

Productivity in the face of ongoing change is the fundamental challenge of software development.
And like the gods of ancient Greek mythology, it spawns further challenges, e.g. correctness and testability.
How has software development reacted to these challenges? With a flurry of technologies (e.g. compilers, languages, IDEs, test frameworks) and paradigms (e.g. object-orientation, agility) and concepts (e.g. modularization, patterns, TDD). It’s on a constant hunt for better ways to become and stay productive.
However, in my view, the original approach to increased productivity has been pretty much neglected. Since Frederick P. Brooks said “adding manpower to a late software project makes it later,” division of labor — aka adding people — has fallen from grace.
Instead, the mantra has become: build software from reusable components.
And who would blame software development for that? “Reusable components” like Lego blocks sounds just right. Isn’t standardization and reusing the same building blocks in a multitude of different products at the heart of the industrial revolution?
But, alas, I think it’s a trap. Software development took the wrong turn. What it created is a road made of quicksand: it looks easy to travel, but as soon as you step on it you sink in and get sucked in further the harder you try to escape it.
The reason? Reuse creates dependencies. Dependencies require stability. And stability is like a piece of soap you want to grab with wet hands in software development. Everything is in flux all the time.
In addition, finding stable islands that promise reusability requires quite some effort. And then even more effort to ensure stability as much as possible for all dependent parties.
No, reuse — which was especially promoted with object-orientation — is the wrong approach for increasing productivity. At least for most projects most of the time.1
The units of reuse are modules. Modules can be an object-oriented class or a library or a service. Technically it’s great to have modules. Sure, we want to be able to wrap code behind interfaces to hide details. What doesn’t work, though, is to start hunting for modules of all sizes when faced with requirements. It’s a premature optimization born from the wrong analogy: software development is not like industrial production or construction work or even landscape gardening.
Customers simply are not concerned at all with modules. They are concerned with… functionality. The structure in code matching this concern is not a class, but… a function.
How does that help becoming more productive?
First of all, functions are the units of code which can and should be checked for correctness. Functions are the natural containers for logic which is actually creating most behavior of software.2 To verify the behavior of software, these functions have to be designed so that testing them is easy. High testability is a matter of how functions are structured.

Secondly, functions are the way to build functional abstractions (aka compositions) to make functionality easier to use and understand. Building software from layers of abstractions (stratified design) is a productivity booster.

Thirdly, a user triggers functions when interacting with a software. A button or menu item (or anything with an event handler) on an user interface are just a means for humans to call a function. Humans are notoriously unwilling and/or unable to call functions directly by passing in parameters as JSON data and interpreting JSON results delivered by functions. Hence they need user interfaces as thin layers on top of very high level function calls.
These functions triggered by users are the entry points into the logic creating the desired behavior. They are the roots of deep function trees across which this logic is placed, scattered, smeared.
It’s functions to look for in requirements analysis to quickly deliver working software.
Customers and users are not concerned with modules at all. They don’t see a code’s structure. But they “feel” functions made available to them through triggers. When they demand more functionality they essentially demand more functions. Whenever such a function is put “at their fingertips” — directly or indirectly — through a button or menu item or some other means of triggering it, then that is, for them, a sign of software development’s productivity. And the more functions we can put “at their fingertips” per unit of time the more productive software development is.
Where does that leave modules? At least not at the top of the list of productivity concerns.
If software development wants to increase productivity it needs to find a way to churn out more functions per unit of time containing logic making a positive difference in the behavior of software.
More functions, not more modules!
And more functions “at the fingertips” of users, not modules!
How can that feat be accomplished?
My suggestion is… division of labor. Yes, you read that right: division of labor as in adding more manpower to a software project. At least in principle.
But this manpower must neither shoot itself in the foot nor step on each other’s toes.
To increase productivity all manpower needs to be employed in parallel (!) as much as possible.
Yes, I know that’s contrary to what pair programming or mob programming are promoting. And I am not against those venerable practices. But I would like to question some premises they are based on:
code is written by humans
code once written has to be improved; it hardly ever will be thrown away and rewritten
code must always follow the DRY principle
code in all parts of a software is connected in complex ways
Does it really have to be like that? No! It is not like that anymore already thanks for generative AI. And software development should find ways to get rid of the other premises:
code now is not written by humans anymore; it’s written by AI in growing amounts
changing code to adapt it to new requirements so far seemed inevitable; there wasn’t enough time/manpower to rewrite it. The green field every developer loves is almost mythical. Few have ever had the privilege to work on it. Most developers are hired to shovel mud. But with AI this should change. Coding competence now is cheap. So, why not rewrite code? We have to find ways to structure it for rewriting first.
the DRY principle makes sense in a world of manpower scarcity. But with AI software development can care less about writing logic only once. Yes, consistency is still an issue. But so is productivity. “Coding agents” working in parallel may well generate similar code to solve similar problems completely independent of each other if that’s faster than syncing efforts by up-front design and communication.
if connecting code in complex ways to achieve DRY and reuse is hampering productivity, then DRY and reuse might need to be dropped to increase it. Why not “wet” code which cannot be reused and is independent of each other and can be thrown away and rewritten easily, if that boosts productivity through division of labor?
As far as I can see, division of labor hasn’t been on the radar of software development much. Sure, it happens de facto. Modules, after their interface specification, can be implemented in parallel. But which project actually does that? Mostly a kind of multi-tasking is employed: the same developers continuously jump between different modules they are implementing all themselves. Everything is in constant change — with the well-known effects. No small wonder, mob programming got invented to minimize conflicts.
Likewise it’s no small wonder that the popular software architectural patterns — Layered Architecture (LA), Hexagonal Architecture (HA), Clean Architecture (CA) — are not supporting division of labor. I’d even say: they are not supporting productivity in any particular way.
But what about the DIP in HA/CA? It seems to support testability, but at a huge price: complexity is increased. The reason: functional dependencies are not questioned. This only does the IODA Architecture (IODA) by removing them altogether. But IODA, too, wasn’t invented with division of labor in mind.
When asking for a solution the saying goes “It depends…” is the right answer. And there certainly is truth to that. But then… some things still don’t seem to depend. They are taken as a given. They seem like natural laws or axioms.
One such given is the von-Neumann architecture for computers. Who’s questioning that when implementing the next application? The von-Neumann architecture is set and solutions have to be found within its constraints. Nevertheless there are alternatives to the von-Neumann architecture. In some scenarios they are better suited.
Another such given is the CRUD architecture. It’s the paradigm underlying all architectural patterns from MVP to IODA, i.e. the patterns of the past 50 years.
CRUD means: a single data structure on-disc (and partly in-memory) is used to keep the application state. This data structure is changed (CUD) and read (R) to serve the user. Only the current state of data is kept around at all times.
This is a tried approach — with all its benefits and also disadvantages. Of which the most prominent one is being a shackle on the feet of developers. It makes them slow.
Reuse, i.e. using what others are using too, is not an option but mandatory in these architectures. All parts of a program must rely on the same ever more intricate data structure of the single, central model.
This single, central data structure — on-disc and in-memory — has to serve all purposes. And if it doesn’t out of the box, then it needs to be projected into a different data structure (view). But preferably not. Projection should be the exception. It’s considered a burden. And it’s a deviation from the truth, from reality. Because that’s the claim of the single, central data model: to model reality as found in the world of the users during requirements analysis.
Isn’t that even beautiful? What a philosophical approach to software development! Doesn’t that sound like how Platon envisioned the world? Software architecture backed by the big minds of ancient!
Well… I’d like to chime in. But the reality of software development is harsh. It’s about what works and hits the road fast, not “head in the clouds”. Hence I have to disagree with developers-turned-philosophers. This kind of thinking does not cut it when it comes to speed, to productivity.
Plus, it’s not how human minds work. That’s an insight of (neuro-)psychology. Human minds (or even the minds of all living being as far as we know) do not discover reality and rebuild it “in our heads”. Rather models of reality are constructed. It’s only models and they are all different because constructed from individual points of view even though rooted in the same basic facts.
Different viewpoints, different models. That’s how humans work.
And all models are tailor made to serve a very specific purpose. Flies, cats, bats, humans all have very, very different models of the same reality — which is beyond their understanding. Even physicalism (or materialism) do not describe reality but are just meta-models of it.
No CRUD model for software development thus should call upon “matching reality” as a quality criterion. It’s not. “Matching reality” is not helpful per se. Helpful is whatever makes software development more productive (while not compromising code correctness).
Model, data structure, that’s all secondary. Primary is a code structure supporting productivity. That means, a code structure allowing division of labor aka scale-out.
Serving more concurrent users has long been achieved with scale-out instead of scale-up of computers. So, why not serve more requests for functionality (implemented using functions) also with a scale-out approach?
How would that look? The basic answer is given by Agility: A software architecture geared towards productivity is one based on increments. Increments would need to be the basic structural units. Increments, not components (aka reusable modules).
As long as increments do not require other increments to be in place already they can be implemented in parallel. That’s part of their very definition.
This also means, increments by nature are… independent. They do not use each other. One increment is not at the service of another. Increments don’t call each other like modules do. However, increments might rely on effects of others. Increments are all working on the same basic state; the facts they rely on are shared.
One increment might need to be implemented first to create state another requires as a prerequisite. But that’s very different from one module needs to be implemented for another to call it. Sharing state is different from sharing functionality.
Increments are the natural results of Agile requirements analysis. They are inevitable. That makes them different from components (as modular building blocks of code). Components are not a matter of inevitable analysis but optional design.
Let me be blunt: design is waste in the Lean sense. It’s waste like communication. It does not add value in itself. The next increment implemented is adding value, but not the next component.
Design might be necessary like communication, though. I’m not denying that. But it should be kept to a minimum. As little as possible design, only as much as absolutely necessary.
But if increments can be mapped to code… then analysis is doing what design usually does: it’s defining structure.
That’s what the SRP always was about, too: every decision spotted during requirements analysis should be mapped to a structural element in code. The structural element then has the responsibility to enforce the decision at runtime.

Increments are decisions, too. They deserve their own structural representation. Increments stand for the decision “This creates value!”.
What to make of all that?
Let me suggest the following for now:
Make the separation of increments the fundamental structure of an application.
Go through requirements analysis the Agile way. Identify increments. Map each increment to an independent unit of code. Implement each unit of code separately from all other increments as much in parallel as possible.
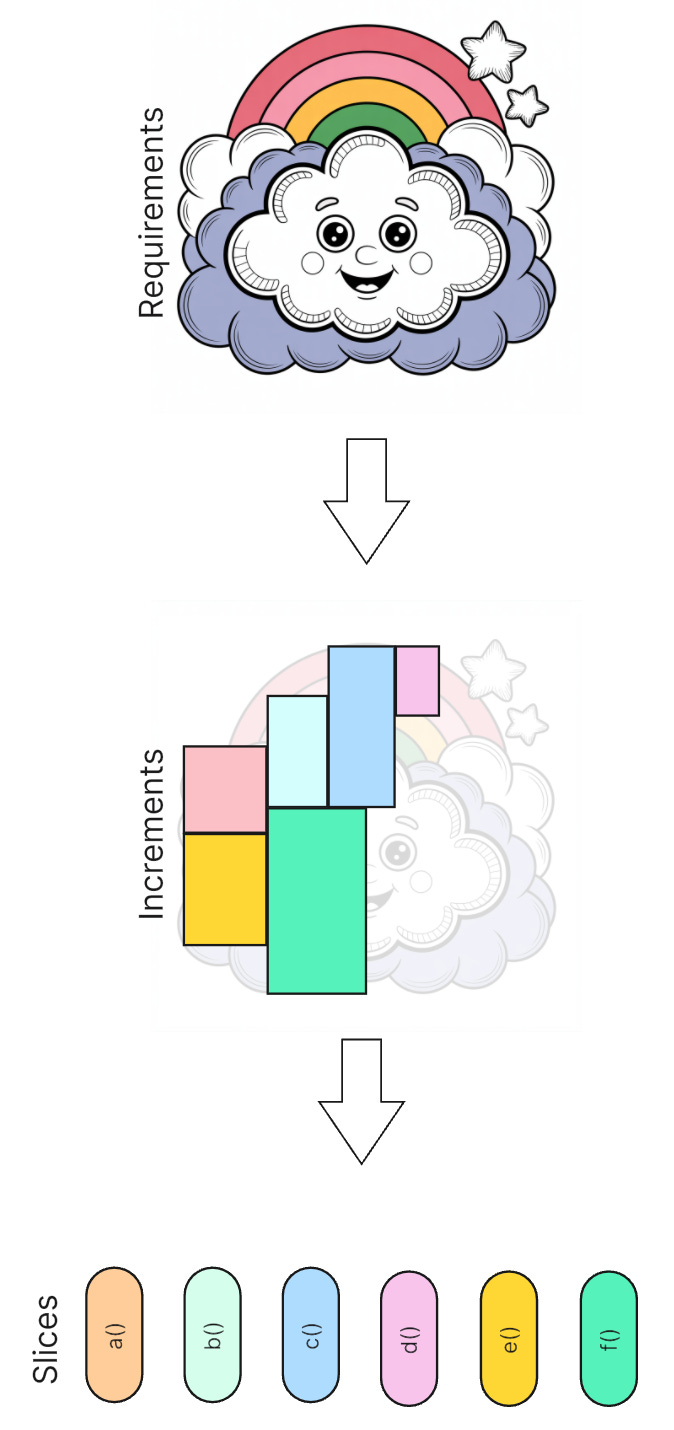
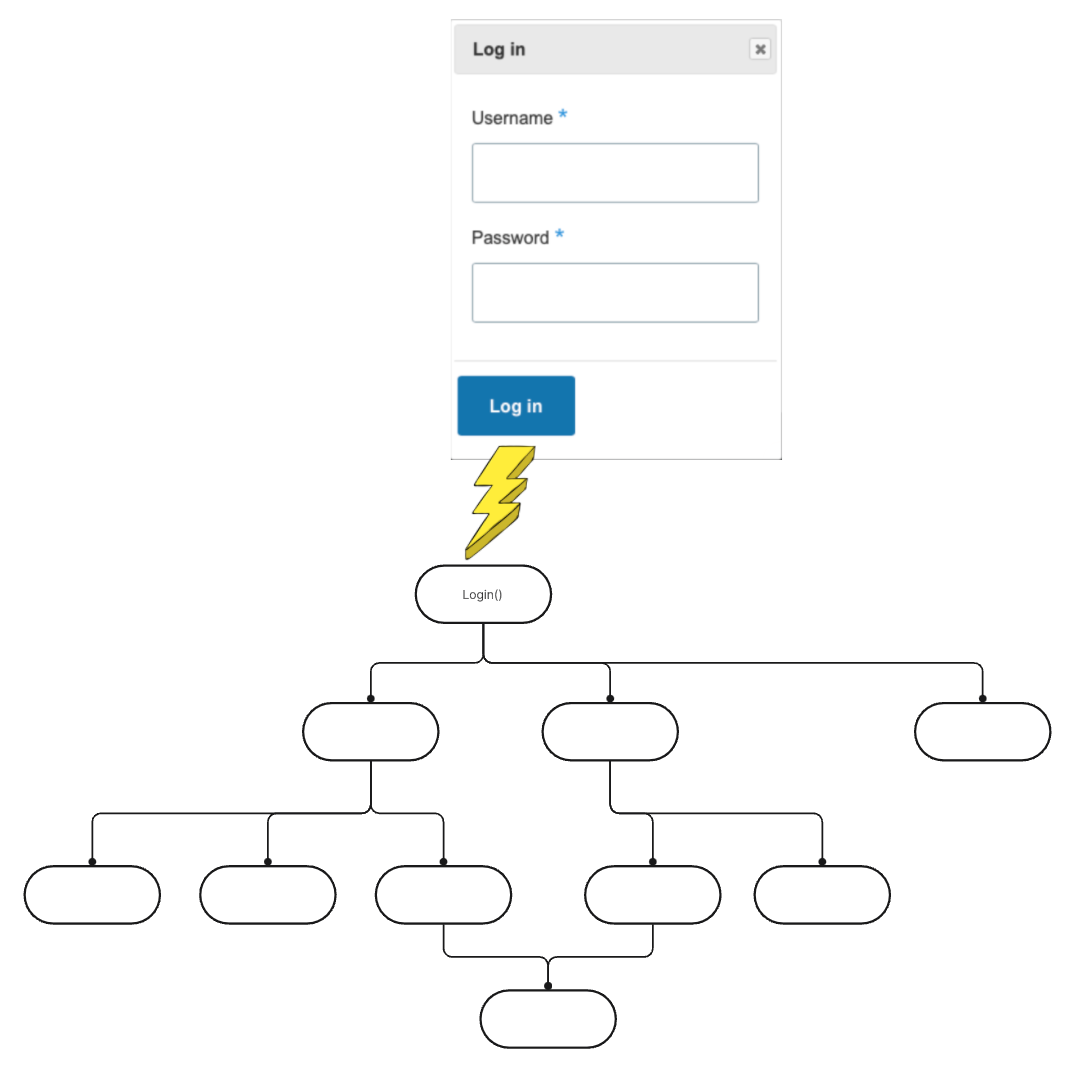
The implemented increments I call slices for now in accordance with the Vertical Slice Architecture (VSA). But let me be more specific than the VSA:
each slice should be understood as a hierarchy of functions with an entry point function at its top, and
all slices are accessible through the same user interface which is wrapping them up in an easy to use way. (Remember: users are not inclined to enter or interpret JSON or XML and call functions manually; they demand buttons and menu items and data entry fields and tables, animations even…)
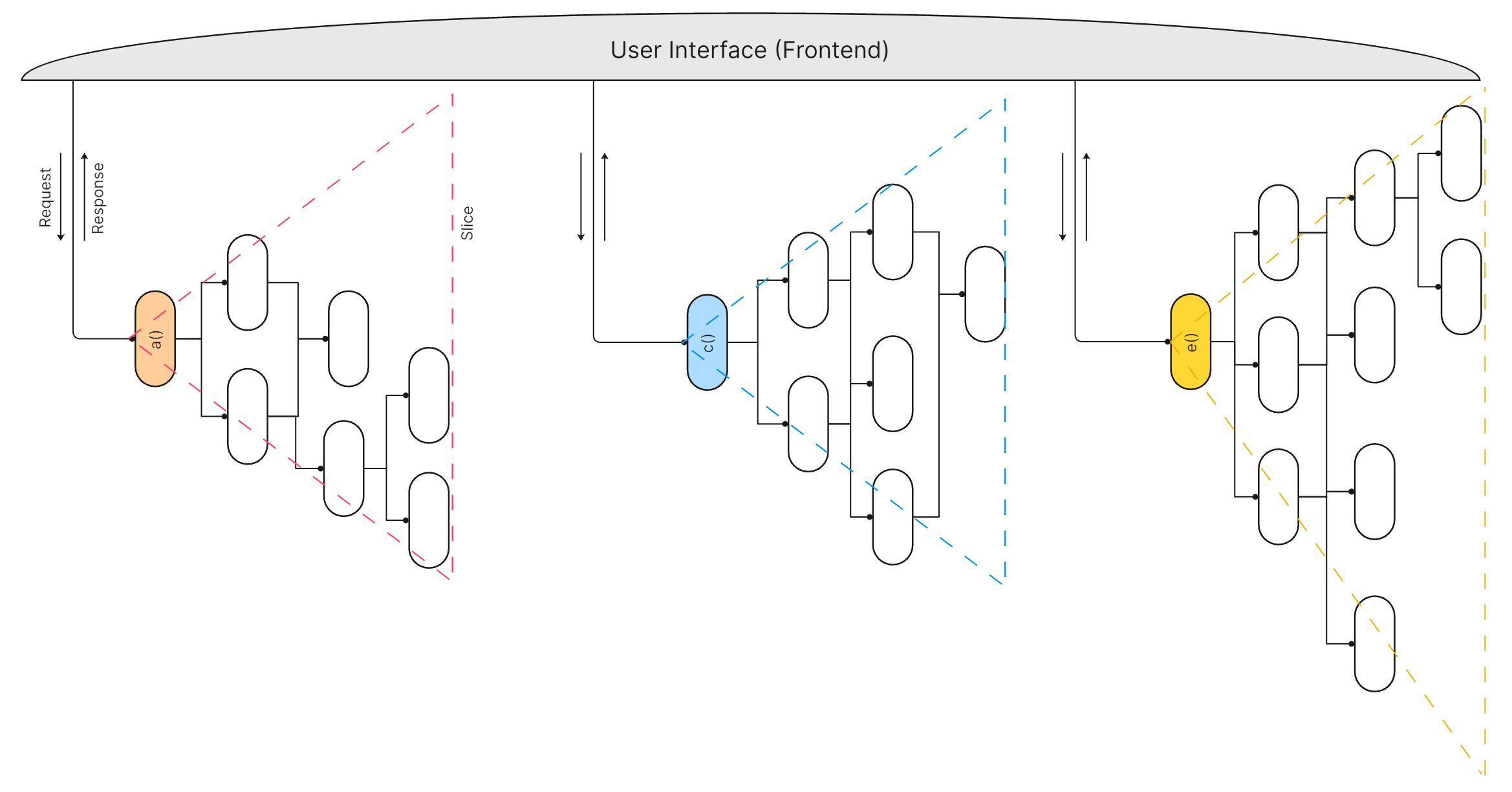
The user interface collects input from the user (e.g. from data entry fields), packages it up into a request, and passes it to a slice (aka calls the slice’s entry point function).
The slice’s function tree processes the request, and produces a response.
The user interface takes the response and projects it to the user (e.g. as a message, a data table, or a diagram) as output.
This process starts when the user in some way triggers it; this might be by moving the mouse, hitting a key, or clicking on a button. Whatever seems best for a great UX.
Most importantly for Agility is the independence of the slices. Each slice can be thought of as a program of its own. Yes, I mean it: think of it as a CLI program which reads its input from request.json and delivers its result in response.json. The user interface’ job then is to create the request JSON-file, call the slice’s CLI program, and afterwards unpack the response JSON-file to display its content.
Imagine a slice being called like this:
$ ./sliceA < request.json > response.jsonHumour me for a minute: What would developing an application feel like if it was structured like that? Each slice would be a separate program; each slice could be run like this from the command line for testing or as part of a batch; each slice could be developed independently of any other; each slice would do the whole job by itself without requiring the service of another. Slices would be very decouples from each other and any user interface.
Wouldn’t that be great?
My strong belief is, structuring software along these lines can boost productivity.
Of course this has some prerequisites:
increments need to be very easily identified
increments need to have a scope as small as possible
increments need to share as little as possible
How to achieve all that?
To identify increments no speculation should be needed. The customer/user should be the guide. The delineation should be obvious. My suggestion here is:
Obvious increments are whatever can be triggered separately by the user.
Agile requirements analysis goes on the hunt for triggers in the user interface. It works closely with users and UX designers to identify where and when input should be collected and passed as a request to code for processing and producing a response.
For large requirement scopes it might be hard work to get to these trigger points. But it’s worthwhile because once they have been identified implementation can progress independently.
Progressively more detailed sketches of user interfaces are employed in this kind of requirements analysis. They don’t need to be exact; they only need to make tangible for users and developers alike, when/where/how activity is kicked-off.
The relevant activity of course is not concerned with frontend technology. I don’t mean clicking a menu item to reveal sub-menu items. This is automatically done by a user interface framework. Slices are concerned with domain logic and resource access behind the facade of the user interface.
Here’s an example of a user interface sketch:
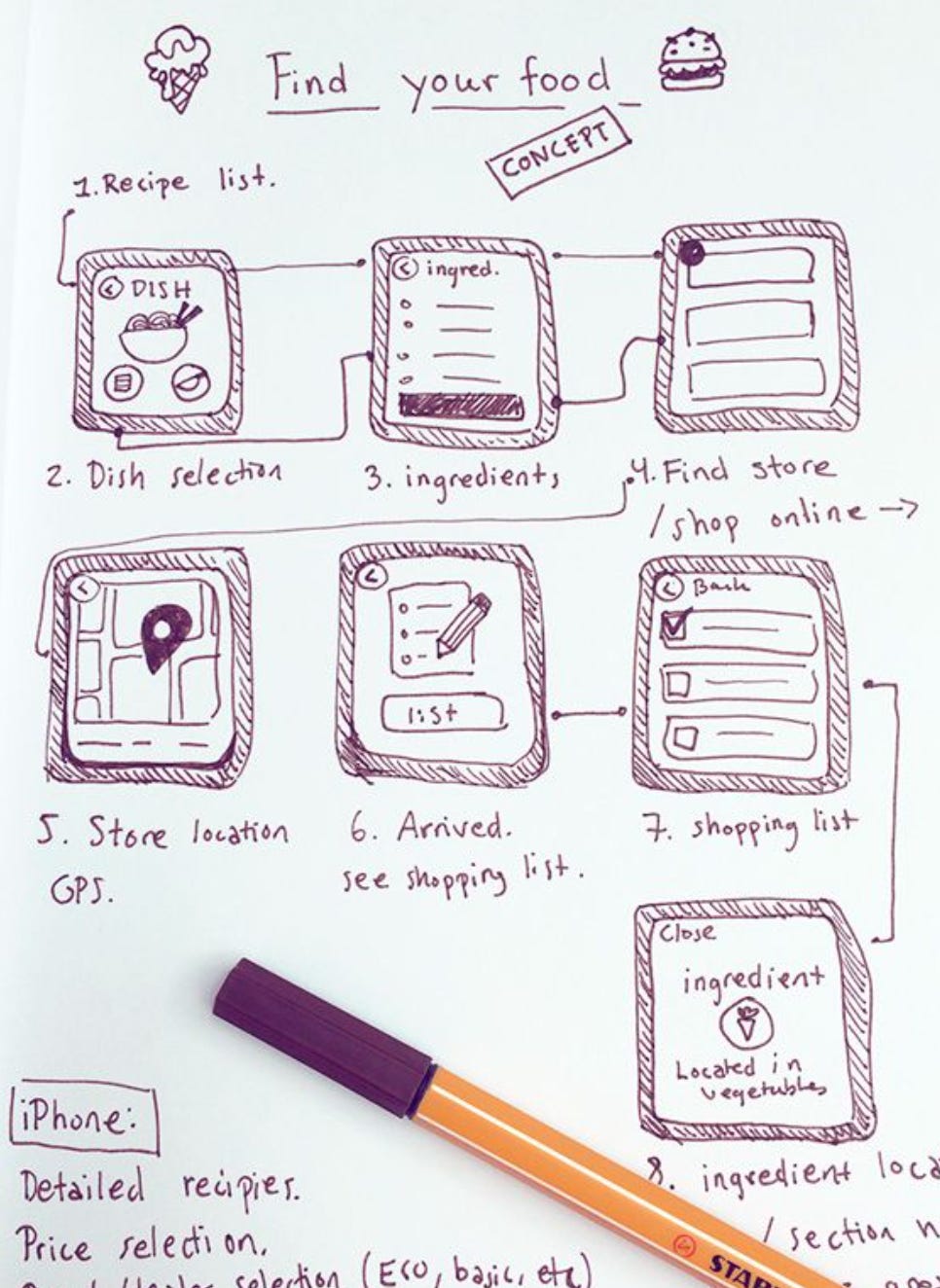
This is a high level overview. Several screens/dialogs have been visualized. Transitions between them are laid out. Next step: Zoom in on each screen and identify the trigger events for slices. The result is a long list of widgets and attached entry point functions to carry out the required actions:
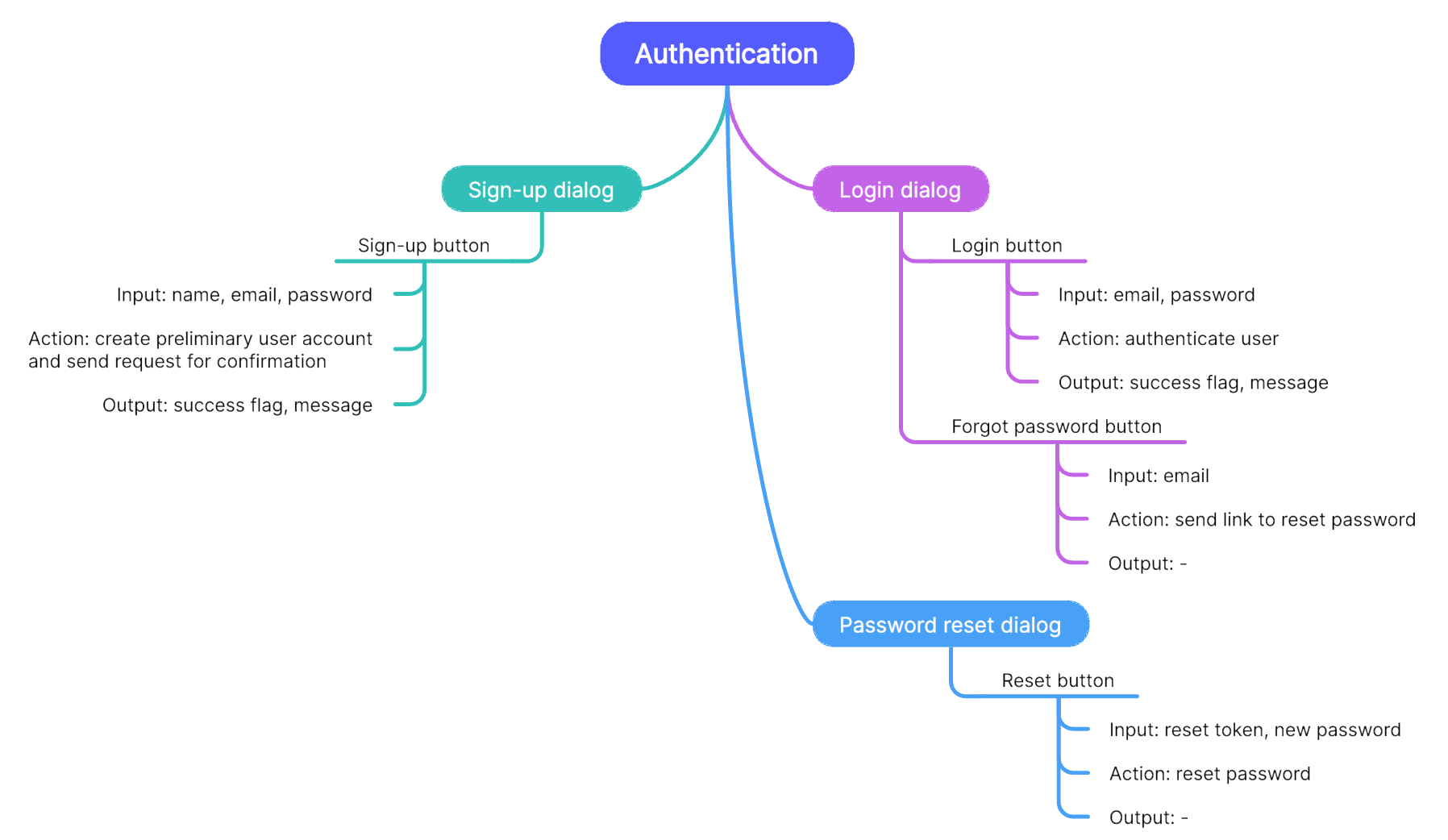
Slices rooted in user interface triggers are very natural increments all users can relate to.
How do ensure these slices are thin? Follow the CQS principle, a cousin of the SRP. It states: Separate application state change from application state projection.
Ideally each trigger should kick off either only a modification of the application state or retrieving application state. Slices thus can focus on one or the other thereby reducing complexity and supporting testability and scalability.3
Each slice is either a command processor (Cp) or a query processor (Qp). Ideally each trigger just triggers one slice, either a Cp or a Qp. But sometimes a Cp-Qp sequence might be more intuitive from the user’s point of view.
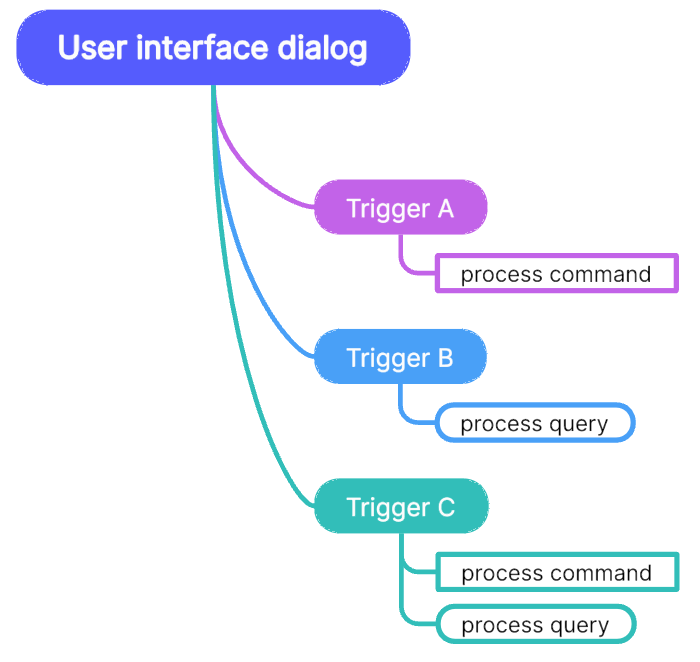
Example: When hitting the login button of a todo application the user wants to be presented with a list of his tasks.
Logging in the user is a command; the internal state of the application changes to reflect the user is now active.
Presenting the list of tasks requires querying the application state.
Both request should be executed behind the scenes as a reaction to the user hitting the login button. To the user it’s a single action, but internally two slices are invoked in sequence:
const {email, password} = userInterface.collectLoginInput()
const {userId, authtoken} = loginCommand.process(email, password)
const {tasks} = userTasksQuery.process(userId, authtoken)
userInterface.projectTasks(tasks)Of course, what a CQ-focused slice does can be a lot. Its function tree can be big. But at least it’s bounded by a single purpose: either change the application state or just read it.
To realize the potential of Agility for productivity one more prerequisite has to be in place, though.
Increments are easily identified, increments are small, but how to decouple them for parallel development? That’s the hardest part to accept for developers raised with the CRUD paradigm.
Slices must not need each other. Slices must as much as possible not depend on the same “services”. Any cross-cutting code per definition is code to be reused by multiple slices and thus drawing down productivity with its stability requirement.
Still the slices need to be connected somehow. If one increment is about adding data to the application state, and another increment is about displaying application state, then both share… application state.
All increments naturally revolve around application state. That’s the common ground they are built on.
But in order to keep the increments’ slices as decoupled as possible, the application state must be as simple, as malleable as possible.
This is contrary to what mainstream object-orientation has taught for the past 25+ years. Nevertheless it’s crucial for Agile productivity.
“Old style” productivity relies on components and designs. The result are CRUD architectures with all their drawbacks.
“Agile style” productivity does away with the component focus. It gives up single, central data structures (loaded with functionality) in favour of a fine grained data substrate.
The slices of “Agile style” productivity all ladle the application state they are interested in from an ever expanding stream of events. Command slices pour new events into that stream, query slices scoop relevant events from it.
For “Agile style” productivity CRUD needs to be replaced by AQ (Append and Query).

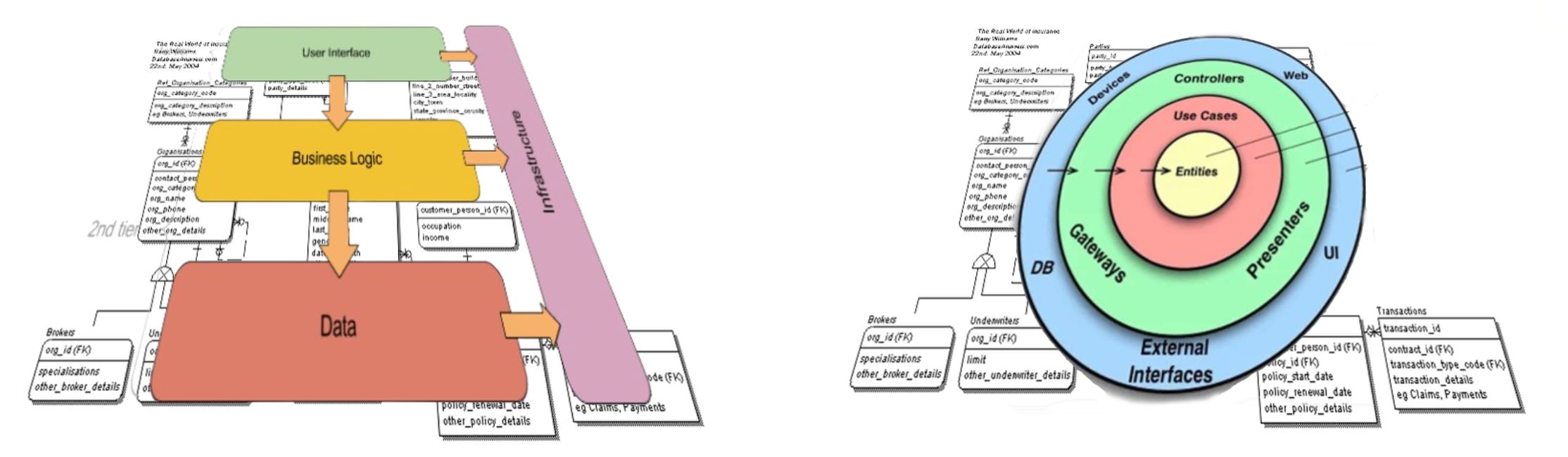
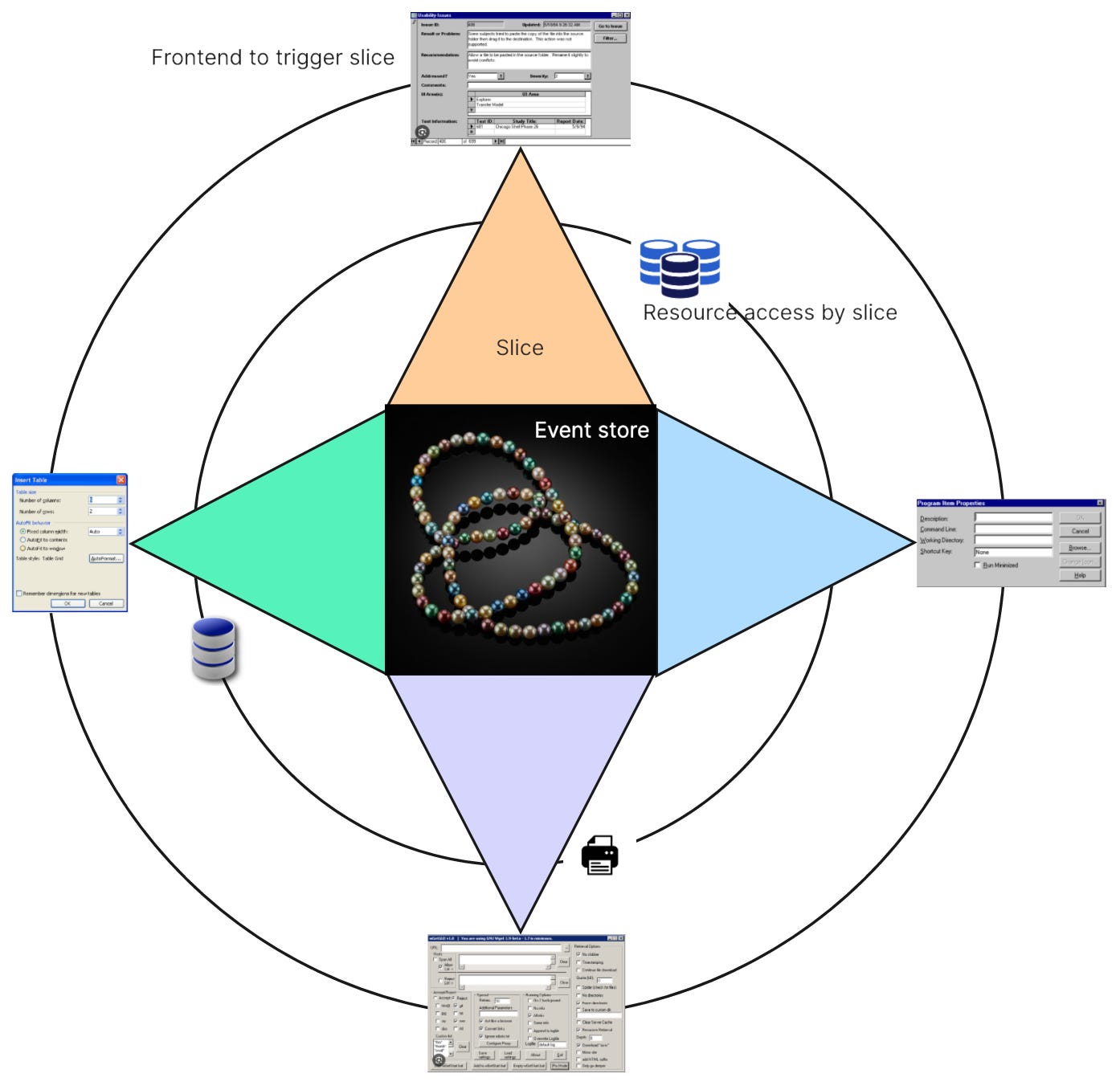
AQ architectures can be depicted as “software cells”: an application is a body of code with a surface an interior and a core:
The surface is where the application is connected with the environment. It gets triggered by the environment, and it triggers other “agents” in the environment for its own use.
The surface consists of the user interface and a “back plate”. Together they form the shell of the software cell. User interface code is wrapped in modules I call portals; “back plate” code is wrapped in modules I call providers. Bother kinds of modules are adapters bridging the gab between outside/environment and inside/interior.
The interior where “the magic happens”. This is where requests are transformed into responses in slices.
And at the core there is the event store. All slices of the interior have access to this raw, fine grained stream of facts. They either extend it by appending events or they query it for a subset of relevant events.
Here’s a creative illustration of this architecture:
And here a more formal depiction of the basic structure of an application:
As should be obvious, application state is something special. Even though it’s also kept in a persistent resource (event store based e.g. on Postgres), it’s treated differently from other resources (e.g. printer, network communication, other databases, file system).
Application state in an event stream is like transient memory (stack, heap). It’s just there. It’s a given. It’s non-negotiable.
This makes the software cell as an AQ architecture very different from all precursors sporting a circle as the basic shape, too.
The sliced software cell architecture — call it “Pizza Architecture” (PA) if you like — is very, very opinionated. It defines a the fundamental structure of applications like the von-Neumann architecture defines one for computers.
Think about a software cell like above as equally given like the von-Neumann architecture. Do not confuse yourself with “It depends…”!
No, if you want the full productivity boost from Agility you need to accept the sliced software cell as you accept the von-Neumann architecture, stack based 3GLs, and automatic garbage collection for your objects. It’s just how you do software today.
Any solution to a user problem then has to be found within the constraints of the von-Neumann architecture, your stack based 3GL, automatic garbage collection for your objects, and… a sliced software cell architecture.
To wrap up let me go back to the beginning: Why questioning traditional software architectural patterns in the first place? Because they don’t cut it when it comes to productivity. They do not support the Agile approach. Their reliance on CRUD aka the single, central data structure serving all requirements is in opposition to Agility’s incremental progress.
How can that be improved? How to reap the full benefit of Agility? Map increments to code; make them the basic structural elements of code. And then implement them as much in parallel as possible. The basic architecture of software should support division of labor in face of high uncertainty.
Slices as basic (coarse grained) building blocks are the answer. Slices instead of components.
Slices are the manifestations of increments in code. And if slices are cut in a way that each is responsible for responding to a trigger during user interaction, then they are easily identified.
And if slices are focused on either changing application state or reading it (CQS), then they are (comparatively) small from the outset without much design.
And if slices share nothing, are independent of each other’s workings, they can also be implemented very independently. That’s maximizing productivity and allowing usage of AI to help with each slice.
The prerequisite for such independence is to dispense with single, central, intrigate, one-size-fits-all data structures to be used across the implementation of many features.
Instead an event store for “factlets” with a multitude of small schemas to be easily projected into slice-individual very specific data models should be chosen as the medium for application state.
CQRS was a first attempt at more Agile architectures, but it took VSA to identify the unit of progress: the slice as a manifestation of an increment.
The AQ software cell architecture now takes this idea further by firmly putting an event store at the core of an application to decouple slices and rid them of any smell of architectural styles associated with CRUD.
The AQ software cell does not prescribe a structure for a slice. But as suggested further up it firstly should be thought of as a hierarchy of functions. A modular structure for a slice is of secondary concern. Functions simply are more aligned with what users want: function-ality. Plus and contrary to popular belief, functions are close to the heart of the original idea of object-orientation.
So, if you want to become productive, ditch CRUD and component thinking. Instead assume AQ and slicing. Let the requirements driven the structure of your code.
Of course I am acknowledging the benefits of libraries/frameworks built for reuse. If some functionality has been specifically identified as being of great benefit for many people, then it’s prudent to wrap it up for easy reuse — and allocate resources to develop it responsibly as to keep it stable for all users. But make no mistake: this is a demanding undertaking. It should not be taken up lightly.
Some aspects of behavior sometimes cannot be created with logic. Instead software development has to employ distribution, i.e. running logic on different threads. This is very unfortunate because distributed logic is much harder to test and easily suffers from all kinds of problems (see “Fallacies of distributed computing”).
In my view this does not necessarily lead to CQRS, e.g. the grouping of command vs grouping of all queries with interfaces. This might be a concern for scalability, i.e. a runtime property of software. I am not concerned with that. For productivity such grouping is not necessary.
What a great idea 💡. If your time allows, could you maybe provide an example (in code)?
In principle I could build such a system with Java and Angular (the platforms my team understands). Each slice gets its own Java package, and Java modularity rules and ArchUnit tests could verify no slice uses a package from another slice. Slices can only use a small kernel of event services. In Angular / TypeScript each slice could have its own library.
My concern with keeping Java and Angular is my team members would keep their old way of thinking. I'm intrigued by the idea of a Linux application: a collection of small binary tools that communicate by pipes. I'm also interested in building this network of functions on a functional platform, like Lisp or Haskell.
Still, sticking with my current tools means not having to reinvent the build pipelines or the packaging scripts. The key thing is to get started; communicate the new ideas and start building something.