

Agile software development hasn’t been agile so far. Could not have been despite all desperate attempts. The simple reason: there are no matching software architecture patterns.
That’s a bold statement, I know. But let me explain. I think it’s very simple to understand:
At the heart of agility is the insight that software solutions cannot be fully designed in advance and then simply implemented. BDUF (Big Design Up Front) does not work. Requirements are never completely known; they evolve alongside the code, as interactions with existing code inspire new behaviors and additional features.
Requirements can never be fully analyzed up front.
Solutions cannot be designed to cover all requirements from the start.
Solutions cannot be implemented to satisfy all requirements at once.
Development focuses on the early, continuous, and rapid delivery of value—this is known as incremental, iterative development.
Requirements are divided into increments, meaning small, manageable scopes that aim to deliver value as soon as they are implemented.
Each increment cannot be expected to be perfect from the outset; therefore, each may need to go through several iterations.
It is unrealistic to know all increments in advance. Thus, discovering and implementing increments is itself an iterative process.
As valuable as this realization of Agility was compared to earlier approaches to software development, Agility falls short when it comes to implementing increments. The problem is that increments are not represented in the code —they disappear as soon as design begins. On a Scrum or Kanban board, developers can point to an increment, but in the code, there is no way to say, “There it is!” Increments dissolve into the code during design and implementation, like sugar dissolving in a cup of tea.
Increments necessarily get assimilated into code. Resistance is futile. And this has several detrimental effects:
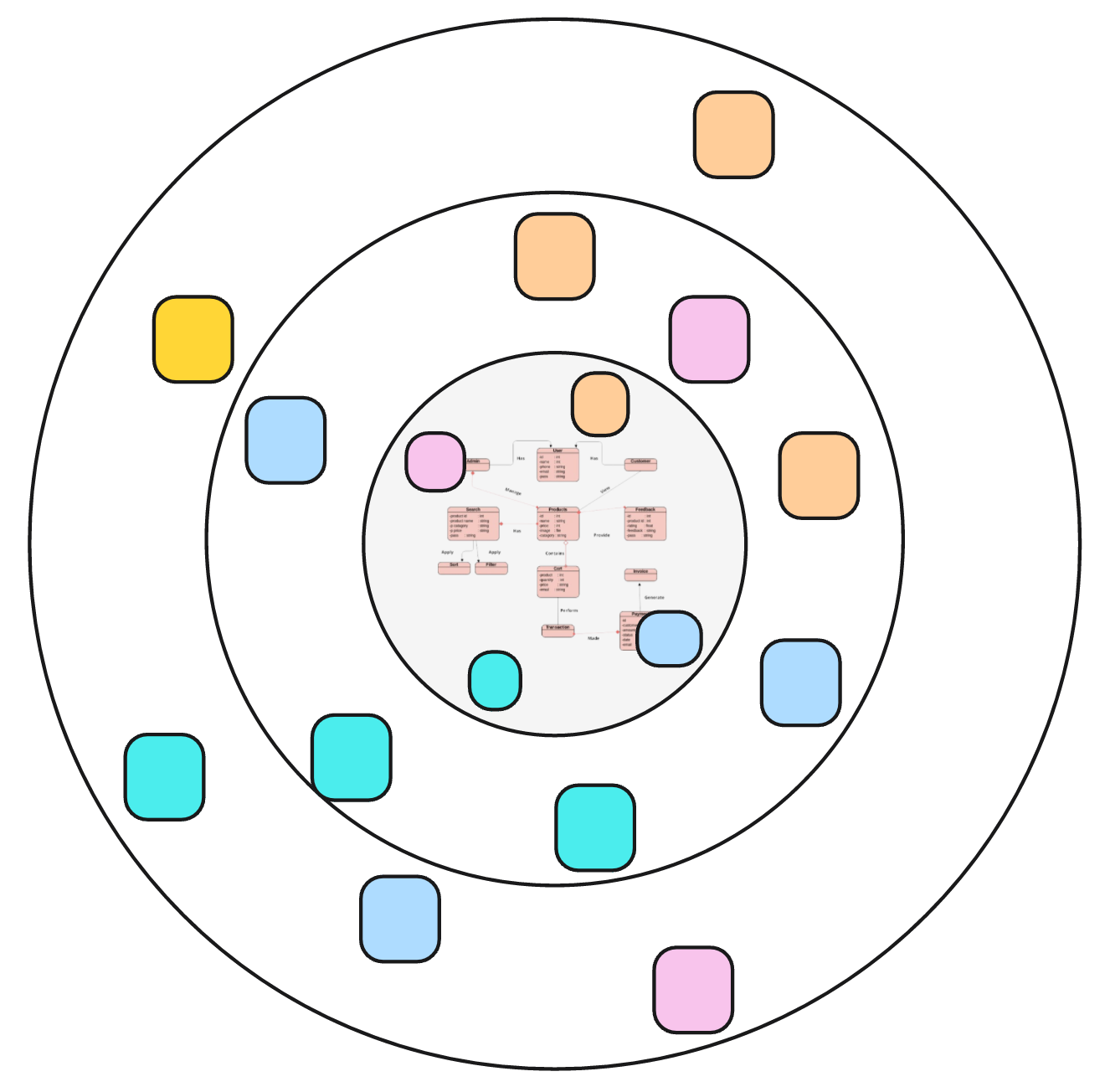
If a change to an increment needs to be made, it can hardly be localized. The increment’s code is scattered across the code base.
Increments cannot easily be replaced once changes become too hard to make in place. Restarting with a “green field” is not possible for an entire solution, nor for a single increment. This leads to code bases becoming harder and harder to understand and update.
Developing increments in parallel is hardly possible because their changes to the code base might interfere with each other. The potential for productivity gains promised by Agility is therefore limited.
But what is the reason for this inevitable assimilation? It’s the basic architectural patterns that software is based on today: the Layered Architecture (LA), the Onion Architecture (OA), the Hexagonal Architecture (HA), the Clean Architecture (CA). Especially the latter two are still much hyped, despite their failure to truly support Agility.
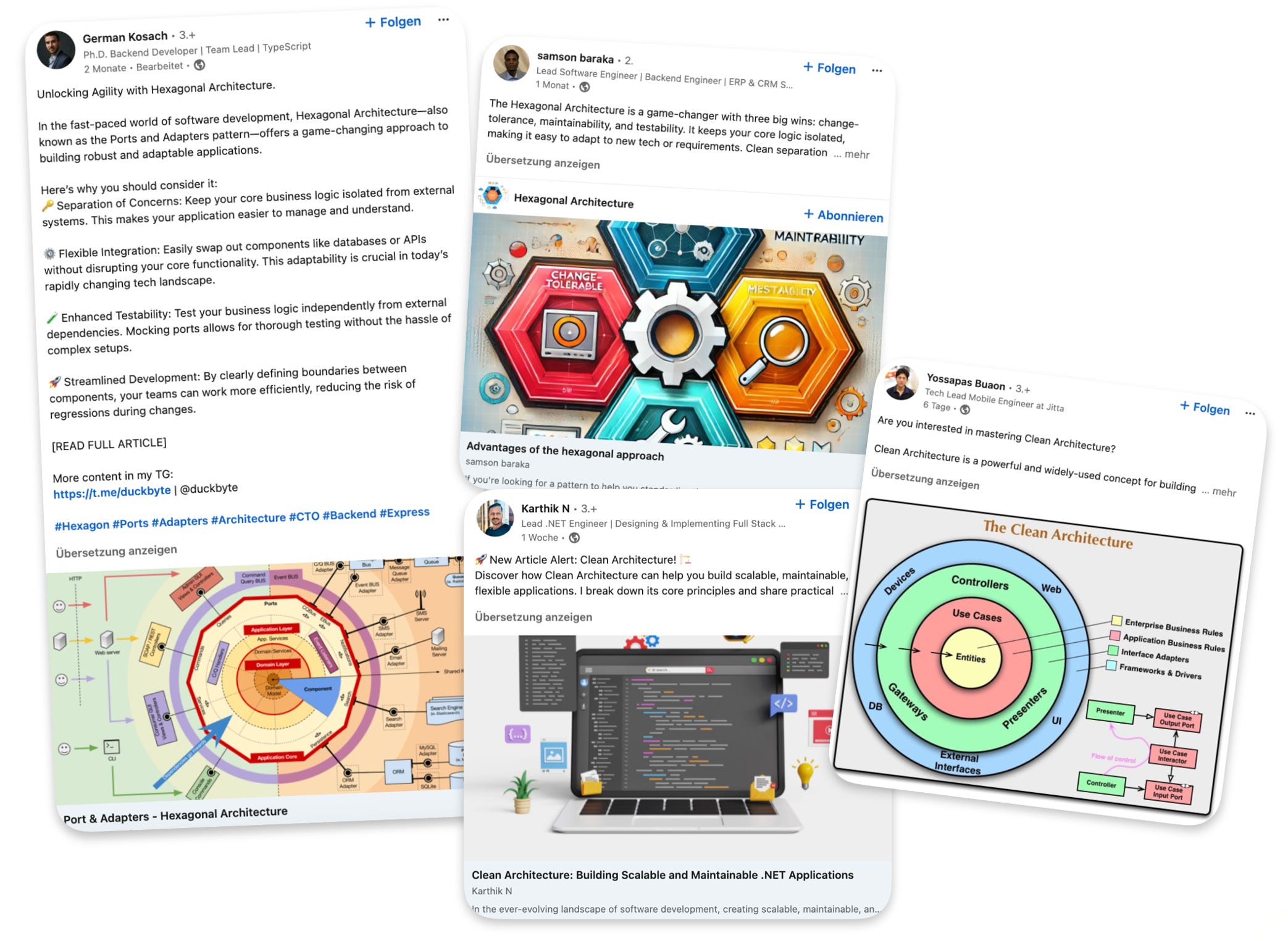
Agility stops at current software architecture because current patterns do not represent increments. It’s that simple.
There is no notion of an increment or feature in LA, OA, HA, CA. What they represent always is the whole of all requirements present and future.
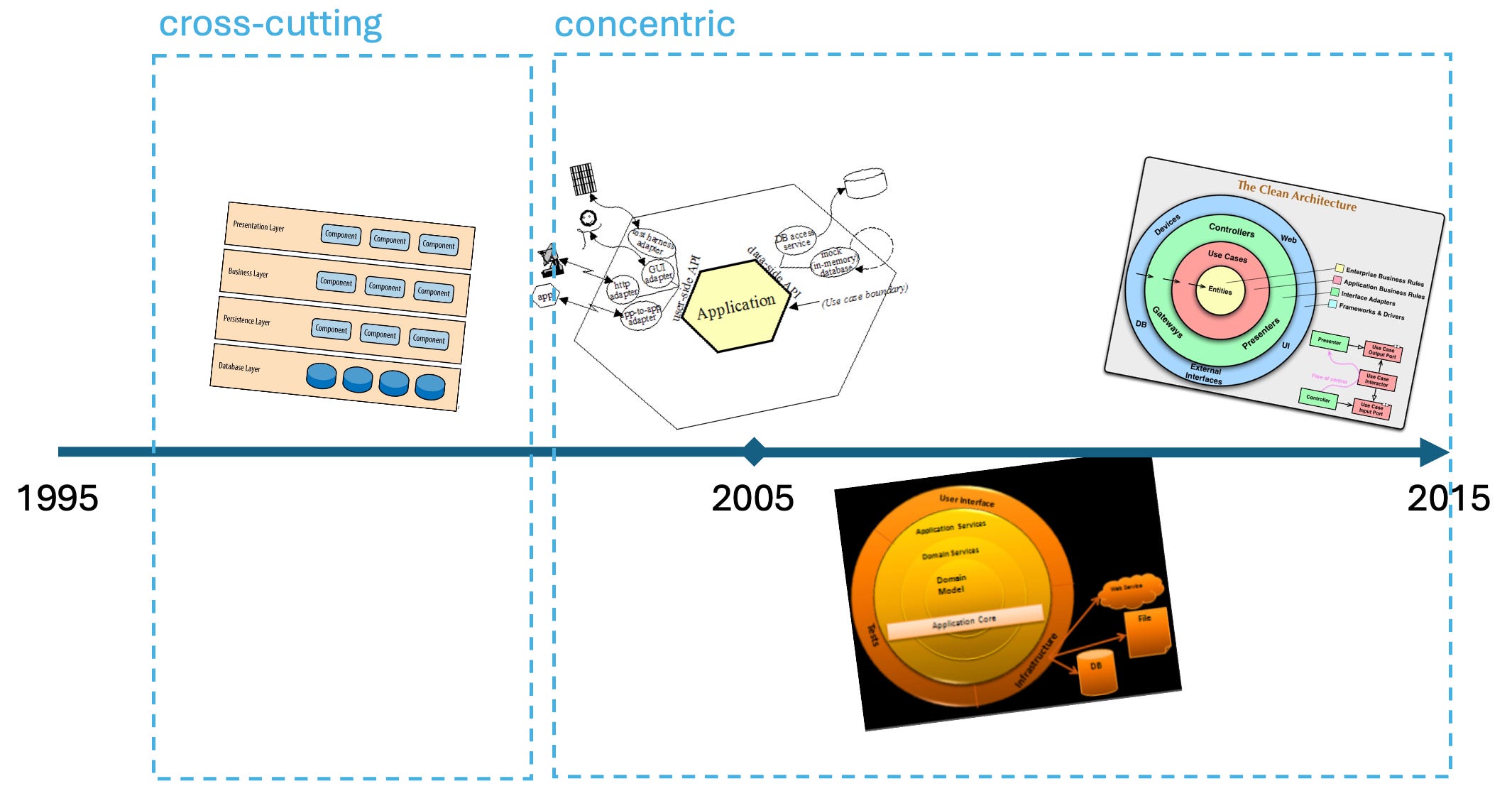
What these architectural patterns are concerned with is a “good” separation of concerns (SoC, modularization) and “good” dependencies between them — meaning non-circular and easy to test.
Over time, the view of what “good” means has changed, of course. There has been an evolution of architectural patterns, starting from the late 1970s (MVC) up to 2012 (CA). But across all of those generations of patterns, two aspects haven’t changed:
the focus on concerns, which is driven by technical considerations
the connection of concerns by way of direct usage relationships based on functional dependencies
The second is rooted in the first: Where modules are containers for code in need of help from others, it seems completely natural to let one call the other at runtime. Modules depend on each other. Each contributes to the overall behavior with its own logic and also delegates work to others. Together, all modules are responsible for delivering on all of the requirements. This happens across increments.
That’s why, to me, SoC-based architectures are primarily technical. They are concerned with separating certain cohesive logic for easier testing and easier adaptation, but still, this does not have anything to do with increments. The neutral concept of a module is used for a technical, cross-cutting segregation of logic. The code for each increment is scattered across many modules, with each containing code contributing to many increments.
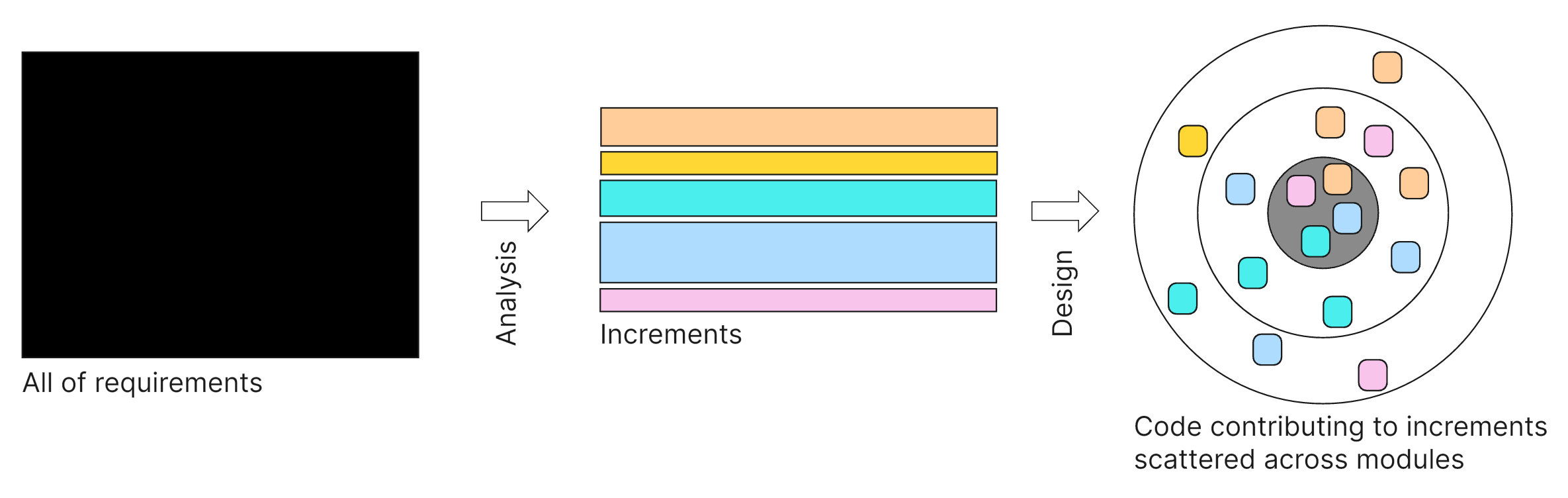
The notion of an Agile increment is gone once it’s been manifested in code.
That’s why, to me, Agility did not and could not deliver as promised. It’s just not compatible with established and older architectural styles, which are rooted in a very different approach.
Agility was able to convince developers to give up the proverbial BDUF in favor of incremental progression.
Agility, however, was unable to convince developers to give up the single model, the single schema at the heart of their solutions. Mainstream object-orientation (OO) from the early 1990s on, and then 10 years later Domain Driven Design (DDD), perpetuated the notion of a single central “data structure” to represent all “stuff” a software has to deal with.
Developers were and are still trained to spot distinct objects “in the world.” When presented with a problem domain, they immediately set out to hunt down “entities” and represent them once and for all in a stable data structure serving all kinds of requirements, known and not yet known. That’s the holy grail of “domain design”: distill the “domain language” and then design a (read: single) proper “domain model” for it.
The contribution of DDD to this is mixed, in my view:
The good: It cautioned developers not to go overboard and try to fit everything into just one domain model, but to distinguish several, maybe related and similar-looking ones, each pertaining to a “bounded context.”
The bad: It emphasized the importance of a proper domain model inside a bounded context by prescribing distinct object categories: value object, entity, aggregate.
The one-model-fitting-many-increments approach was not overcome even with DDD. And after that things did not improve with HA, OA, CA.
Until… yes, until the Vertical Slice Architecture (VSA) in 2018 by Jimmy Bogard. It’s depiction is still crude, but the idea is right:
“In this style, my architecture is built around distinct requests, encapsulating and grouping all concerns from front-end to back.”, Jimmy Bogard

There it is: the increment is entering the architectural picture. Jimmy uses the word “request”, but since then the term “feature” has acquired more popularity, I think.
A feature — a scope increment — is represented in code by a distinct structure, a “slice”. A slice contains all the code required to deliver on the feature:
“Instead of coupling across a layer, we couple vertically along a slice. Minimize coupling between slices, and maximize coupling in a slice.”
The increment stays visible in code. Increments are decoupled in code and can be easily developed in parallel (which is a boon in times of AI).
I don’t think the LA behind the slice in Jimmy’s depiction should be taken too literally. It’s just to show that a slice covers many concerns; it creates cohesion among concerns while decoupling them from other slices.
Slices are vertical, layers are horizontal. Slices have turned software design around by 90°. The focus now is on increments all the way down from analysis to code. One slice pretty much does not care about other slices.
That’s the beauty of it. That’s why, to me, this is an architectural pattern fitting Agility. Finally.
But there is a catch!
By slicing through requirements, VSA is also cutting through the cherished single model of a bounded context (however large that might be).
A VSA is not compatible with a single model. A single model would extend across slices, thereby negating their attempt at decoupling.
A VSA is not compatible with a single model in-memory (object model) or a persistent single schema store.
In a VSA, entities or aggregates with the same comprehensive structure to hold all related data to serve all kinds of requests don’t have a place.
Thinking up the single model while trying to move forward in an Agile way is not possible. It’s a paradigm mismatch.
But slicing through requirements in an incremental way and then implementing those slices one by one (as independently as possible) — that’s a match.
What does that mean for data models? There is not just one, there are many. And they might look very different. Each slice can have its own model, its own view of the data common to all slices.
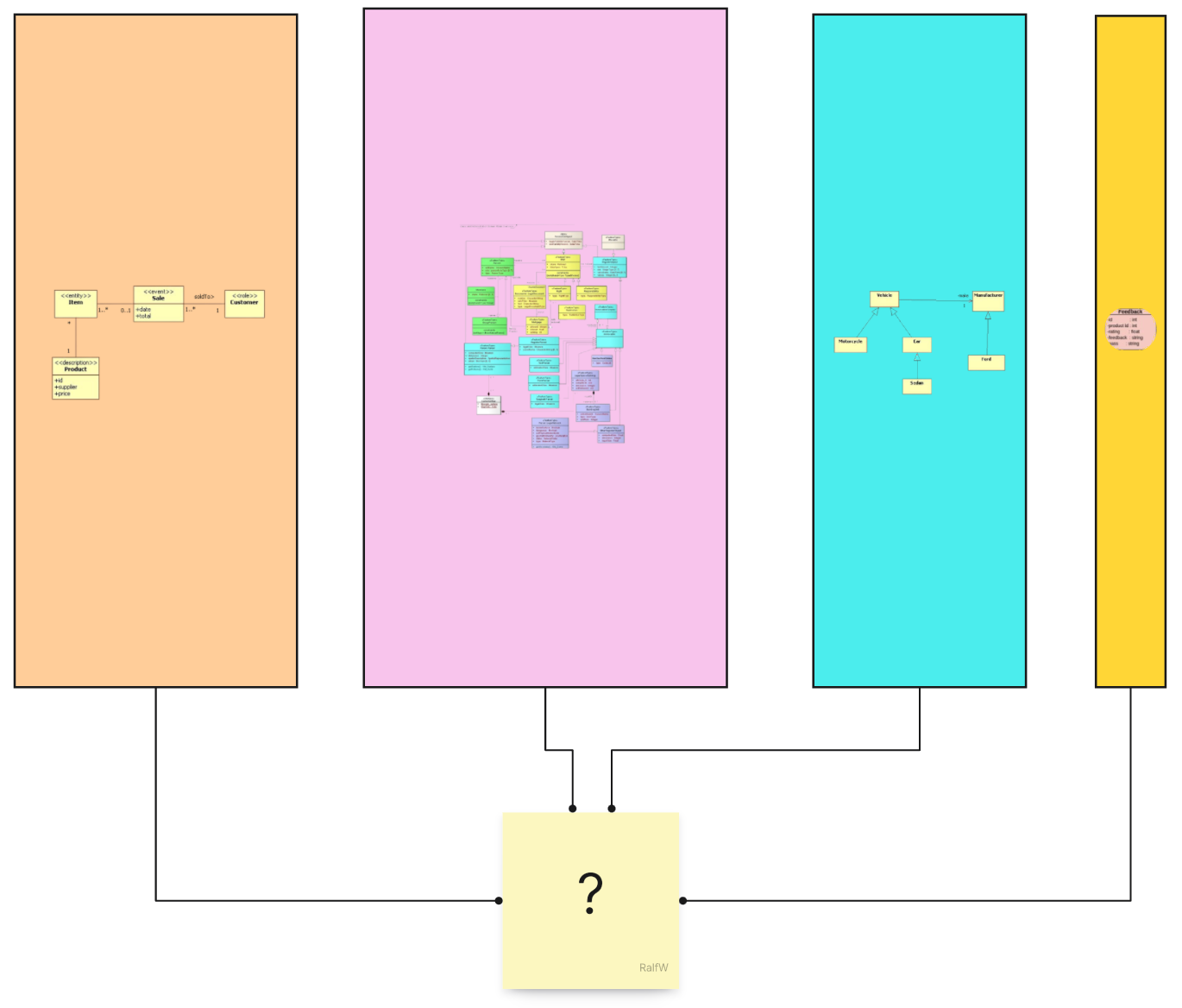
Yes, of course there is data common to all slices. It’s the state of the application. Usually it’s kept in a database: an RDBMS or No-Sql, whatever floats your boat. There are many ways to store the application state; what they all have in common, though, is the one-size-fits-all schema.
A big schema ruling over all data. That’s the norm. It’s very important to get this one schema right. Because it’s supposed to serve many different, yet unknown increments. That’s why the domain language is doubly important! The domain language is telling the tale of all the “stuff” in the domain and how it’s related. Developers must get that right to derive the best abstraction from it, the domain data model.
This is a very old challenge. It’s behind the different relational normal forms. Only if the data schema follows the DRY principle inconsistent state changes can easily be avoided.
But then reality hits the beautiful single schema. As it turns out over time, not all increments benefit in the same way from the single schema. That’s why denormalizations are introduced over time. Or databases are “enriched” with different (dynamic) views of the single schema.
A lot of effort is invested in SoC architectures to fit the single model to different scenarios/use cases/features. But the premise is never questioned: Should there be a single schema in the first place?
The answer given by the VSA is a resounding No! A single schema is hard pressed to serve all the different slices added over time to a code base. No one can foresee what kind of data model is best for the next and the next feature. It would be a futile attempt and an premature optimization to find such a single schema for a single persistent data source for the application state shared by all slices.
But what’s the solution?
Event Sourcing is.
Event Sourcing does away with the single persistent schema. It does away with the single semi-static structure for the current state of an application.
In Event Sourcing the single data structure is replaced with a single data stream.
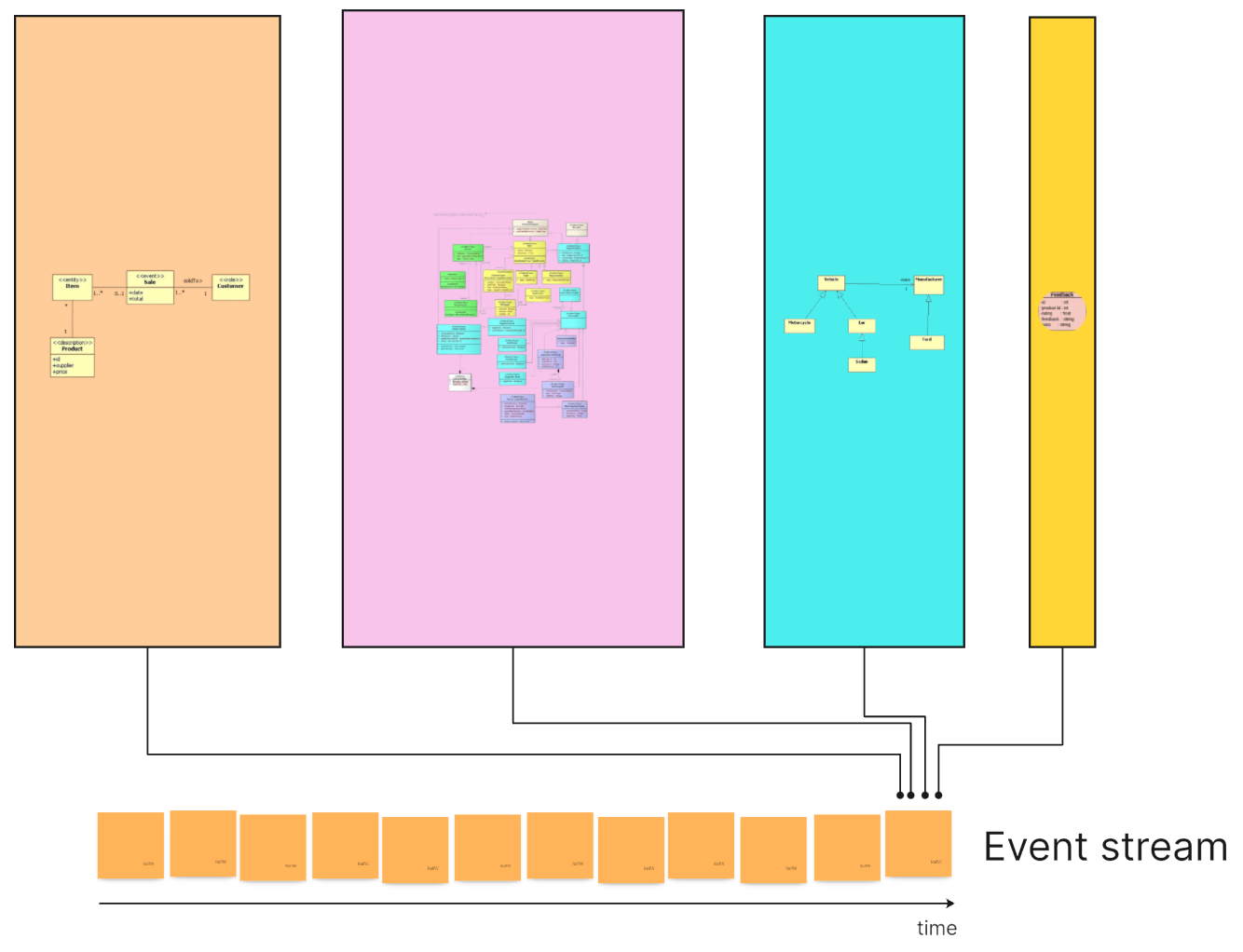
The event stream is a trivial Abstract Data Type (ADT): it only allows change by appending new events and reading events from older to newer.
All events have the same structure:

The event type denotes what has happened that was noteworthy.
The payload is an event type specific data structure. There is hardly any constraint to its shape. Whatever seems interesting to remember about an event can be put into the payload.
The event stream records, well, events, i.e., whatever happened in (or to) the application. It’s a logbook of facts created by decisions made by the application’s logic. Events describe differences in the state of the application.
A trivial example is this stream of events from older to newer:

Some data might be common to many, even all, events.
Some data is specific to some events, maybe just one event type.
It’s up to the application designer to come up with the events best matching what’s going on in the slices of an application. And that’s what all slices then share: the event stream and the knowledge about the different events.
The event stream is not a big data boulder heavily lying in the stomach of an application. Rather, it is a fine-grained pool of clay which can be sculpted into all sorts of data structures as needed by the slices.
That’s the beauty of the event store: it’s a record of all small changes to the application state from which slices can ladle whatever they need whenever they need it. It’s like the flight recorder in an airplane., the black box.
Events are just data. There is no suggestion in them as to if and how objects should be built from them by slices.
O/R mappers are often used to load parts of a persistent data model into an in-memory object model. The persistent schema and the in-memory object data structure mirror each other.
Working with event streams turns this on its head. Events in the event stream are not looking like anything slices are interested in working with to do their job. Events are “empty”, neutral, requirement agnostic. They can be understood as “pure potential” for any kind of data structure slices feel comfortable with.
Hence a slice does not “map” events to anything, but rather “projects” relevant events onto structures to its liking. It’s a constructivist view of the data world.
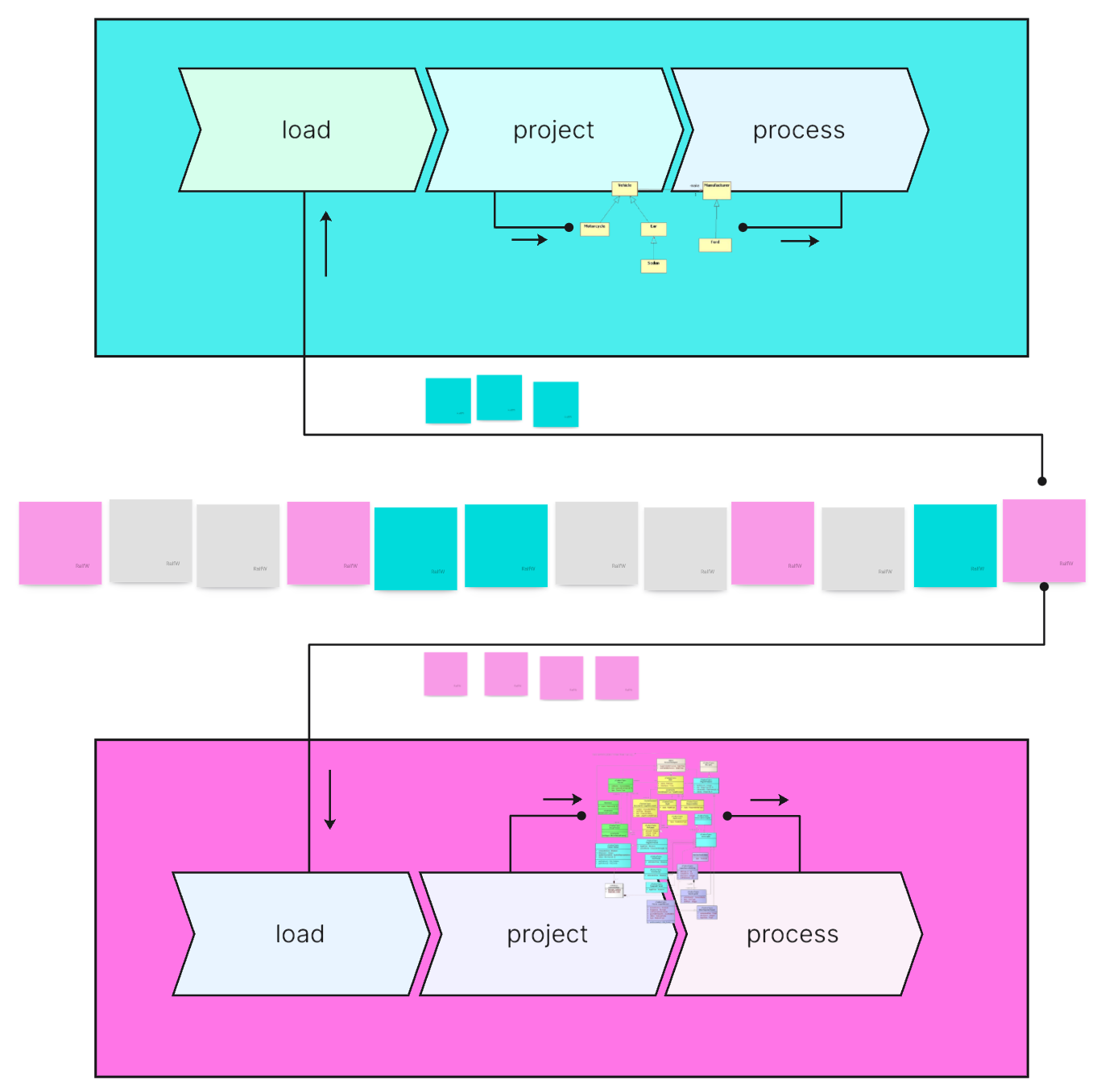
Why is does this make such a big difference for Agility? Hasn’t the single model been replaced with a single set of event types? Don’t all event types better be defined up-front?
No, the event types of an application don’t have to be defined as early as possible. They can grow incrementally. Yes, each one has a tiny schema of its own. But that’s nothing compared to the usual big schema of the single data model. If need be, event type schemas can also comparatively easily be changed/versioned.
The fine-grained nature of the event data structures (payload) makes it possible to flexibly create new molds to pour the data into, following the meandering flow of requirements.
This flexibility allows for maximal decoupling of the implementation of larger and smaller requirement scopes. Slices are no longer bound to a single model of reality aka state of the world aka sequence of events. Each slice can have its own interpretation and model of facts — within the boundaries of “common laws”.
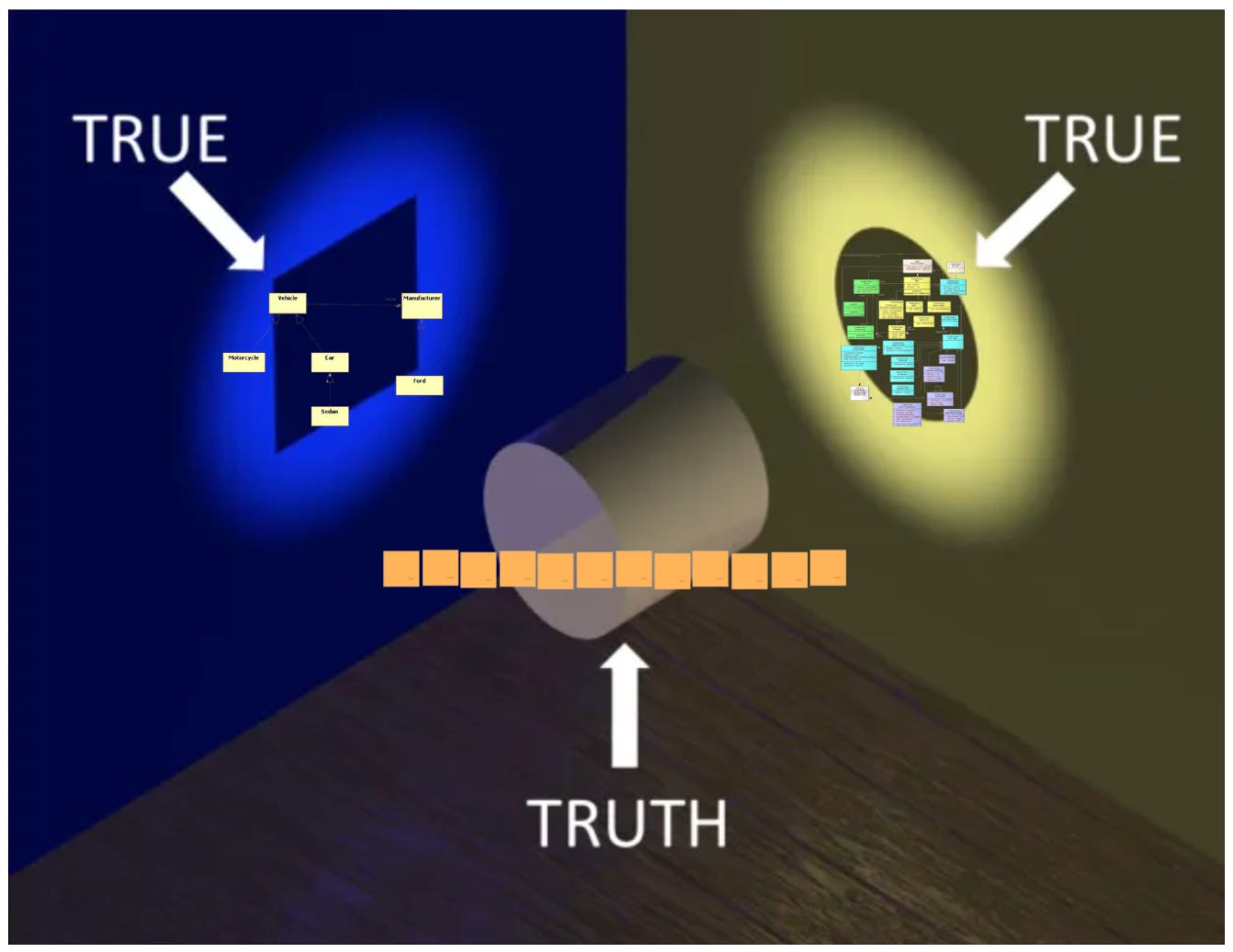
Requirements analysis can flow freely wherever it sees the greatest need. It’s no longer weighed down by petty concerns of coding paradigms. Or at least much less. A slice with its relevant events is such a smaller and decoupled scope that many problems usually bothering software development pretty much evaporate (e.g. following the DRY principle, striving for re-use, testing against databases).
In fact, the whole heavyweight question of persistence and the database becomes almost obsolete. An event stream can be implemented with very simple means on very ordinary RDBMS, which then basically no longer need to be touched. A single table with four columns (event type, payload, sequence number, and timestamp) is sufficient. There are no relationships, no stored procedures, no schemas to maintain. The burden of data processing is shifted to the logic and in-memory, where it is easy to test and simple to change.
Maybe now you understand my bold claim at the beginning. Agility could not deliver as promised. A suitable architectural concept was missing. And that required a rethinking of data storage and data models.
With enough processing power and practically unbounded persistent storage the situation has changed in the past years, though. We don’t need to store data as compact as possible as a single copy anymore; we can keep every change happening to it forever.
This allows us to get rid of large central data structures.
And that frees us to finally progress incrementally through requirements and keep them in code. That way code will be easier to reason about, easier to change, easier to test, and easier to work on in parallel.
Welcome to Agility as it was meant — thanks to Event Sourcing.
Very nicely written! I discovered VSA at the right time just before a new big project started. Initially wanted to hop on Clean Architecture but then changed my mind. That decision paid out very well.