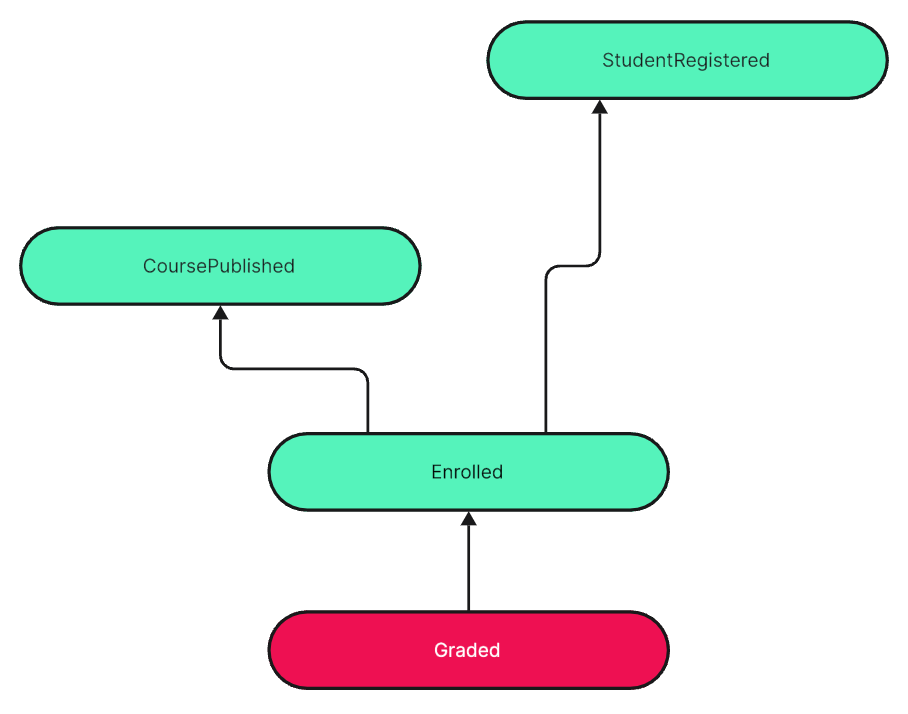
Do I have to be concerned about Entities? No! I pick my starting points for pulling event chains as I see fit. Starting with CoursePublished or Enrolled as dependent events is the same to me as starting with an independent event like TeacherSignedOn.
Every event in a graph is an equal starting point for “a good story”. None is predestined to represent an Entity. Entities are dead. Only events are left. And each is as good to relate to as any other. It’s a matter of relevance, context, situation, what’s fitting the user story best.
Commenting on grades
One last example of an increment. I’ll make it a quick one. I want to go beyond what’s already known about the example domain from the descriptions above. Surprising requirements are the most fun, aren’t they?
As it turns out grades often kick off a discussion about them between student and teacher. The application should allow for adding comments to a grade. Only the teacher who graded the student and the student are allowed to comment, of course. It’s not a public chat.
This time I want to focus on how this story should be told in the event stream. Which events already existing seem to be relevant? Which new events are needed for the job?
You might be tempted to think in nouns again and expand some domain model in your head. But try not to. Stick to what’s in the Event Store. Here’s a reminder with some example events:
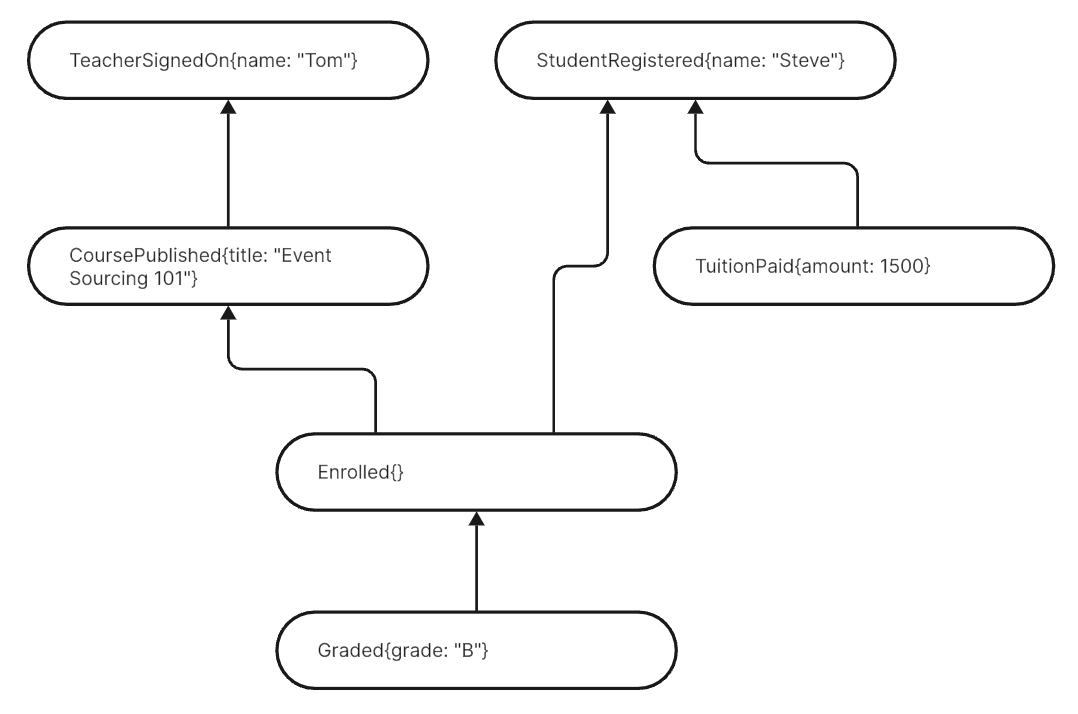
To this a chat between student and teacher needs to be added. But how? Should there be a new event ChatStarted? No, I think that would be a relapse into Entity-worshipping. I my mind it’s much simpler.
Why not append the comments to the Graded event? It’s the natural starting point. The discussion is revolving around it anyway; that should be expressed as straightforwardly as possible in the event stream, I think.
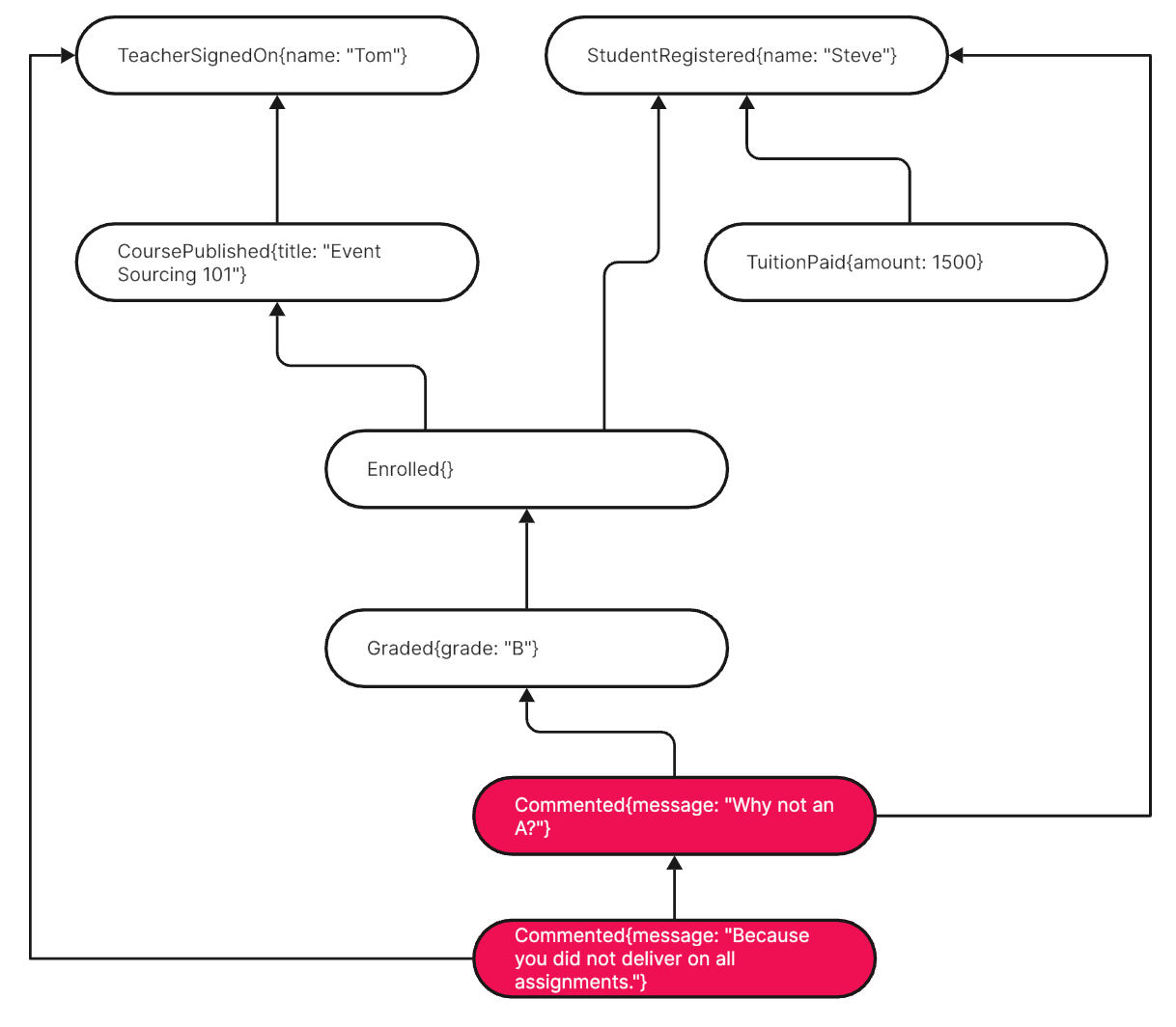
The first comment is directly referring to the Graded event which inspired it. All replying comments are referring to the comment they are a reaction to.
Alternatively all submitted comments could refer to the Graded event. The benefit of that would be an easier overview of all comments pertaining to a grade. Plus, the natural event sequence would not be replicated by comments referring to comments.
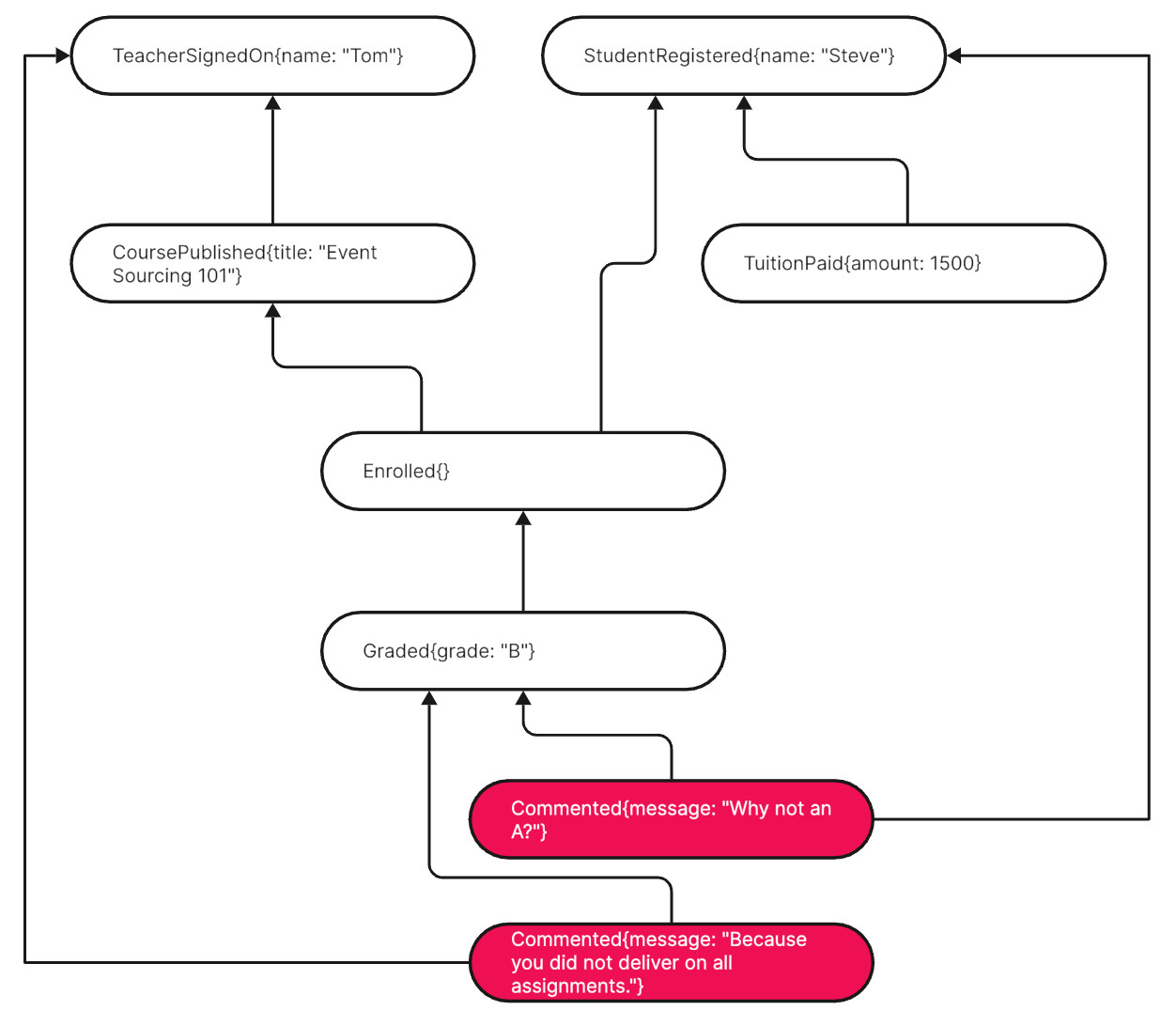
Doing Story Recording does not relieve you of all decisions. Even when not having your head in the clouds musing about Entities, but standing with both feet in the real stream of events, things are not always clear cut. Some guesses still have to be made. But I am convinced, they are fewer and they are better informed by facts — instead of being fiction.
Representing stories
After these examples I am sure you’re curious to see how to implement Story Recording. I’d love to tell you… but this article has grown too long already. So let me just say:
Story Recording can be implemented on top of CCC Event Sourcing. For overcoming your grief about the death of Entities and starting over with Event Sourcing with Story Recording glasses on, you don’t need to switch the tool.


I am not saying that’s perfect. But it’s ok to get started. Before building you next multi-million concurrent user web application the Agile way using Story Recording, get your feet wet with smaller scenarios. I’ll show you how in a future article.
For now let the above event graph be your takeaway: Event Sourcing is only, well, about events. Event referring to other events. Nothing else.
Don’t cry for the Entity
The Entity is dead.
But that’s no reason for despair. I even suggest to view it as a liberation. Think about how productive you can become with so much less big domain model design up-front! Think about how much more certain you can be about models you derive from facts in the event store compared to all the effort going into divination. You can keep your crystal ball in the drawer. Look at what’s present instead!
It’s so simple:
Every event gets an individual ID; it’s an event specific ID; it does not refer to anything outside the Event Store.
Events can refer to one, multiple, or zero previous events as a context for themselves. Not only the event type and the payload describe what has happened. Relationships to predecessors are valuable for the bigger picture.
The result of events connected in this way will be stories. They unfold as events happen on the basis of other events.
Technically this is (for now) not different from Event Sourcing so far. However, you need to use the means of Event Sourcing in a certain way.
The crucial twist killing the Entity is the absence of any notion of an outside world filled with structurally stable objects. Nothing in an Event Store references anything “out there”. Events only relate to other events as events.
From that any number of observers can make whatever they want.
How does that change your life? Immensely!
You no longer have to fear not knowing enough about the domain.
You avoid duplication of work: designing Entities with their relationships plus designing events. Concentrate on events only, cutting your work in half. At least.
You might need some time to wrap your head around this “interpretation” of Event Sourcing.
It took me quite some time. But it was an epiphany of sorts. I hardly could contain my joy after understanding the impact of consistently connecting events in this way.
I finally was able to kill the Entity.

Remember the endless discussion about normalization and denormalization of relational database schemas? They were a sign of conflicting requirements. A single model can by definition only be optimized for a single purpose. But sooner or later requirements are bound to diverge and create tension. With one ever constant requirement: flexibility due to uncertainty.
Except you’d switched from the verb “to enroll” to the noun “enrollment”. But who does that? Or if you start doing that, nearly every activity can become an noun and an Entity. That’s not the purpose of Entities, I guess.
In this text I am not using recognizable hash values for the event IDs for simplicity’s sake. And if you find it difficult to calculate a hash for an event, feel free to use UUIDs instead. Technically that does not make a difference for the purpose of referencing events. Conceptually, though, it’s weaker; the contrast to how Event Stores are used with Entities is less stark.
There is an added benefit of hashes: they make if (almost) impossible to manipulate an event store. Because if a hash is used to identify and connect events, then a change to the event’s payload would change its “address in event space”. All other events would need to be adjusted to still reference it. Which would change them and their hashes leading to further changes downstream. No, with hashes as IDs for events, Event Stores turn into records where all that has happened is “set into stone”.
Of course real authentication requires much more. But humour me for this example scenario. I don’t want to complicated it with security concerns and focus on domain functionality.
This was a great read. Inspiring and hit close to home. I felt like I needed to respond immediately because it resonates so deeply with the course we're on. https://thetimethatremains.substack.com/p/events-in-superposition
Hi Ralph, this was a very inspiring post. One question came to my mind when I've tried to model it. What is your idea to keep the related event references around so you can correctly pass them with newly triggered events? Do you think keeping them in a session context? Or propagate into read models so for example when I press the button on a screen, I thread it into the command and later to event? Thx.