
Incremental Event Sourcing - Under the hood
How can small Agile increments be mapped onto code?

Remember how Darline implemented the game of Tic Tac Toe for Pete without knowing what the application was about for a long time? I documented their interactions in this post:
Incremental Event Sourcing

How does Agility look when paired with Event Sourcing? How does it look when increments get manifested in code? Let me try to explain what I meant when I wrote “True Agility requires Event Sourcing.
The iterative development went on for 10 iterations until Pete was satisfied. 10 times Darline was presented with just a small slice through the requirements and was able to deliver the implementation very quickly. She did now discuss the requirements extensively with Pete — there was no need because the scope always was very, very small. But also she did not pause to make extensive designs. There was no up-front anything.
How was she able to pull this off?

Sure, this is a story I made up. The example domain is small to start with. But as you will see, Darline did not really take advantage of knowing anything beyond what Pete threw before her.1
In the above article I only told the story of what happened on the surface during the requirements analysis and feedback session. In this article I want to take you backstage. I want to observe with you what Darline did during implementation.
If you like come along and have a look at some Event Sourced Vertical Slice Architecture code. It will be fun — one way or the other. Maybe you agree, maybe you’ll be surprised, maybe you’ll think it BS. Either way some emotion will be stirred. I hope.
The technical setup
The first article does not mention anything about the programming language or tools Darline is using. She just shows the growing application in a terminal window. So there has been made a decision for a CLI/console program. That’s for simplicity’s sake and to enable readers to more easily follow the evolution of the code. I did not want to confuse anyone with UI frameworks. They are quite unimportant in my view; the really interesting stuff his happening behind this facade.
As an implementation language Typescript was chosen. It’s a modern language, can be programmed in a type safe manner and is available on all platforms. Darline runs it with npm, but using Deno or Bun is possible, too.
More interesting is the storage paradigm Darline chose. It’s Event Sourcing done with Rico Fritzsche’s and my small, simple, straightforward, no frills Event Store (also implemented in Typescript). It’s open source. Check out the Github repository here: https://github.com/ricofritzsche/eventstore-typescript.
The storage engine underlying the Event Store is Postgres. But that’s not really important. I would have liked to use an in-memory Event Store, but it hadn’t been finished at time of writing the article (see update at end of article). Except for these lines at the beginning of the main script file nothing depends on Postgres.

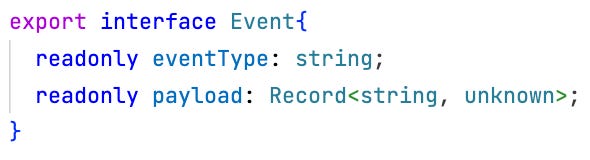
The Event Store will be referred to by an identifier eventStore with this interface type:

That’s it. As explained here, an Event Store is something very, very, very simple. That’s the whole point.

But from a switch from CRUD operations to only the operations A(ppend) and Q(uery) follows so much… It’s a paradigm switch influencing your whole code base. In a very positive way, I believe. Hence:
No application should be without an Event Store.
Increment 1 - An initial command
For the first increment Pete only tells Darline that he wants some kind of game. Nothing more, nothing less. No rules are explained, no visualization is discussed. Click on the link above to see their discussion.
What does Darline do with the information? She first focusses on the CQS principle. This is the lens through which she views all requirements. What are the commands and/or queries to implement?
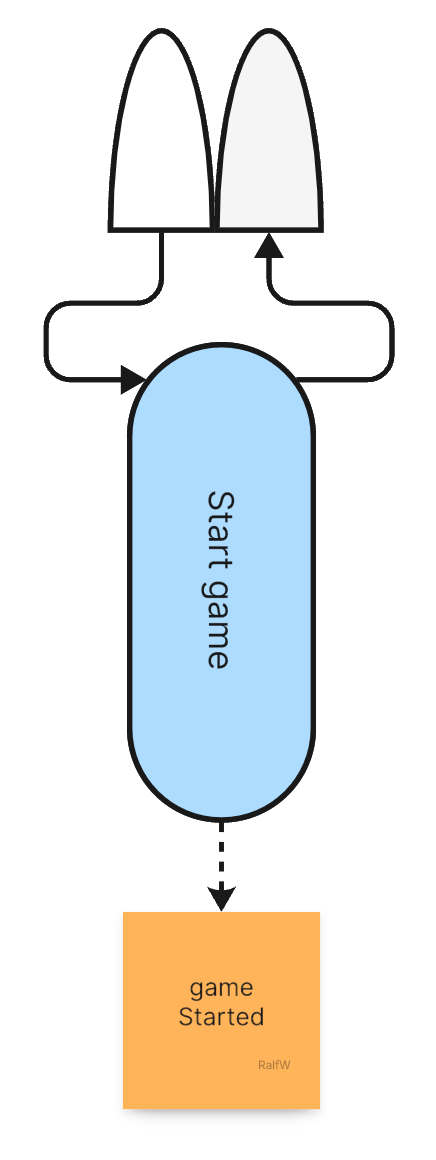
The command in Pete’s requirements is obvious: Start a game! It has two parameters: the names of the players, StartGame(player1Name, player2Name).
Commands by CQS’ definition change application state. So the next question is: how does the command change the application state? Or even: What is this application’s state in the first place?
Darline hasn’t discussed that with Pete. Pete probably does not care much about “application state” anyway. He wants to play a game.
There is no info for Darline to derive an application state schema from. She does not know anything about the data the application will require once fully implemented. Which part of the data should be kept in memory as an domain object model? Which part should be persisted in a database? Would a relational database be best or better a NoSql document database?
She does not know — but also does not care. Her approach to software development is to match CQS in the frontend with Event Sourcing (ES) in the backend. That means she defaults to not storing application state in models of any kind at all. Rather she will be just recording meaningful changes to the application state as they become apparent.
Every command will be mapped to one or more events. Every query will retrieve events of one or the other kind. Darline is confident that’s enough. She’ll manage implement all requirements by just relying on a growing number of types of events. The general one-size-fits-all schema of an event is this:
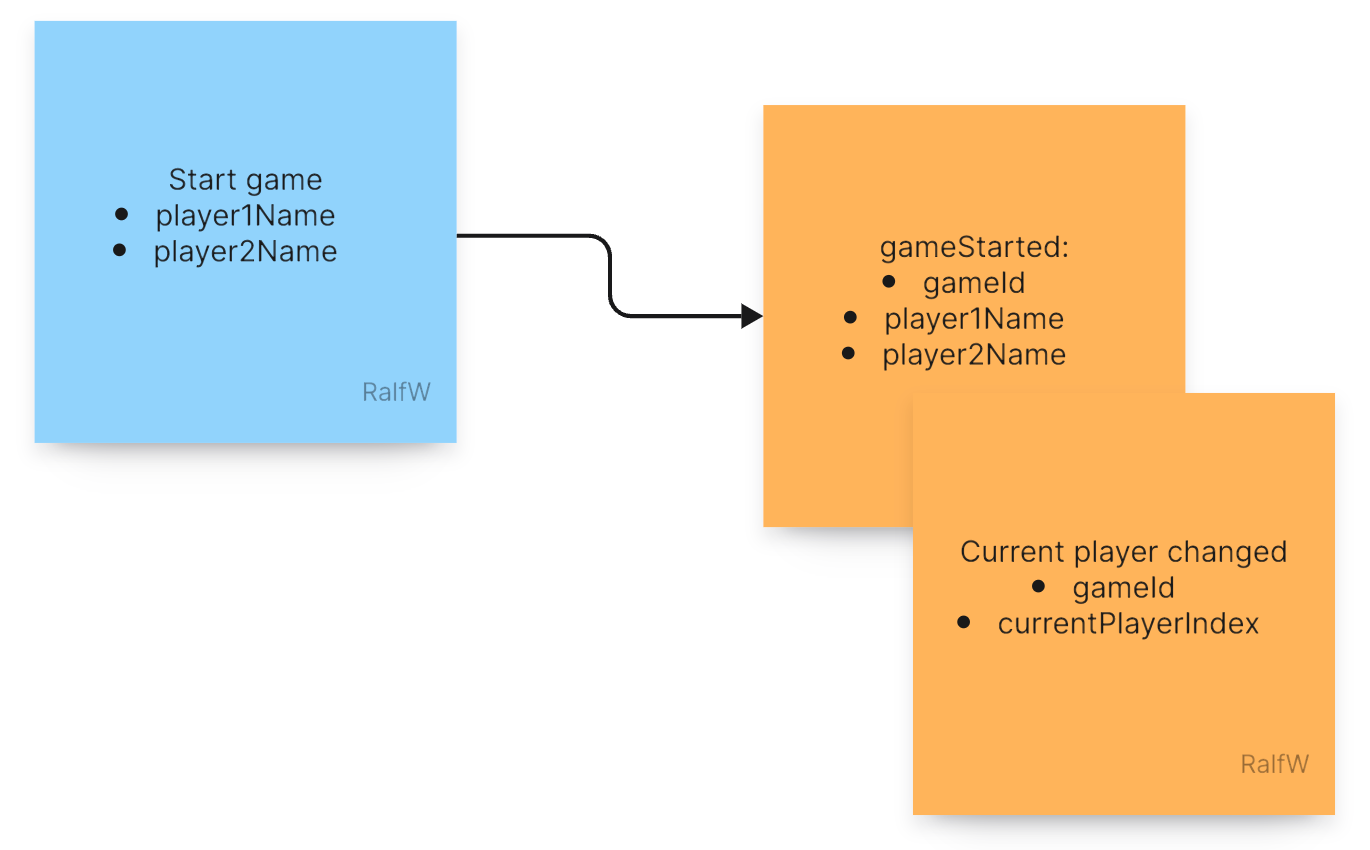
For each event type Darline can decide how to shape the payload. For the event recorded by the StartGame command it looks like this:

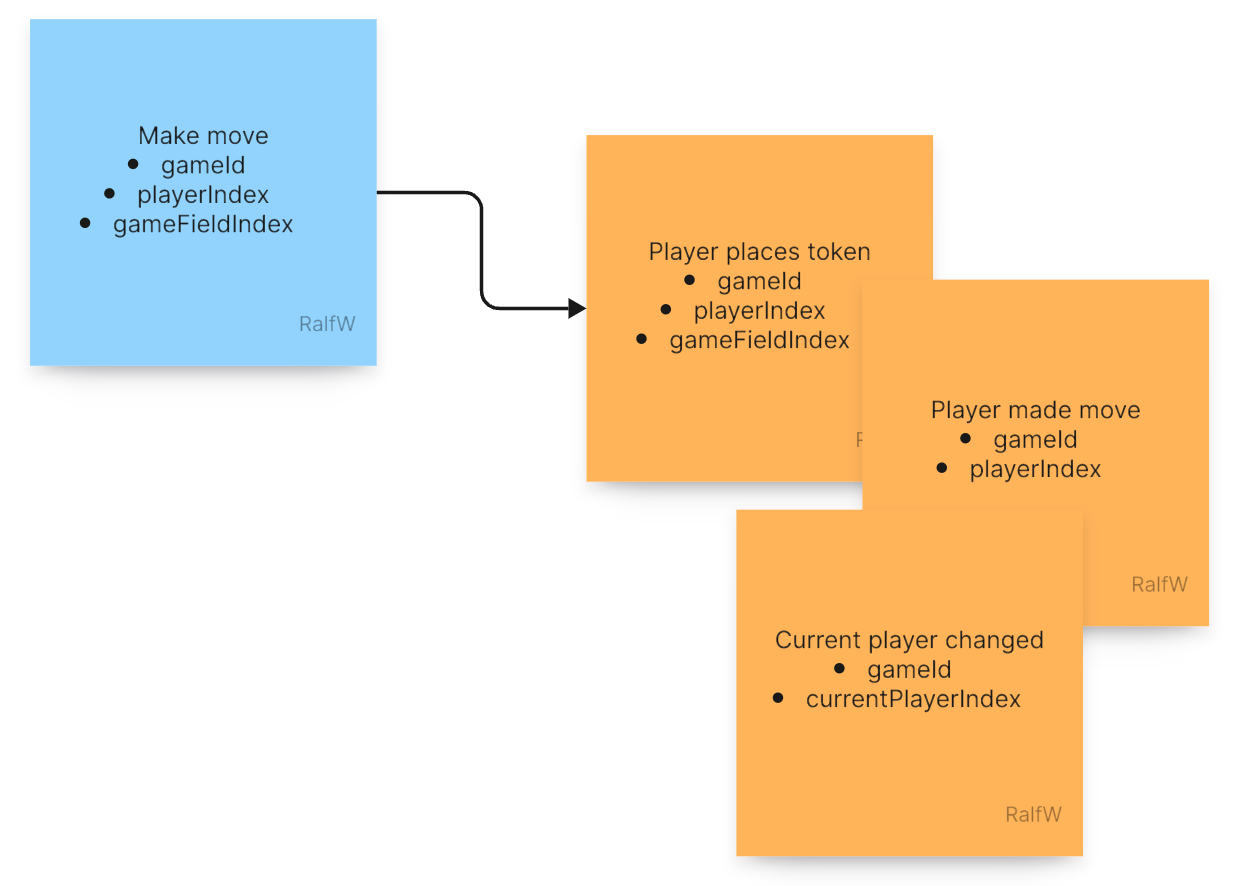
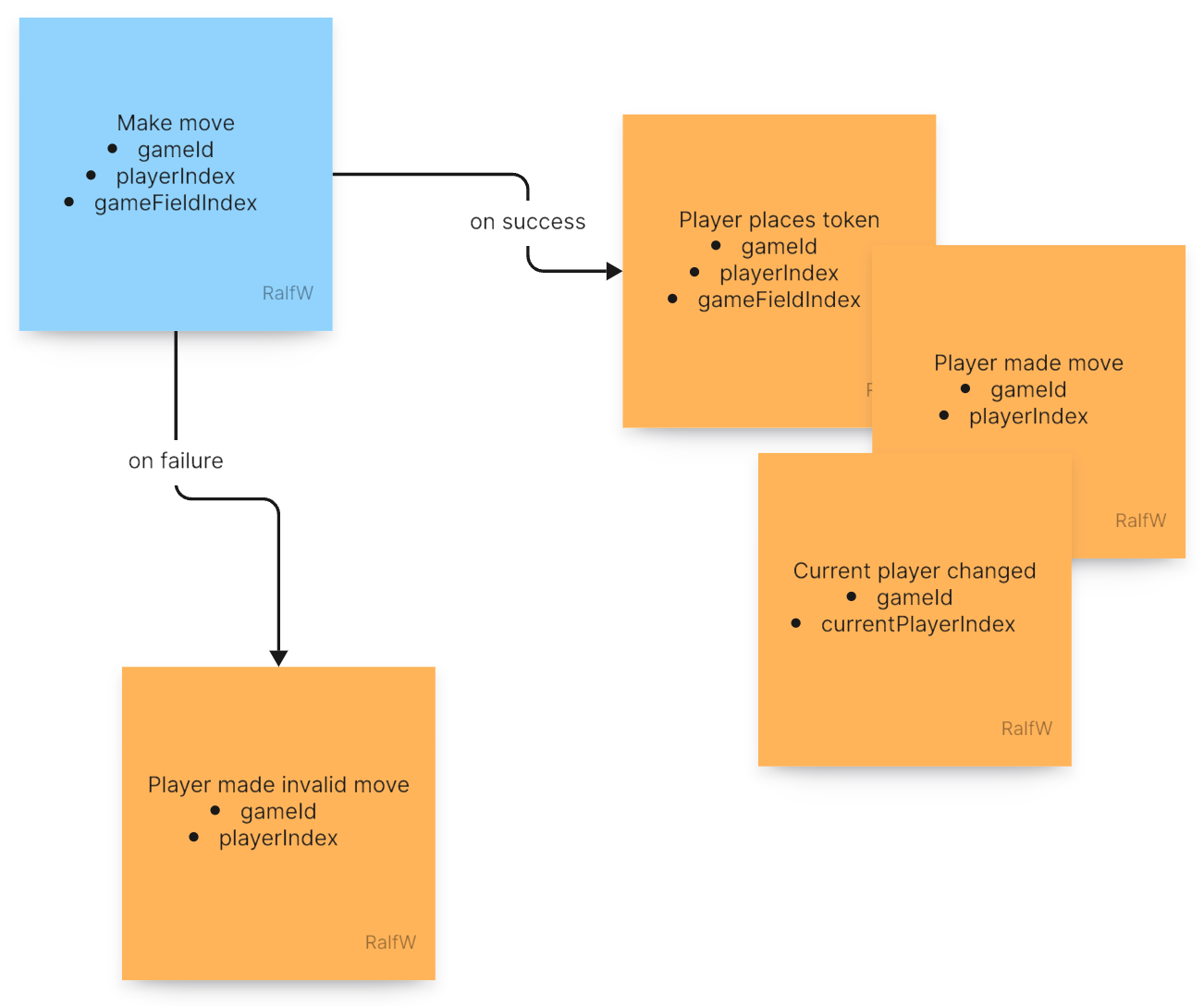
Or to make it a bit more visual you can use post-it notes to design the requests and events of an application like this. Keep your thinking independent of code a little longer.
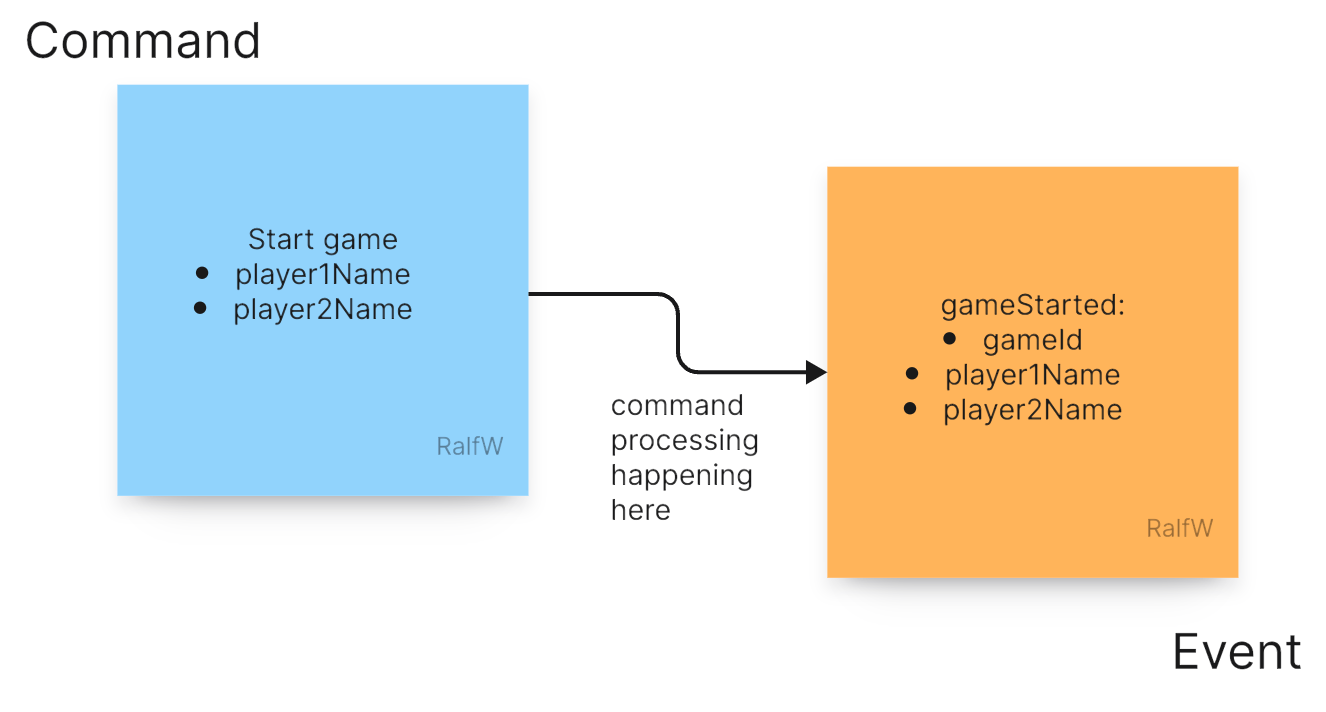
This how Darline starts every increment:
What are the request hidden in the user’s story?
Which events match the story?
Command: Which events should be generated to record the changes to the application state?
Query: Which events are there already that can be used to compile application state to present to the user?
What she does not do is to think about some object model or other kind of single schema to be shared among all parts of an application. Darline does not strive for Hexagonal Architecture or Clean Architecture.

That does not mean her code’s structure is random. But these patterns don’t serve her Agile approach. She does not find them flexible enough to keep up with ever changing requirements.
But isn’t there a hint of a data model in her event? Where does the gameId come from? Pete did not ask for it.
Indeed, here Darline’s expertise as software developer kicks in. She knows that when Pete is talking about a game that
there probably will be more over time which all have to be distinguished, and
each game will be like a bucket into which data will be poured.
Which data will go into a game bucket? Darline does not know. And she does not want to know in advance. Because knowing in advance would make her prone to premature optimizations of some data structure.
No, it’s enough to know each game is something different from all other games and needs to be identified independently from its attributes. It deserves an ID of its own.
Such kinds of “data buckets” are also called entities. Entities are “things” with an ID independent of any values which might be associated with them. Think of a person: even though a two persons may have the same name they are different. Or they might look the same like twins. Still they are different. Biologically that’s expressed by their DNA. Socially it’s expressed by different numbers on their ID cards.
The same principle Darline applies to data. Without much design effort she just wants to spot entities as buckets for data. Whatever that data might be.
You see the pattern? No big effort structuring code up-front. No big effort structuring data up-front.
That’s what Agility is about, no, should be about, I think. Because anything else would impede future changes to adapt to yet unknown requirements. Surprising requirements must not be a surprise. Design for surprises; embrace surprises. But that means giving up cherished believes about software structure.
Structure must only be planned for what really, really is certain. And the most certain trait of software is… that’s it’s uncertain. What is it supposed to do in 1 or 5 years in the future? Nobody know. Why then would you believe todays finely chiseled data models will fit the bill?
With the above event Darline creates a data structure only for what’s certain right now. Plus, she adds the ID to be able to tie other related data to this if needed. You never know. So, the ID is her way of recognizing uncertainty (“What kind of data will need to be related to the player names?”) in the face of certainty of uncertainty (“For sure there will be something to relate to the player names.“)
Think of the ID as a “common thread” running through many different events of different type.
Sorry, this was a little detour through some basics. But I think this will make it easier to follow Darline along.
Back to her application: She knows the command, the knows the event to generate. How to implement that?
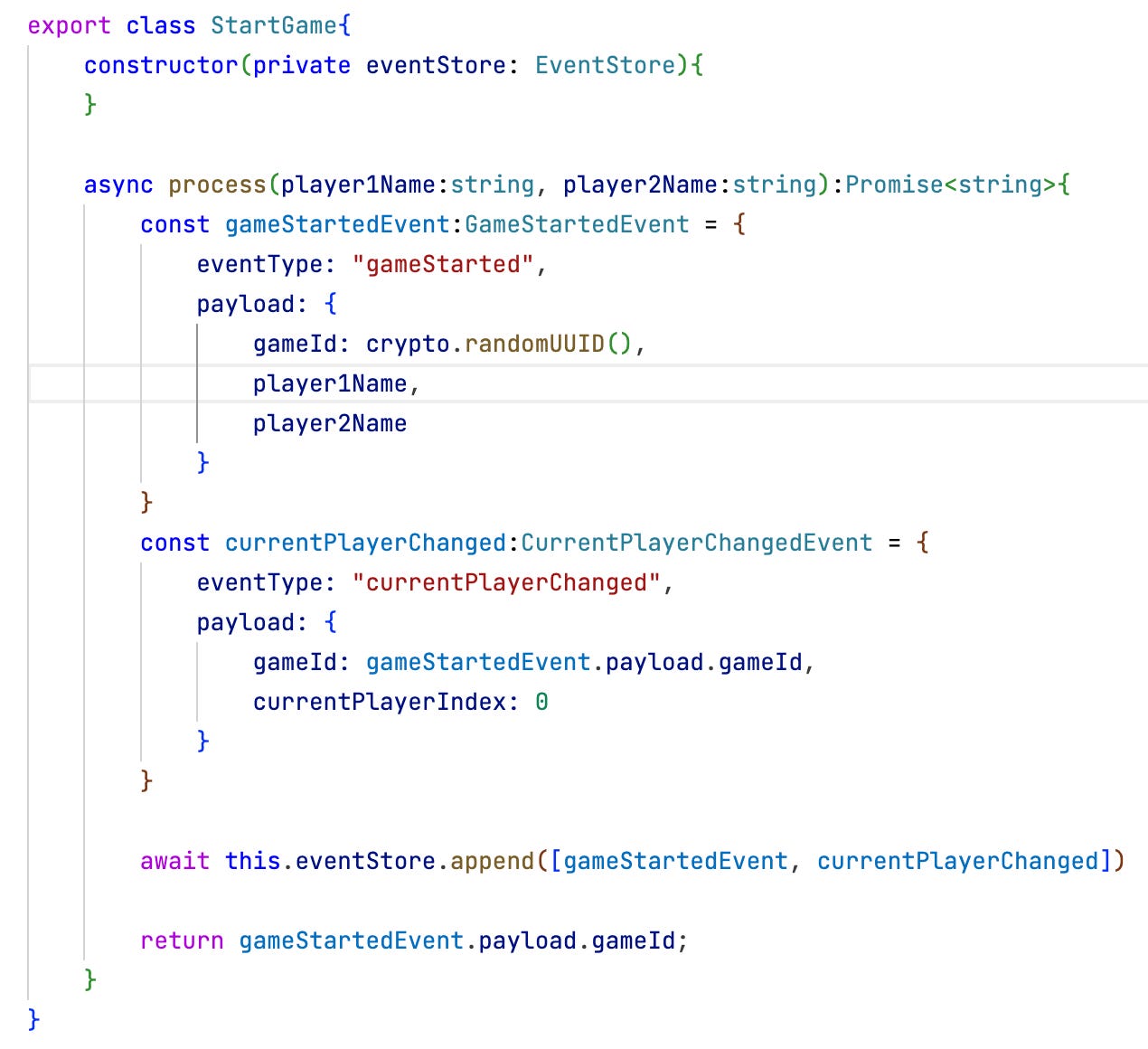
It’s very simple: Each request will be represented by a class into which an Event Store is injected. This is quite convenient, she thinks. But it’s not meant as a particularly object-oriented implementation.

In this case the command is “mapped” to the event very straightforwardly. And then the event is stored in the Event Store. More specifically: it is appended to the stream of all events. Event Stores are append-only data structures. Nothing is ever deleted or overwritten. Hence AQ instead of CRUD.
The gameId is generated automatically as a unique value, included in the event, and returned to the caller. It probably will be used in future requests regarding the same game.
That’s pretty much it what Darline does for implementing Pete’s request. With Agile Event Sourcing the focus is on the transformation of a CQS request to events.
There’s no database to talk about. The Event Store is as it is: a simple two function persistence API. All schema design is done by defining the events. Nothing to maintain in terms of a database. As shown above it boils down to choosing the medium — here: a Postgres database — and instantiating an EventStore implementation for it. After that it’s all medium-agnostic access.
Oh, of course, there is also some user interface, Darline needs to take care of. But that’s not really the part of software “in dispute”. So, whatever UI technology Darline chooses it hardly makes a difference for the overall architecture.
Let me show you maybe just once how she’s doing it:
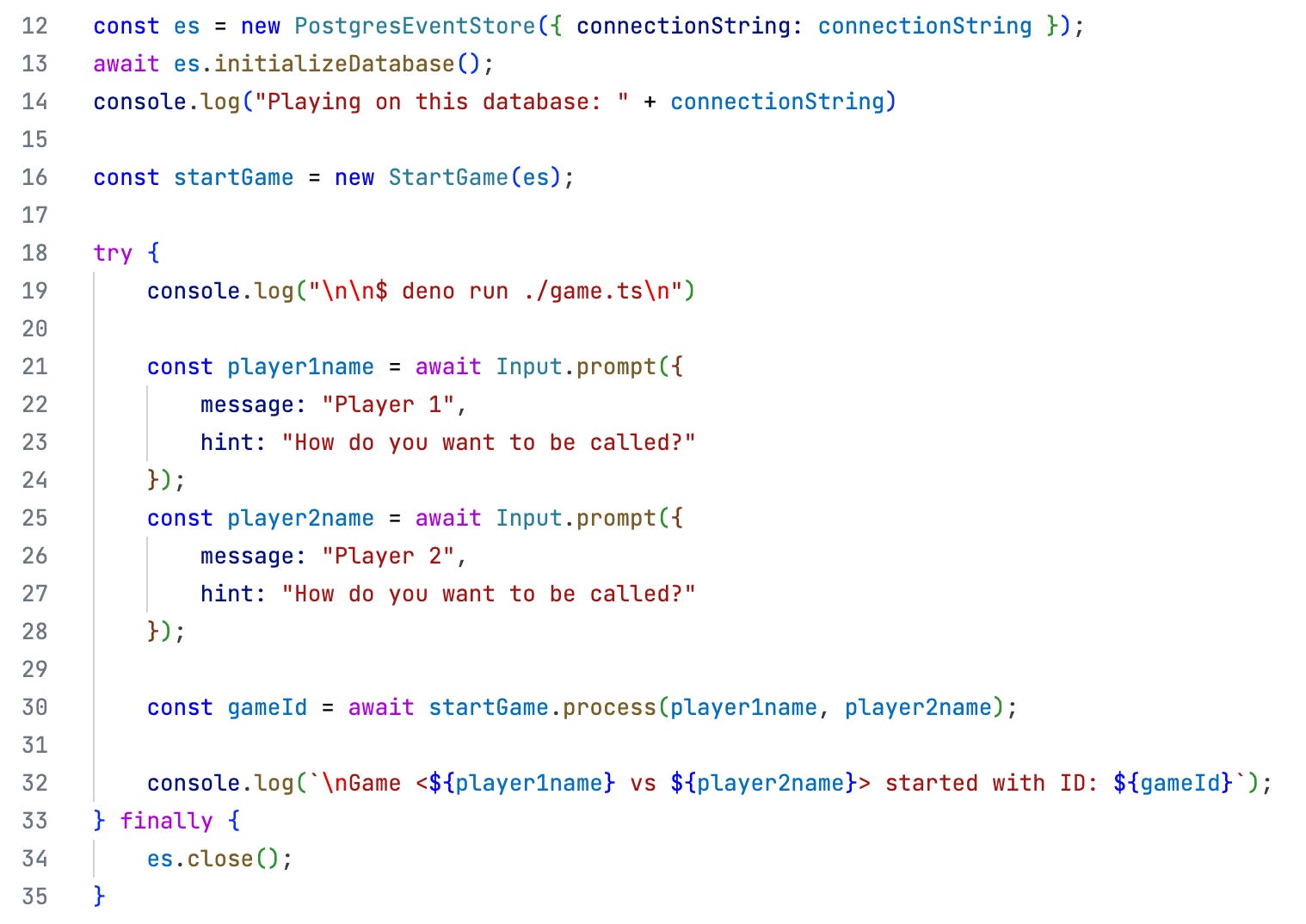
This is just for the first increment but the overall structure will stay the same.
The Event Store is initialized.
The slice for the requested feature is constructed.
The user is interface shown. The users can interact with the application.
Most interesting is line 30: that’s where the “command processor” StartGame is called.
Before that the UI collects from the users the command parameters. After that the user interfaces displays some result message.
This is the pattern for all interactions:
UI: collection of request parameters
Request processing (command or query)
UI: projection of response data from the request processor
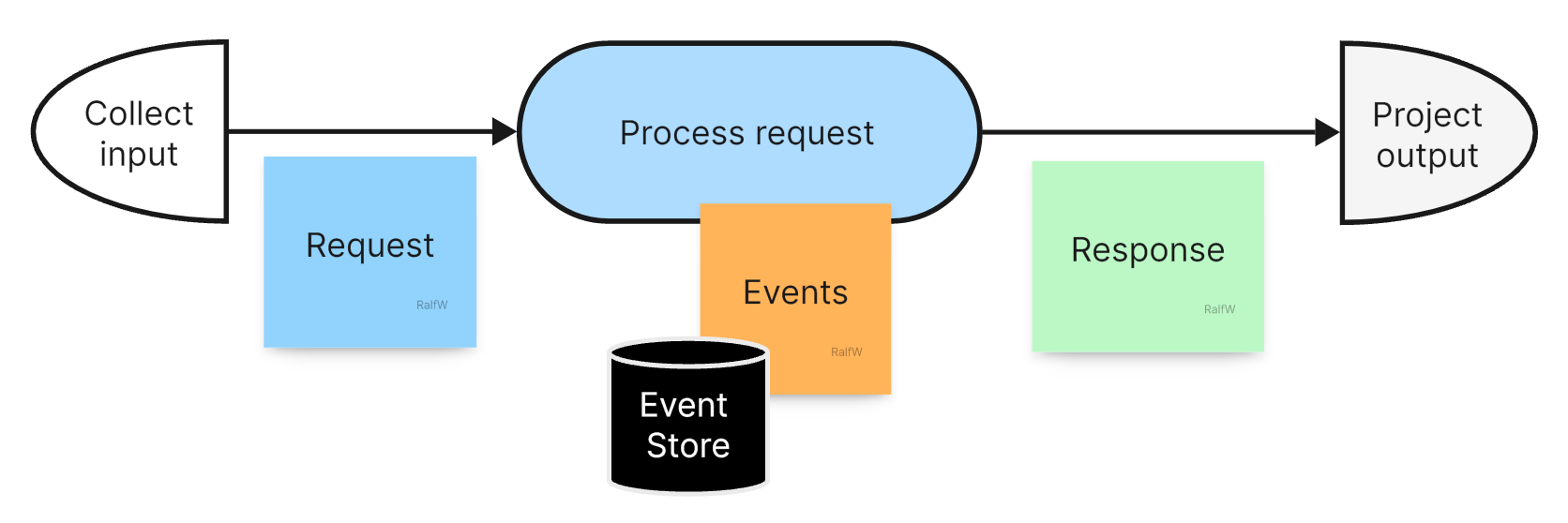
And that’s also the basic architecture for an event sourced application. Following the CQS principle Darline will identify the relevant request in each increment — there should only be one —, and create (or look up) the requesting handling slice in code.
According to the Vertical Slice Architecture (VSA) an application is made up of a multitude of such slices. They are the work horses. That’s were interesting things are happening.
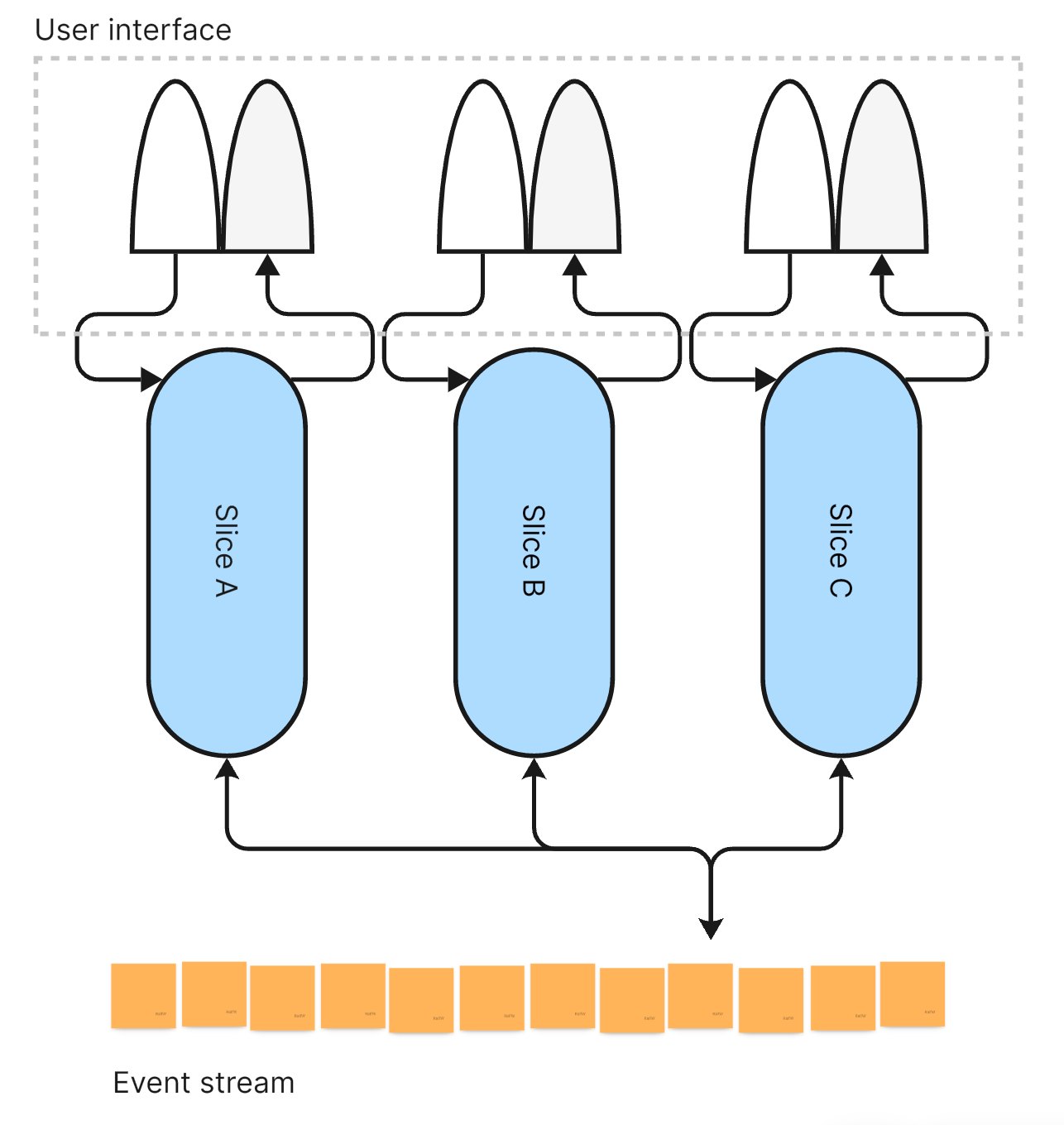
Slice service the user interface. Slice append to and query the ever growing event stream. The application state primarily resides in the event stream. It’s the single source of truth regarding the application state now and at every moment in the past.
But that’s it. Slices don’t share more. They share the least common denominator: very simple and small differences in state. A fine granulate from which they can extract all the information they need.
That’s what’s in the back of Darline’s head.
So, what I want to focus on throughout this reflection on Darline’s approach are the slices and the events. The user interface I personally find pretty boring or even distracting. So much effort can be sunk into it distracting from the real behavior creating parts of an application which needs to adapt over time.
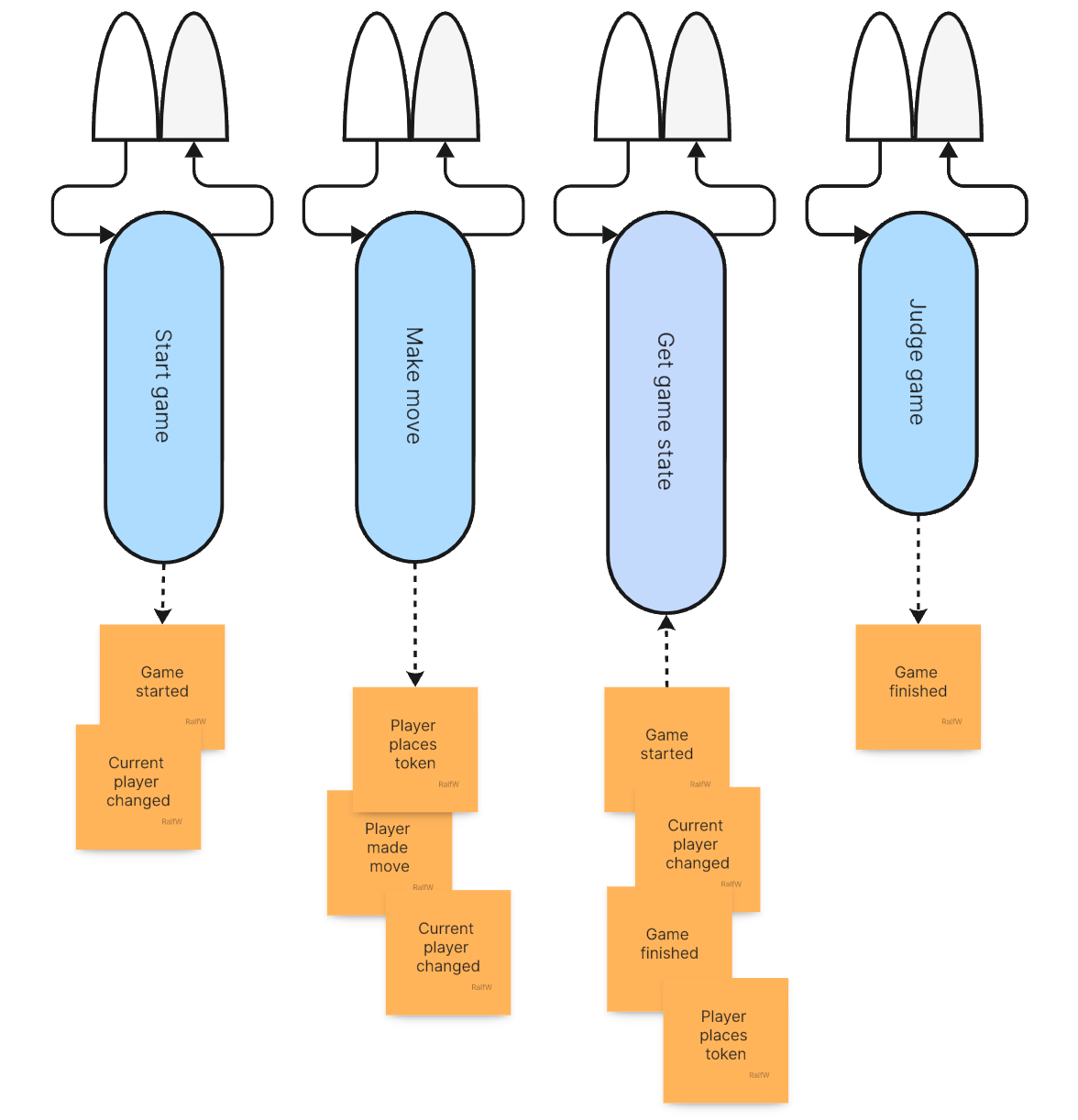
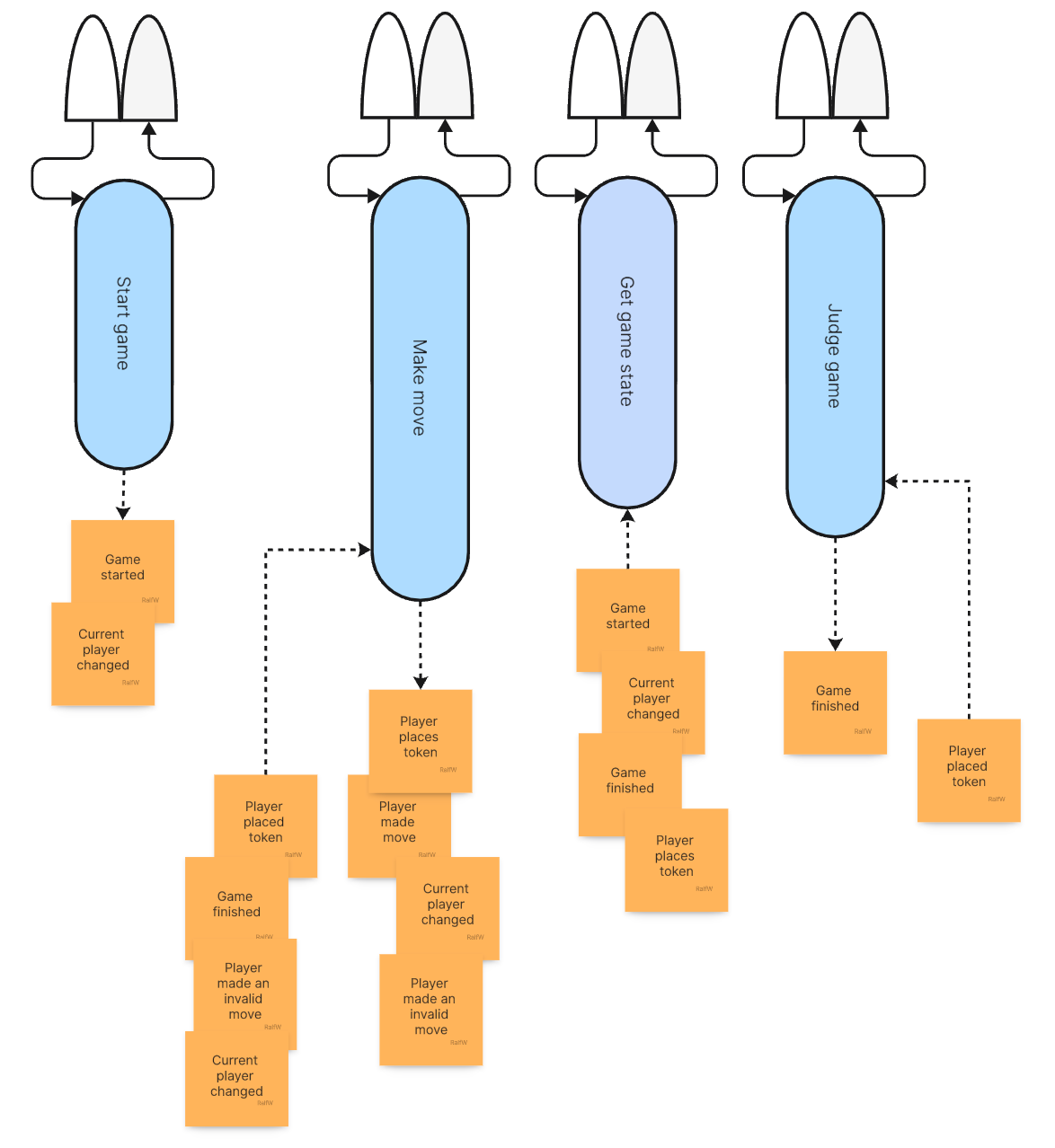
Here’s the concrete application architecture after implementing the first increment:
Now let’s move on to the next increment. Everything will become more clear to you when you watch the code evolving “under the pressure of new requirements”.
Increment 2.1 - Another command…
The second increment is about the players making moves in turn. This sounds very simple, but Darline needs to think about this for a minute:
How does she represent this in the UI?
What are the requests here?
Which events are involved?
Without knowing much about the game Darline decides to let the players move by just hitting ENTER. If a move is more than that in the future, she can adapt to that in the UI. At least this way she knows when a move has been made and there is some interaction involved.
Making a move primarily is about a command: Move! This is supposed to change the state of the application. But in what way? She only knows that the players take turn. So the game state needs to keep track of who’s the current player. And that a move has been made.
So, should the command processor MakeMove generate one or two events? Darline is a fan of recording decisions with events:
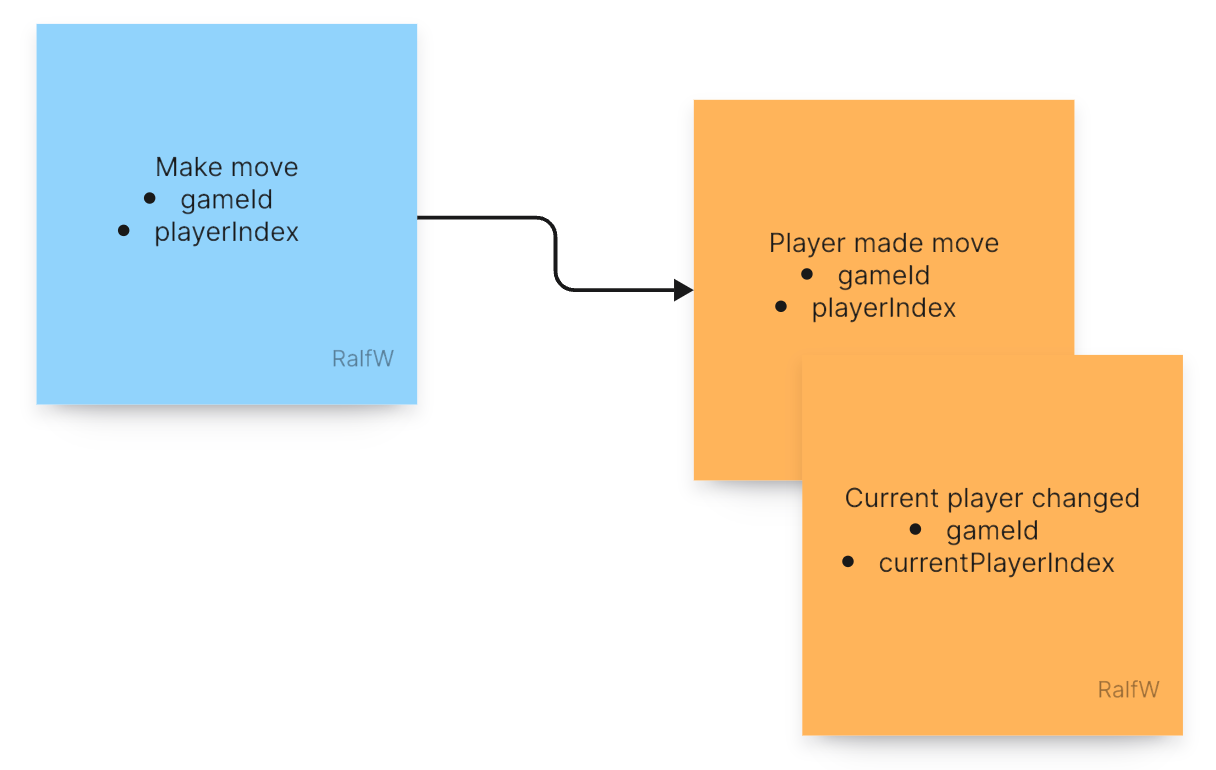
The first event to issue should be a
playerMadeMoveevent recording, well, that a player made a move. The decision for that was made by the player.The second event in addition to that is supposed to record the decision made by the application as to who’s next. “Players take turns” is a requirement looking for an expression in code to take responsibility for it (Single Responsibility Principle (SRP)).

As you can see both events are tied together by the same gameId. It is the thread running through them all.

The command processor again gets its own class initialized with the eventStore and just appends two events to the stream:

Nothing is checked for simplicity’s sake. The game is assumed to exist and the player index to be 0 (player 1) or 1 (player 2).
When is this command issued? After a user confirmed to make a move in the UI:

But where does the UI know the current player’s name from? So far only two player names were entered and recorded. No notion of a current player was present.
Increment 2.2 - … and a query
Two things need to be done to make the UI aware of current player.
First the current player must be established right when the game starts. It can only change by moving if there already was a current player.
So, this increment not only led to the creation of a new slice for the command to move, but also to a change to the previous slice:
The StartGame processor not only issues an event to start a game, but also sets the initial player.
Secondly, the UI needs to know who the current player is at least to display a fitting prompt. That means, another request has to be processed, this time a query.
The query’s result is the current state of the game which in its simplest form for now looks like this:

That’s all the information there is in the Event Store encoded in a sequence of events.
How to compile it? The Event Store has to be queried for all events of type gameStarted and currentPlayerChanged for the game in question.
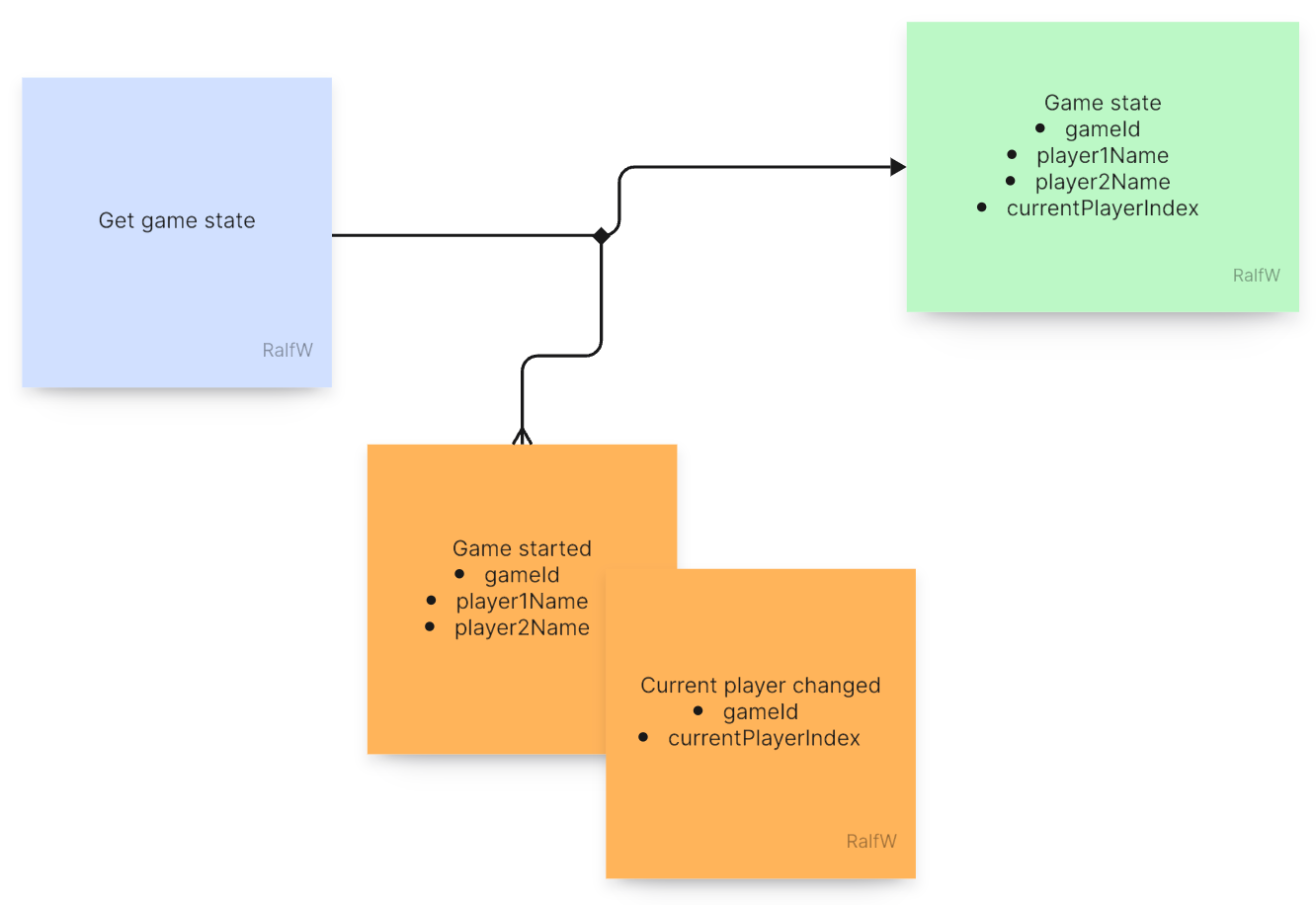
From those events the small GameState query response model can be built:

Where is the query issued? In the user interface before asking the users for the next move:

The current player’s name is chosen and displayed in the prompt. And afterwards the current player’s index is passed to the command to make the player’s move.
That’s all there is to this increment:
record the decision to move
record the decision about the next player
build a game state to displayer to the user
One new command, one new query, and one previous command changed. Except for the addition to the previous command Darline was able to work on a green field.2
Here’s the updated architecture of the application:
Reflection: When now looking back on the code of increment 2, I think it was wrong to pass the currentPlayerIndex to the MakeMove processor. That’s an optimization inviting violation of the rules. The processor could easily get to know who the current player is by querying the event stream itself. (Or at least it should check if the player index passed in is the correct one.) That way observing the game rules would more fully be a responsibility of the slices, not of the UI.
Increment 3 - Faking a feature
Increment number 3 is about a feature which cannot yet really be implemented. But still the overall code structure can be adapted and a new event can be introduced.
The feature is “a game can end as a win or a tie”. That’s all Pete reveals and Darline has to figure out how to manifest this in the code.
What’s immediately clear from Pete’s request is that there needs to be an event signifying the game has ended one way or the other.

And this event is the result of a command. Which command? Should it be issued as part of making a move? Sure, a move changes the application state and might create a configuration understood as a win for one of the players. But Darline does not want to put too much into the MakeMove processor. It should stay focus on “making a move”, whatever that means, and not also judge the resulting game state.
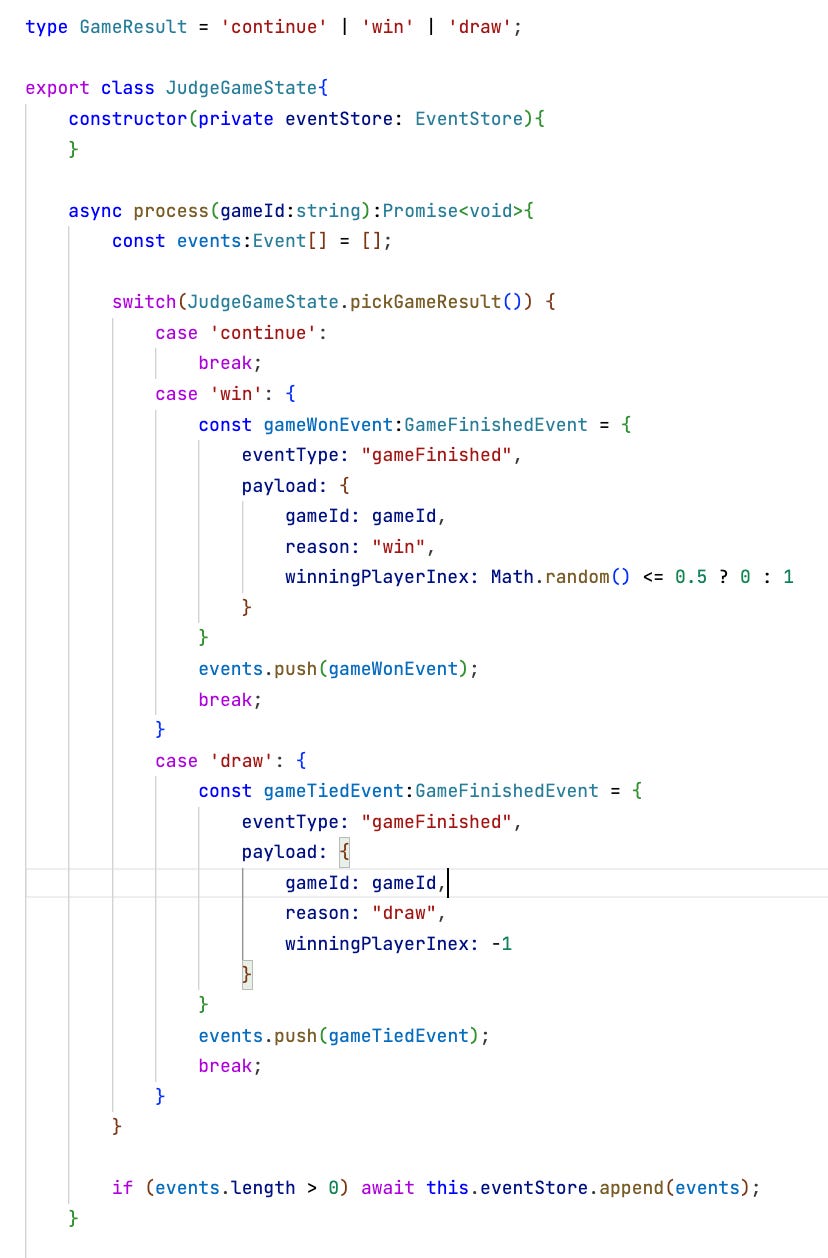
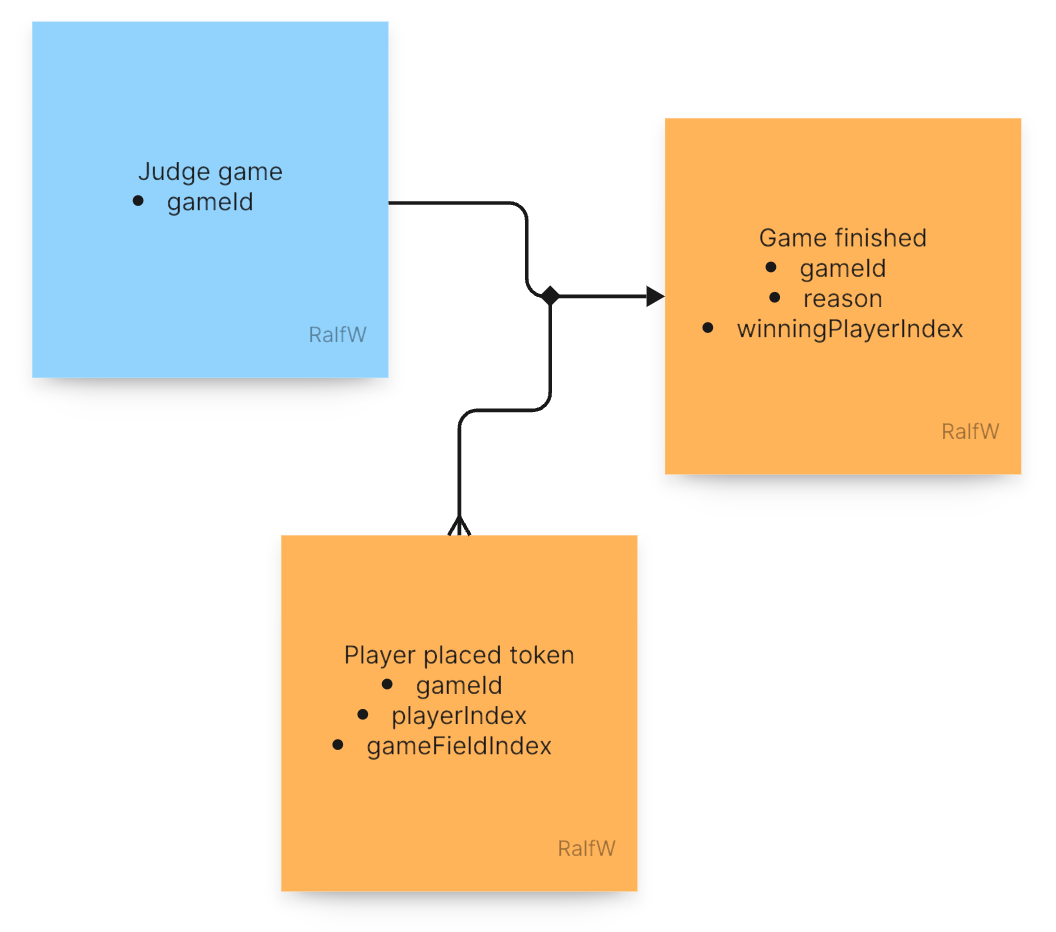
Hence she decided to create a second command just for judging the resulting game state: JudgeGameState.
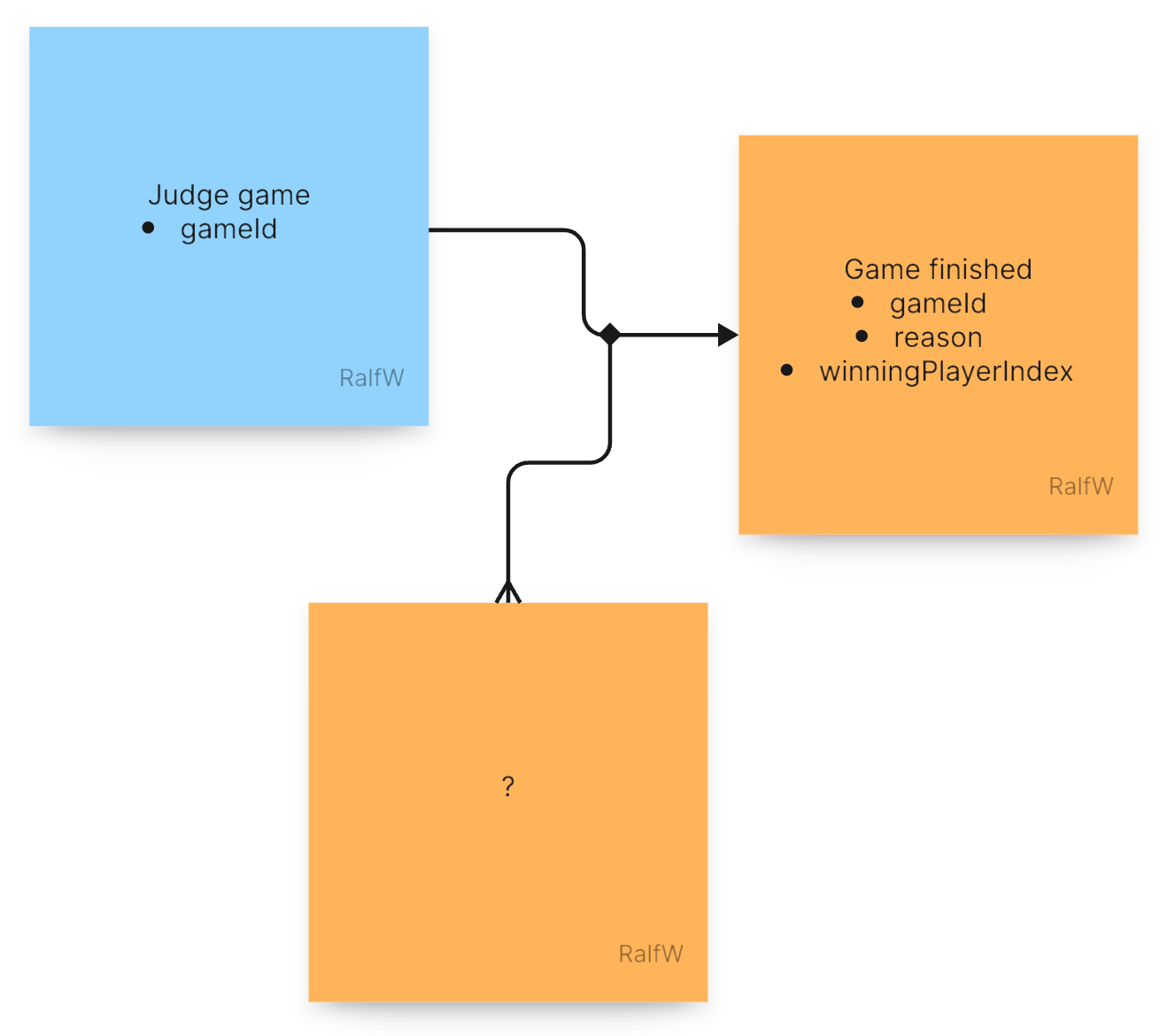
In the end the judgement sure will depend on other events (compiled into some kind of game state), but for now that’s not clear to Darline.
That leaves her with the uncertainty when to finished the game. It cannot be after the first move even though the judgement should be done after every move.
To make the application behave somewhat realistic even in this early stage she leaves the decision to chance. A judgement is called for after each move, but the judgement is indeterministic. A win only happens with a 20% chance, a draw with a 10% chance. That way the players can move a couple of times in turn until it’s game over.
Later the true rules can replace the random decision in the judgement processor. For now a “simulated judgement” will do, though.
This increment also leads to an interesting situation in the UI where the requests are issued:

Now two commands are run back to back. The output of the first in terms of events will likely have an effect on the events generated by the second. The first is changing the application state, the second is interpreting the application state and sometimes changes it, too.
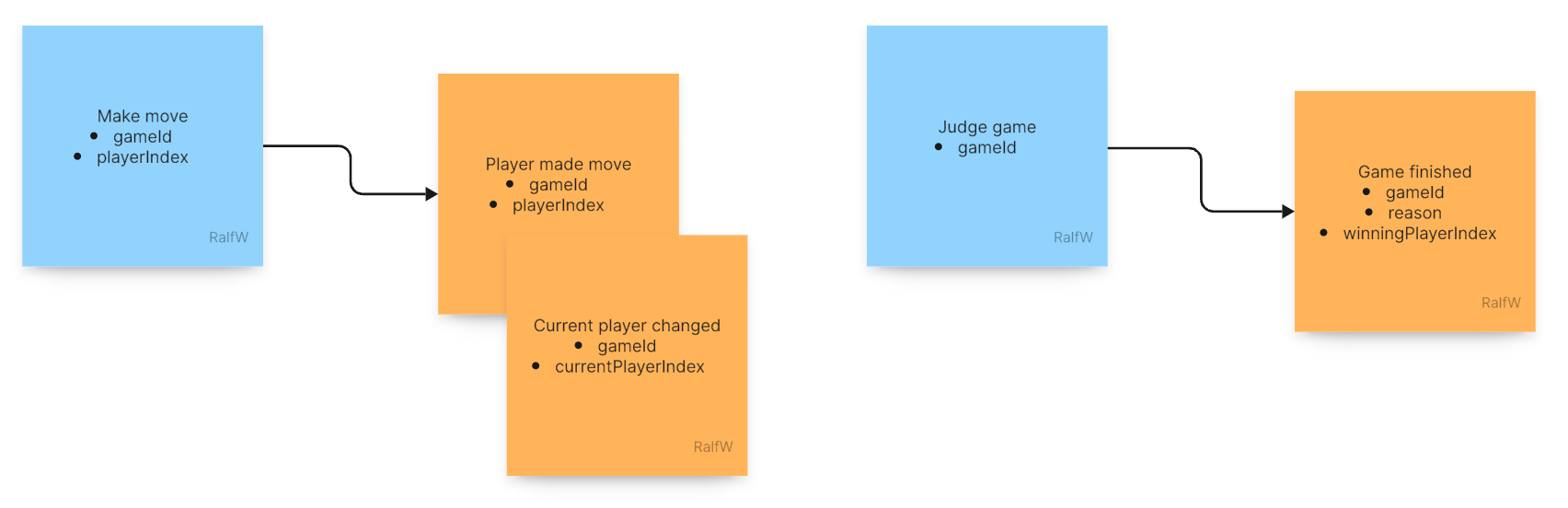
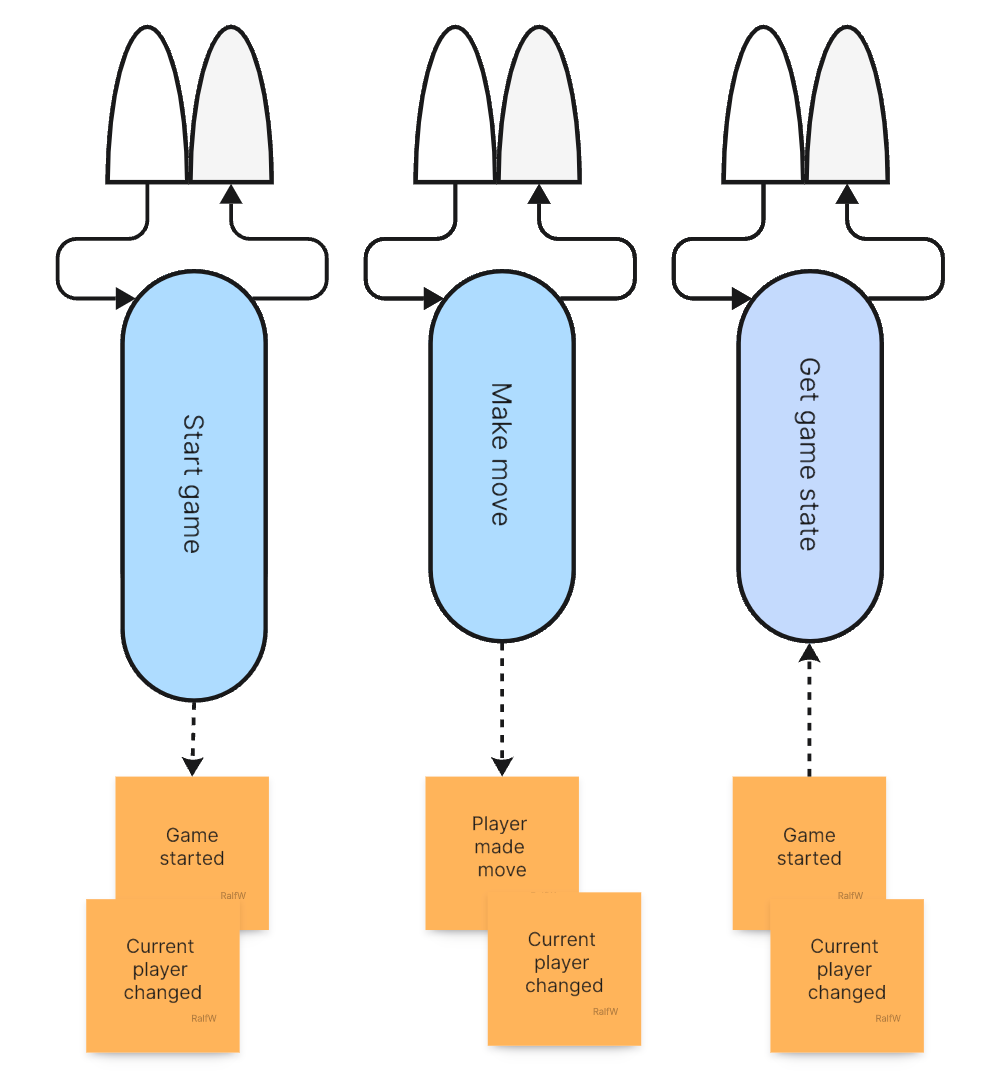
I like to visualize this as a data flow where processing steps are transforming data flowing between them:
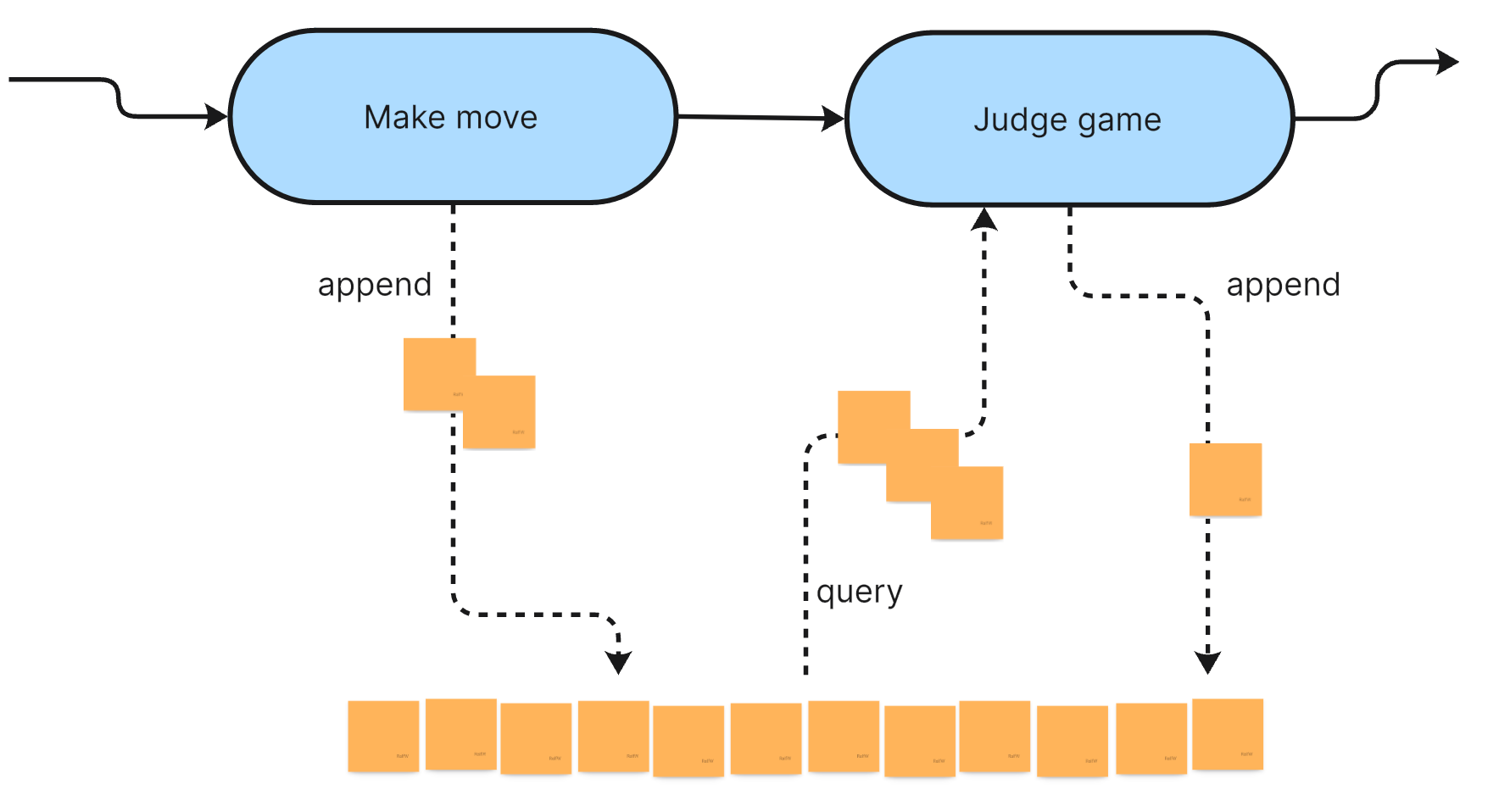
In this case, however, the data is not directly flowing from upstream steps to downstream steps. Rather each step is getting its input from the shared data source, the event stream, and outputs data to the event stream. Nevertheless it’s a multi-step process which can neatly be depicted to get a better overview once it starts growing.
With the game state now also including information about an end of the game, the “game loop” can be embellished:

In case of an end of game the result is displayed and the loop exited.
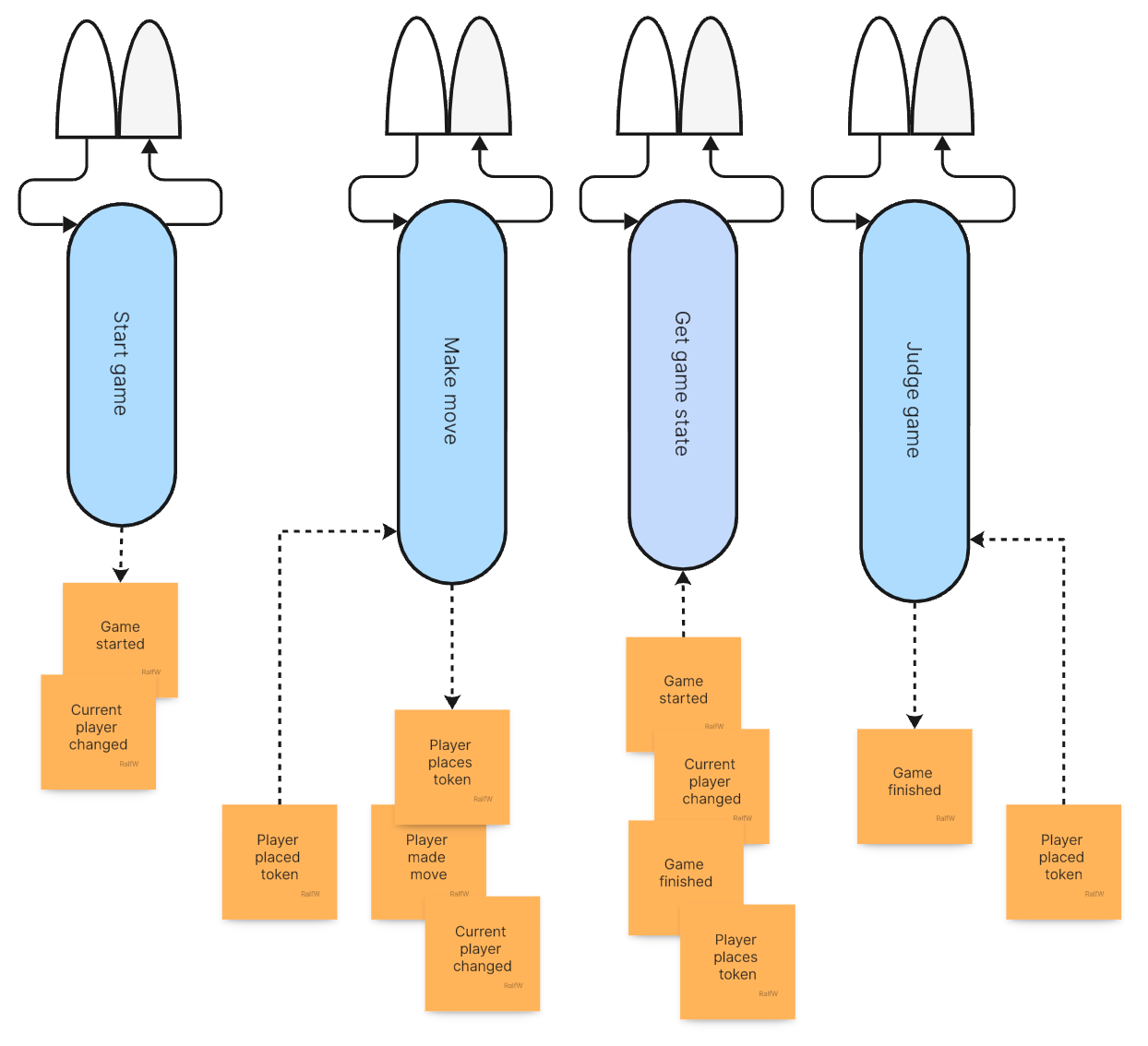
Finally an update on the application architecture. As you can see, it’s growing in two directions:
More slices are added. That’s good! It’s keeping features independent of each other.
Sometimes slices increase in size because a new requirements cannot fully be covered with a new slice but also needs changes to an already existing one.
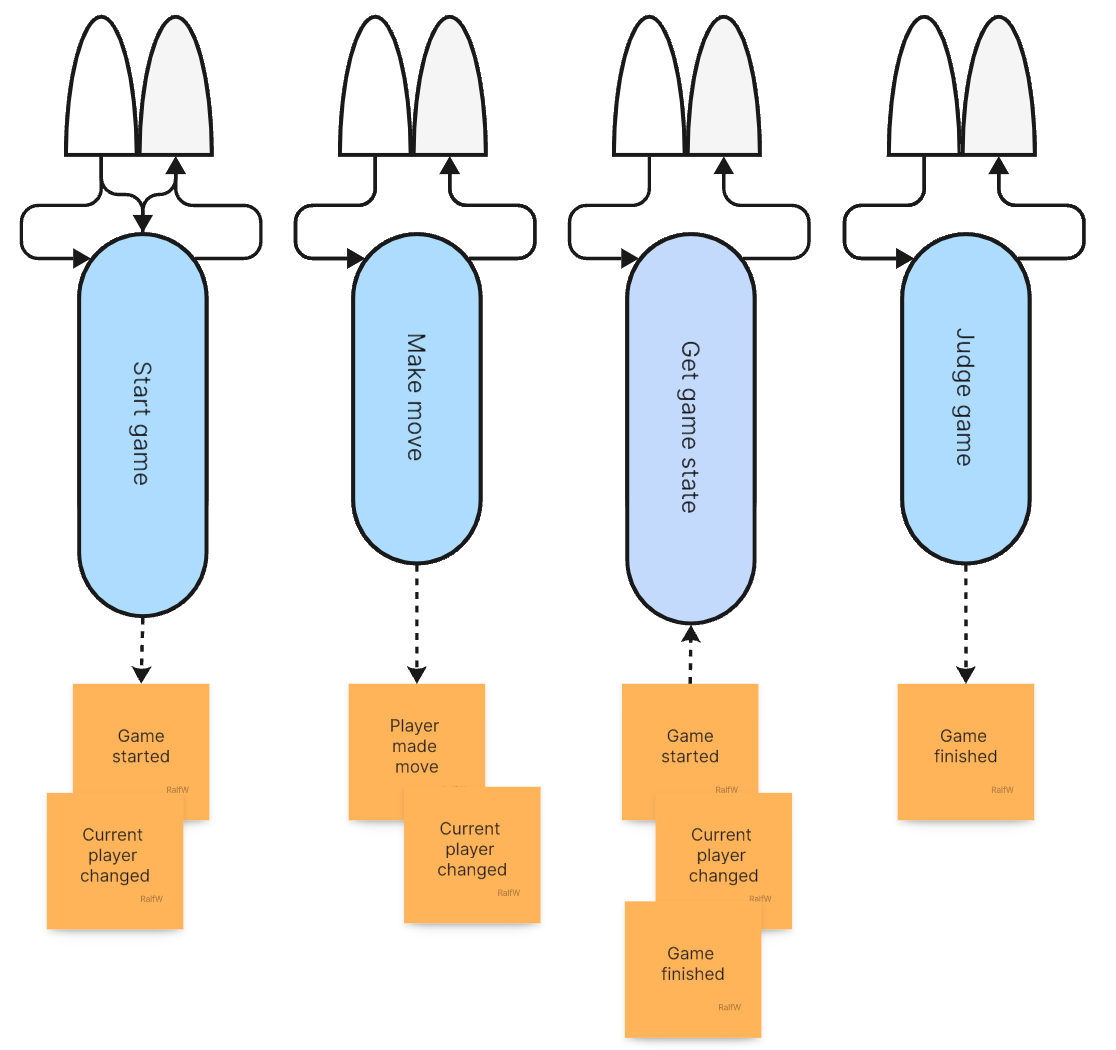
Increment 4 - Finally changing the game state
With the 4th increment Pete’s starts to reveal a bit about what players are actually doing when making a move: they are placing tokens in fields on a game board. Like in Reversi or Checkers or Tic Tac Toe or Go.
What’s the size of the game board? He does not say. Fields are just addresses with an integer index >= 0. And in each field a player specific token is displayed.
Darline figures this can easily be mapped to a new event:

Is there a new request? No. The event can be written as part of the MakeMove processor.
As a new parameter the index of the field is passed in.

This requires to collect the index in the user interface. Just hitting ENTER to make a move is replaced by asking for a field index.
How is that matched with a projections in the user interface? Since Darline does not know anything about the game board or the tokens, she decides to just display the moves made as a list of field indexes with the player’s index. That’s not user friendly, but at least shows the change in application state.
For that the query processor GetGameState needs to be adapted. It also needs to query for the new PlayerPlacedToken event type:

The query response model (GameState) also needs to be amended of course.
All in all this was yet another easy to implement increment. The uncertainty about what will come next or what the game is about, does not affect Darline.
The current structure of the application:
Reflection: When a player moves three events are generated. In hindsight this seems a bit of overkill. It’s very differentiated, but I am not sure if that’s really helpful.
Recording the change of current player decision I still think is important.
Recording the placement of the token is of course necessary.
But is a separate recording of a finished move helpful? Or should that be put together with the token placement?
For Tic Tac Toe I think token placement is enough. The information about that could have been added to the already existing playerMadeMove event. Changing event types is ok in Event Sourcing, even though not encouraged. The game field index could have have been added to the payload.
As it will turn out later, the playerPlacedToken will be the only of the two which will be queried for; the interesting information is the field index. Two different events are obviously not needed.
Still separating token placement and finishing a move makes sense when looking at games in general: there might be scenarios/games when “making a move” consists of placing several tokens. Recording the end of a player’s turn then would carry additional information and be warranted.
The way Darline and Pete progress she does not know what the nature of the game is. Hence she took a more defensive approach. So maybe it’s a good thing both events are issued.
Maybe, when in doubt, generate more events. Ignoring excess events later and maybe stopping to issue them is easier than missing them.
Increment 5 - Displaying a proper game board
Increment 5 finally reveals the nature of the game: it’s Tic Tac Toe. Pete’s wants the list of moves to be replaced with a 2D game board display with crosses and naughts as the players’ tokens.
That’s an easy task for Darline. It does not require any changes to slices. No new events have to be invented. It all works on the current query response model of GetGameState even.
A single function is added to the UI to render the list of game fields filled with tokens:

This is no high end GUI rendering, just “ASCII art”. Pete does not minds, though.

The terminal window as the place to play the game has been set at the beginning of the project.
No changes to the application architecture for this increment.
Increment 6 - A command needs to observe a business rule
With increment 6 things are becoming more serious. A first business rule is introduced: players may not place their tokens on fields already occupied.
Does that call for a new request? No. The existing command processor for making a move needs to be embellished with a check.

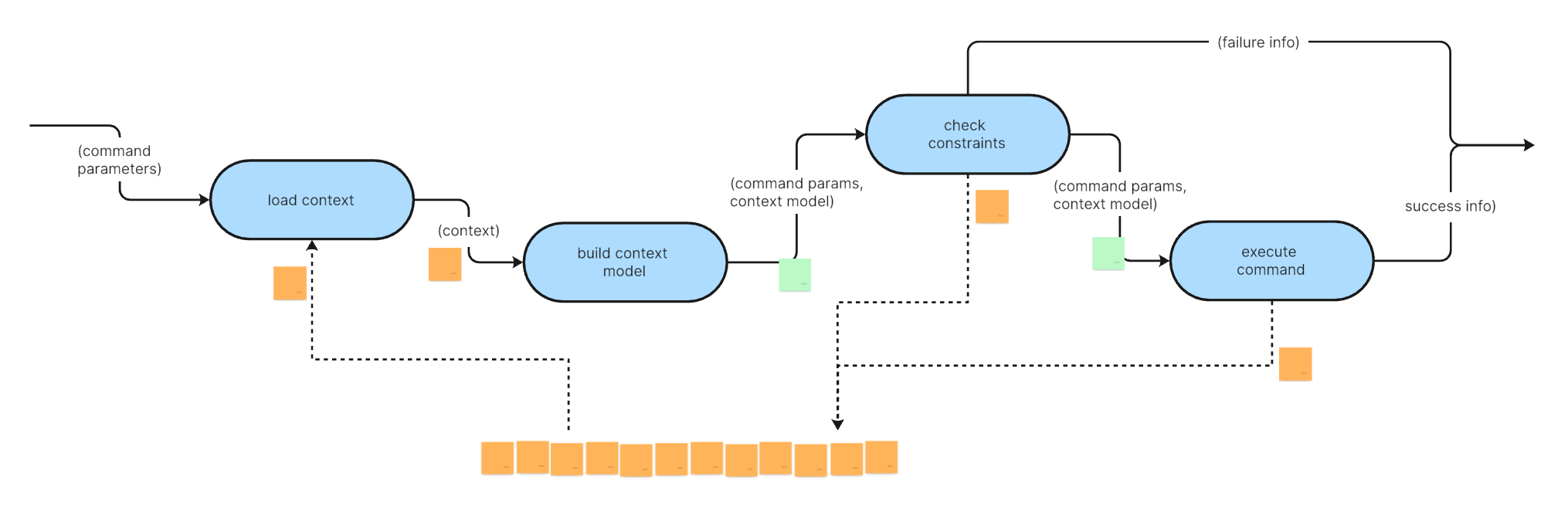
This is most typical for commands:
Check constraints.
If constraints are met, the application state is in order from the point of view of a command, execute the command. Do whatever is necessary in terms of transformations.
Finally generate new events to persist the changes made by the transformations.
Checking the constrains means getting relevant application state, i.e. querying the event stream for events pertaining to the command with its actual parameters. That’s the context of a command.
Depending on the number and kind of events in the context a context model is built from them, i.e. they are “reduced” to a compact data structure. The GetGameState query processor is an example for that.
For the command in question, though, Darline does not deem that necessary. She thinks it’s enough to query the event stream for an already existing token placement on the same field during the game. If the context contains one such event, then the field is already occupied and the current move invalid.
The context model thus is just the number of events in the context. Very simple, no further “map/reduce” necessary.
Querying the event store means passing a filter to the Event Store’s query() function. It consists of
the types of events to retrieve from the event stream,
one or more patterns the payloads of those event must match.
In this case Darlin is only interested in token placements for the current game and on the field given. It’s not important who made the placement or when they where made.
No new request is needed, but of course the user interface has to mirror this change to the working of the processor. An error message is displayed and the player is asked to try again:

In CQS commands change state, but don’t return a result, and queries return a result, but don’t change state. Commands also can fail, queries not.
The MakeMove processor thus still conforms to the CQS principle. It does not return a “calculated” result, but just meta information about the job it did: Was it a success? If not, what was the reason.
That’s different from the GetGameState processor which returns a “calculated” game state distilled from events.
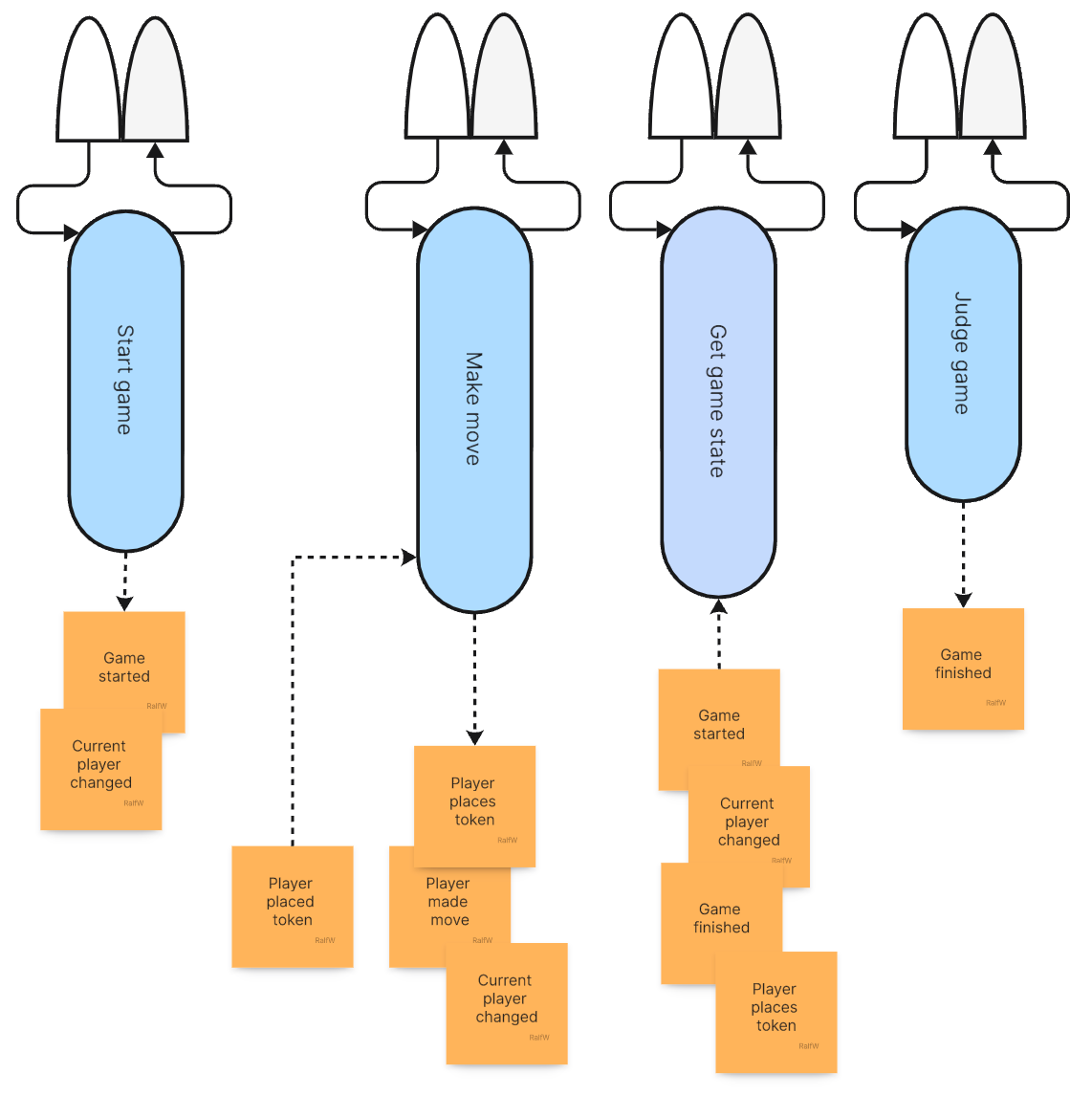
The application architecture shows the change in handling commands. For the first time events are input to a command, not just a query:
Increments 7 & 8 - Adding the main business logic
The next two increments I want to cover as one. Increment 7 and increment 8 are about finishing the game with a win or a draw.
Darline gets the information in two chunks, but as it turns out it’s all pretty much the same, just more of it. She needs to find a place where to put the decisions about whether the game has reached an end by the previous move of a player.
So far the judgement has been random and not based on actual events. This only needs to be replaced by proper decision logic. No new request is needed. Also the display hardly changes.
Game rules are business logic. They are at the heart of the domain. The most important question is: What data do they work on? What part of the game state has to be retrieved from the event stream?
As it turns out, all the information needed is in the playerPlacedToken events of a game. They fully describe the current game board configuration.
Now Darline just has to decide what kind of context model to build from this context. Users see a 2D representation of the board. However, Pete’s lets them input field indexes as if it was a 1D array of fields. (Which might change in a future increment. Why not let users specify a field with a 2D coordinate, e.g. A1 or B3, instead of indexes, e.g. 0 or 7? The translation between 2D and 1D would be a matter of the UI, though, I guess.).
Darline stays with a 1D array where the content of each element is the index of the player who put a token on the corresponding field. That’s her context model.
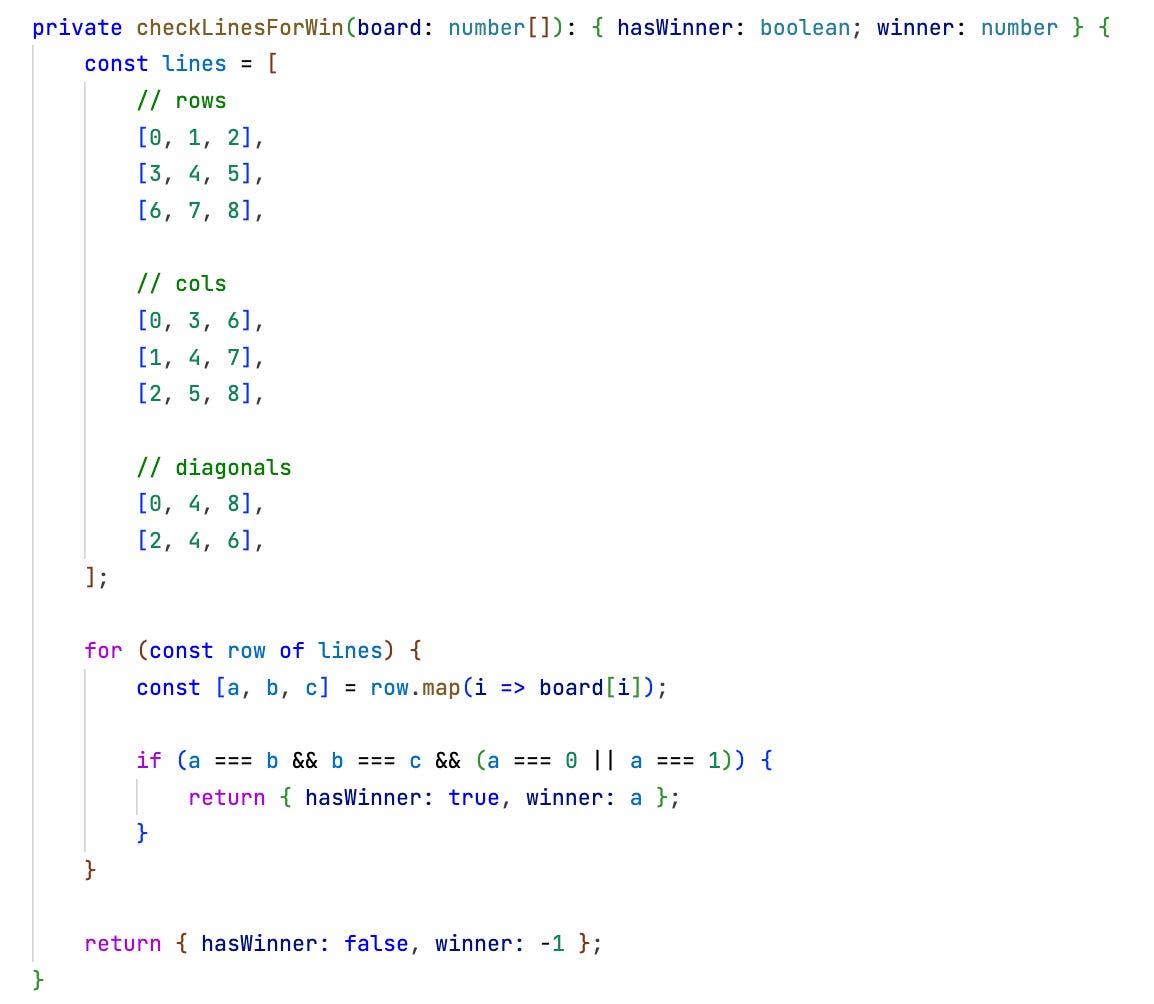
The business logic to check for a win or draw she puts in a pure function — checkLinesForWin() — to work on the context model.
The remainder of the command processor generates the event matching the judgement, if the game is over.

Due to the small size of the game board it’s easy to code the check for a win. It’s always tuples of three fields that need to be checked. If all contain the same player index the player wins.
I know from experience in many clean code trainings where I used Tic Tac Toe as an example how tedious discussions about the right representation of the game board and the moves in memory and on disc can be. Darlin has been spared all this due to Event Sourcing, though.
To record a move as {playerIndex, gameFieldIndex} seemed very natural. And not bigger picture was needed, no compromises needed to be entered to make current or future slices happy. This tuple best captures what’s the fact in the moment when making a move.
What later on slices will do with that for their own responsibilities, is a completely different matter. For JudgeGameState it’s fine to “pour” those events into a 1D array as context model, for GetGameState it’s a list of tuples, but could have been a 2D array. The slices are not connected beyond sharing the same event stream. For each Darline is completely free to choose a context model optimized for the task.
This is so much easier than what I remember from my trainings when I still had not introduced Event Sourcing to them. Today I am approaching clean code development very differently.
Here’s the final structure of Darline’s application:
Reflection: Please notice: There is no constraint check in this slice. Darline decides against ensuring that the game hasn’t been finished already. She is assuming a certain use of the slices under the umbrella of her user interface.
In a more distributed project (more developers working on more slices which then run in different services in parallel) it might be wise to check that first, though. The GameFinished event would be included in the filter and first looked for in the context returned from query(). If present, the nothing further would need to be done (and no error would need to be reported).
For Darline’s scenario, though, this constraint did not seem necessary. So she skipped it. For now at least. If Pete’s comes up with some more ideas, it’s trivial for Darline to add it to the command processor later.
Increment 9 - Making the solution a bit more bullet proof
Speaking of constraints: Increment 9 is not requested by Pete, but by Darline. She feels a bit uncomfortable because she from her point of view a constraint check is missing. No on the JudgeGameState command, but the MakeMove command.
A user could technically make a move even if the game was over already. Again, this is not possible with the given user interface, but still. She’s feeling uncomfortable about this and wants to build in a check.
That’s done quickly. Only one more event needs to be added to the context of MakeMove: gameFinished. If that event appears in the context of the command processor, then the move won’t be allowed anymore.

It’s another testament to how flexible a sliced architecture based on an event stream is. The change necessary was very local. The users won’t even see a difference.
Context is king. Darline just widened it a little bit to check the new constraint. A local intervention. It cannot possible affect any other slice, because no shared code was touched.
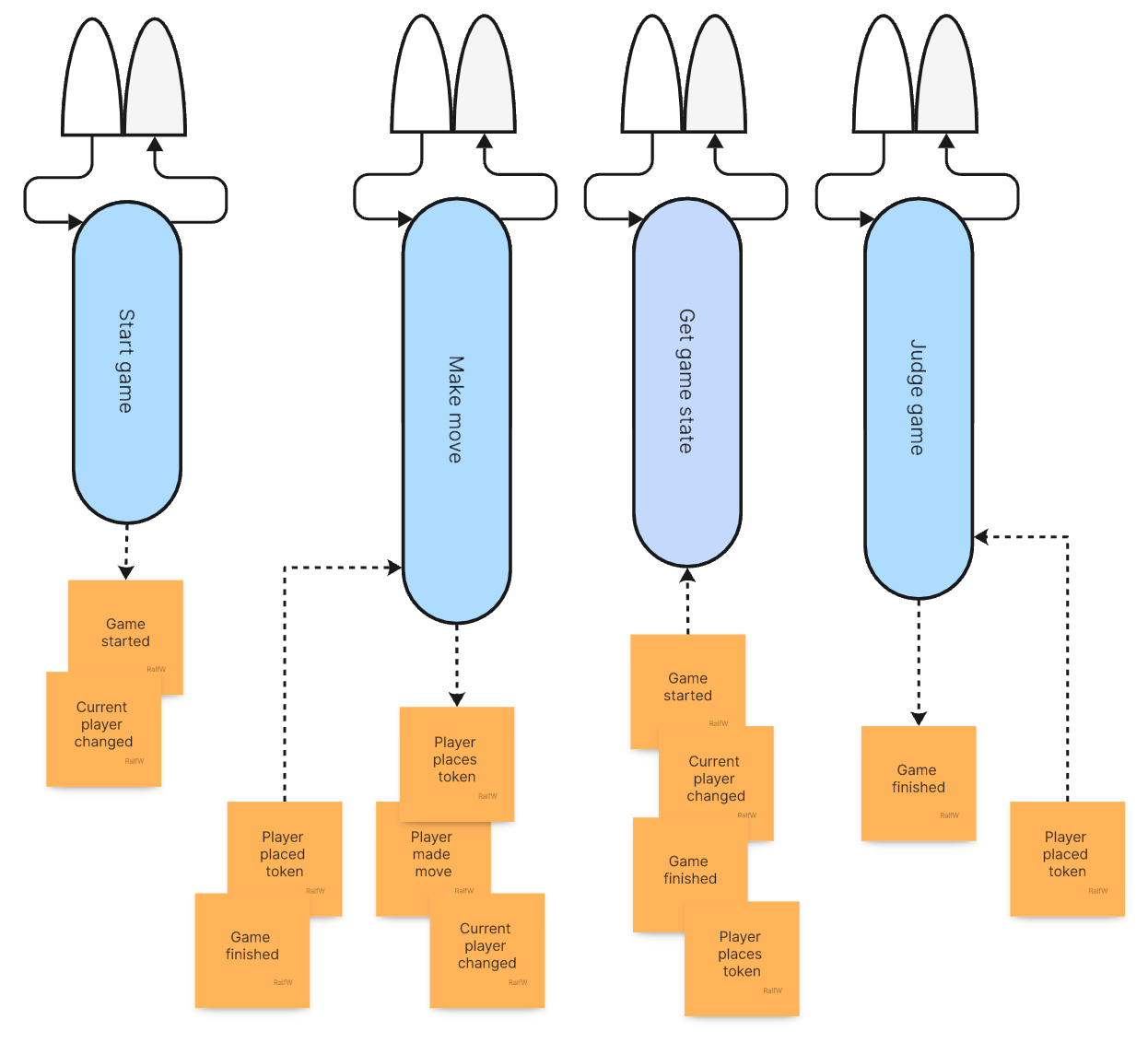
The application architecture hasn’t changed. Just one command handler was “expanded” a bit:
Increment 10 - Going beyond the usual game rules
After such an enjoyable software development experience Pete’s feeling lucky. In increment 10 he invents a new rule for the game: if a player makes two invalid moves in a row it becomes the other player’s turn.
This is looking not too difficult to Darline. A new event should take of that. It’s another example of how beneficial it is to record decisions when doing Event Sourcing. You never know this might come in handy.
Of course, also here beware of premature optimization. Still, though, I think you should be conscious about when your business logic makes a noteworthy decision. In this case it’s the decision that a move is invalid.
So far this only led to a failure of command MakeMove. But why stop there? Why wasn’t this recorded in the first place when implementing increment 6? It only success worthy of remembering? Maybe not.
On the other hand: it’s easy to add this now. It’s never too late with Event Sourcing and slicing, you could say.
The basic logic to check for an invalid move stays the same. The context is checked for a playerPlacedToken on the field where the current player wants to move.
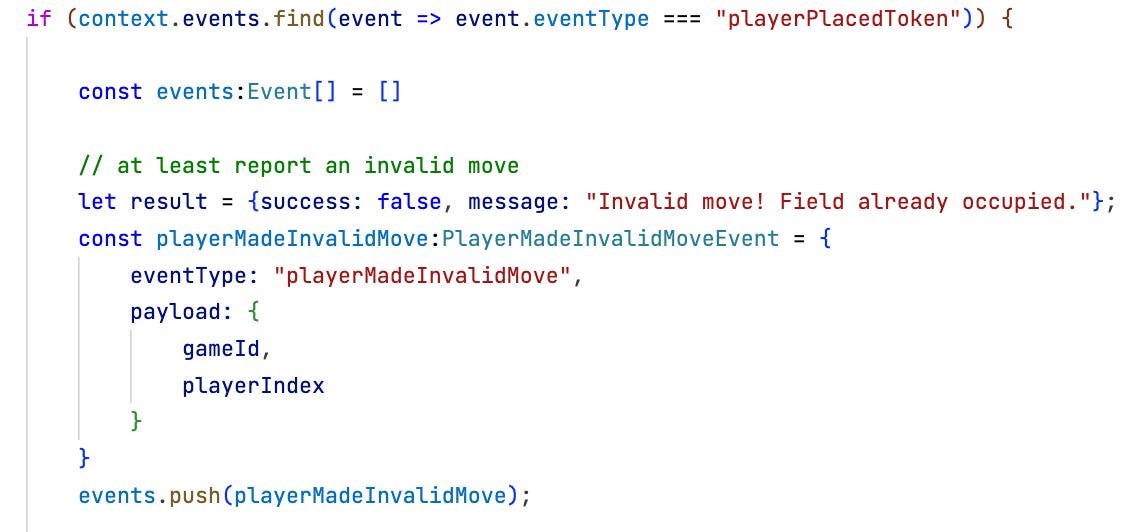
But in addition it has to be checked if that has happened already right before. And if so switch to the other player.
The condition is simple: the last event in the game has to be a playerMadeInvalidMove. If that’s the case no successful token placement happened before and the game cannot be over yet.

Now not only a second invalid move gets appended to the event stream but also a change of the current player.
This is obvious to Darline and simple to implement. But she runs into a problem. It does not work as expected. The wrong events get selected. Invalid moves are flagged too often. Why?
As it turns out the filtering feature of the Event Store is not fine grained enough. It allows to pass in a number of event types to select plus a number of payloads to match. The Postgres SQL query where-clause getting built from that looks something like this:
(eventType1 OR eventType2 OR …)
AND
(payloadSubset1 OR payloadSubset2 OR …)The payload patterns in the filter get applied to any event selected through the event types. This can result in too many events returned; the payload condition is not specific enough.
Darline has to work around that by implementing a multi-filter query herself. First she sets up the filters very specifically by matching event types with payloads:

Notice how for example the playerPlacedToken events now only get selected when the gameId and gamefieldIndex match irrespective of the playerIndex. But the playerMadeInvalidMove events get selected when gameId and playerIndex match. Without this differentiation more playerPlacedToken events would be drawn into the context — leading to wrong signalling of an invalid move.
Darline gets this to work by querying the event stream for each filter separately and then joining all results into a single context:
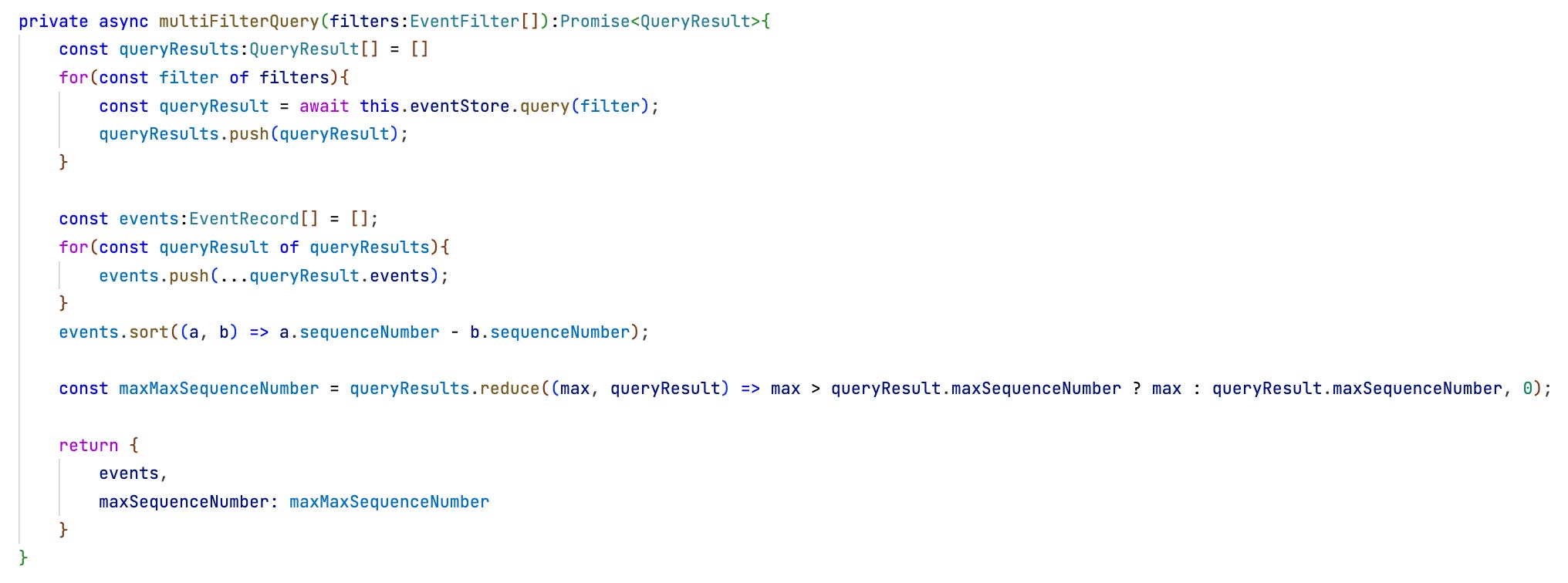
This of course causes a performance hit: 4 queries on the raw event stream instead of 1. But in the particular case with Pete playing only with his family — so far — that’s not a problem. Ultimately, though, the event store implementation has to be improved.
This unexpected technical problem solved there is only one thing left for the user interface: the game state has to be loaded again after an invalid move since the current player might have changed.

Darline decides in favor of reusing the existing query even though only one piece of information from the game state is needed. Setting up a more focused new query to just get the current player does not seem worthwhile to her within the overall expected usage of the application.
All in all this does not change the sliced architecture much:
Update 01.08.2025: The Event Store implementation has been updated. Darline’s workaround for multi-filter queries is not necessary anymore. They are natively supported by the Event Store as EventQuerys.
Multiple filters are assembled into a query using createQuery() and passed to the EventStore query() method:

There is no performance hit anymore due to multiple passes over the event stream.
Conclusion
If you made it to here: Thanks for your attention and patience! I know, it was a long journey from the initial idea for an application through 10 increments. But I still hope it was as insightful as it was for me.
What did I learn from Darline and Pete?
Moving forward in an Agile way with very small increments is possible with Event Sourcing and a Vertical Slice Architecture. Up-front analysis and design can be kept to a minimum or skipped altogether in favor of faster implementation and quicker feedback. There is much less that can be broken when working on the next increment.
Increment implementations are cleanly separated into slices catering to separate request with clear basic responsibilities: commands change the event stream, queries just read it. What they share are fine grained facts from which each can build whatever internal representation fits the bill best. This not only decouples code enormously it also decreases the need for communication between developers.
The analysis phase naturally informs the design and implementation phase. What’s tangible for users (requests to an application consisting of input collection and output projection) directly maps to the basic structural elements of code: slices.
Slices in turn have a simple recurring structure, too. It’s even boring, I’d say:
Commands query the event stream for a context, build a context model, check constraints, serve the request, and finally append some events to record any application state changes.
Queries query the event stream for a context, build a context model, and return it (or a subset) as their result.
The user interface concern (collection and projection) is neatly separated from that. Developers can keep it simple or become real artists as they like; it’s not affecting the basic architecture of the application.
Likewise persistence of application state is a non-issue. It’s taken care of once and for all by the Event Store. No schema design needed beyond shaping small data structures (events). This is a boon for testing: a persistent Event Store can be replaced by an in-memory Event Store filled with just a couple of test-specific events. That’s not only simple to do, it’s also fast.
What’s left is… business logic. Finally developers can focus on that feature by feature without stepping on each others feet. It’s like going through a checklist:
Which events make up the context of a feature?
Which events should be generated?
What should the context model look like?
Which constraints to check?
What are the decisions to be made at the heart of a slice to serve the request?
I find this a great blueprint for software development from analysis to implementation. It’s spanning the whole process.
To me Event Sourcing is becoming the default for primary application state storage.
And with the event store Rico and I started that’s really put at the fingertips of every developer. Either you use it directly in your Javascript/Typescript project or you host it as a small server with an HTTP API or… you run it through some AI and get it translated to your programming language. An Event Store based on an existing persistence technology like an RDBMS can be a small piece of software saving you from a lot of headaches.
Give it a try! It’s free!
Update: Now an in-memory Event Store is available in the open source implementation by Rico and me. It’s a drop in replacement for the Postgres EventStore implementation.
Before:

After:

That’s all Darline would have to change to switch from storing application state across runs in a Postgres RDBMS to keeping it just in memory for the duration of a single run.
Sure, I as the author had the big picture all the time. But I really made an effort to not look ahead and let Darline’s code mirror that. It stays a demo though, a staged example. Nevertheless I think there is truth in it; something can be learned from it. So, humour me, please.
Not true for the user interface, though. That’s another reason I want to keep that topic out of my description. The UI is hard to keep clean because it’s the natural point to integrate all slices. On the other hand that means, I think, we should push as much code out of the UI as possible into slices. Keep the UI as thin as possible. Makes testing easier, too.