


Wo ist die Prävalenz hin?
Kann man die Durchseuchung der Bevölkerung mit RKI-Zahlen berechnen, wenn schon nicht messen? Ja — aber das Ergebnis ist strange.


Das klingt gefährlich: 4,1% der SARS-CoV-2 Infizierten sterben (Quelle: RKI Lagebericht KW 33).

Aber wieviele Menschen sind eigentlich mit SARS-CoV-2 infiziert? Wie groß ist das Sterberisiko wirklich? Denn 4,1% ist ja nur der Anteil an den bekannten Infizierten (den positiv Getesteten). Wieviele unbekannte gibt es darüber hinaus? Wie hoch ist mithin die so genannte Prävalenz für die Infektion in der Bevölkerung, d.h. wieviele sind insgesamt infiziert (ob per Test gefunden oder nicht)? Ist die Prävalenz 226.914/83.000.000=0,0027=2,7‰? Nein, sicher nicht. Sie muss höher sein, denn es werden ja nicht alle wirklich Infizierten mit einem Test entdeckt und auch nicht alle Bürger getestet.
Angenommen, die Prävalenz wäre 1%, dann gäbe es in Wirklichkeit 830.000 Infizierte in Deutschland, von denen 9.243 gestorben sind. In dem Fall wäre der Anteil der COVID-19 Verstorbenen nur noch 0,011=1,1%. Das hört sich schon besser an, oder? (Annahme: Spätestens im Todesfall wird eine Infektion festgestellt.) Aber vielleicht sieht die Situation ja noch besser aus?
Angeregt durch dieses Video von Samuel Eckert möchte ich der Frage nach der Prävalenz einmal mit den Mitteln der Mathematik nachgehen. Vielleicht hast du Lust, mitzudenken…
Katzen als Versuchskaninchen
Aber erstmal ein Beispiel (Qulle: MathsIsFun) aus einem ganz anderen Bereich: Katzen. Was könnte passender sein für eine Internetveröffentlichung, als ein Beispiel mit diesen süßen Tieren zu bringen?
Petra erzählt ihrem Freund Robert, sie hätte neulich ihre Freundin Sabine besucht und seitdem würden ihre Arme jucken. Könnte das an der Katze von Sabine liegen, die sich ihr ausführlich angeschmiegt hätte? Die war sooo kuschelig, da hätte sie nicht widerstehen können, sie zu streicheln. Robert rät Petra, einen Allergietest machen zu lassen. Leider ist der Allergietest nur begrenzt sensitiv und spezifisch: Falls Petra eine Katzenhaarallergie hat, dann zeigt der Test das mit pS=0,8 (80%) an. Hat sie jedoch keine Allergie, kommt es immer noch mit einer Wahrscheinlichkeit von 0,1 (10%) zu einer (falschen) positiven Meldung; die Spezifizität des Tests ist pZ=0,9 (90%). Allgemein gilt für die Bevölkerung: 1% aller Menschen haben eine Katzenhaarallergie (Prävalenz, pP=0,01).
Die Frage hier zunächst: Wie wahrscheinlich ist es, dass Petra im Falle eines positiven Testergebnisses tatsächlich eine Katzenhaarallergie hat?
Etwas formaler ausgedrückt: Gegeben die Hypothese “Petra hat eine Allergie”, wie groß ist die Wahrscheinlichkeit, dass die korrekt ist angesichts des Ereignisses “Positiver Test”?
Mit dem Bayes Theorem kann man das ausrechnen:
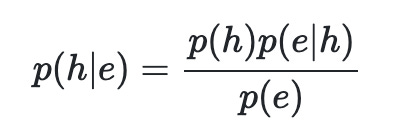
p(h|e) steht für die Wahrscheinlichkeit, dass die Hypothese h korrekt ist beim beobachteten Ereignis e. Die Wahrscheinlichkeit ergibt sich…
aus der “Grundwahrscheinlichkeit”, mit der man einen h-Fall überhaupt beobachten kann (p(h)=pP=1%) aller Menschen haben eine Katzenhaarallergie),
multipliziert mit der Wahrscheinlichkeit, dass eine tatsächlich vorliegende Allergie auch mit einem Test erkannt wird (p(e|h)=pS=80%), die Sensitivität des Tests)
und diese kombinierte Wahrscheinlichkeit wird dann in Relation gesetzt zur der, dass überhaupt in Tests ein positives Ergebnis herauskommt (p(e)=seien das true oder false positives).
Diese Erklärung macht es wohl für dich nur bedingt besser als die Formel. Deshalb ein Bild zur Situation des Beispiels:
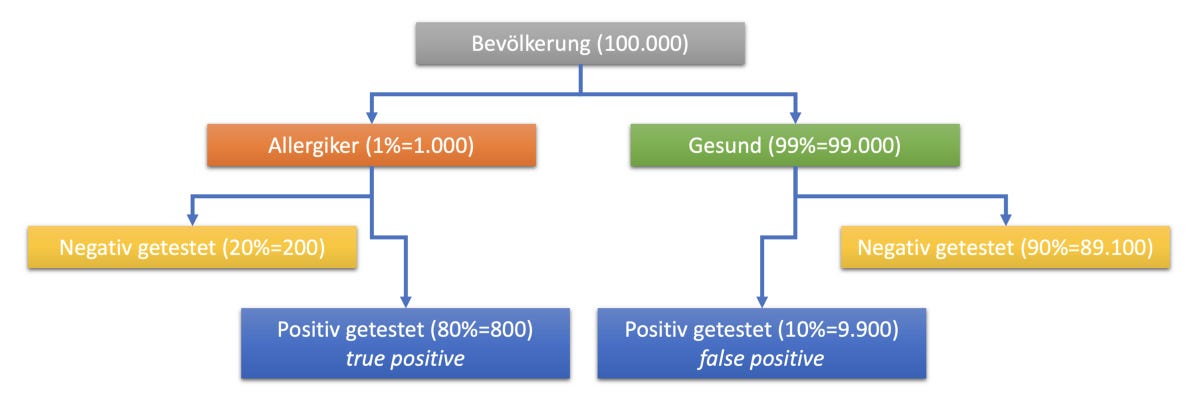
Ist Petra bei einem positiven Test eine Allergikerin (true positive)? Das lässt sich anhand der Grafik sehr simpel ausrechnen. Es gilt:

Mit eingesetzten Zahlen ist das Ergebnis dann:

Das bedeutet, auch bei positivem Test muss sich Petra keine großen Gedanken machen, denn die Wahrscheinlichkeit ist nur 7,4%.
Hättest du das gedacht? Was wäre deine “Schätzung” gewesen, wie wahrscheinlich es ist, dass Petra eine Allergie hat, nur weil sie sich nach Katzenkontakt kratzt und einen positiven Test hat?
Die meisten Menschen schätzen die Wahrscheinlichkeit sehr anders, d.h. viel höher ein. So ist eben die Intuition ausgebildet (oder auch fehlgeleitet). Das geht den Besten so, auch Profis, z.B. Ärzten. Mach dir also keinen Kopf.
Bevor es weitergeht noch kurz die Probe aufs Exempel mit der Mathematik des Bayes Theorem. p(h) und p(e|h) sind der Aufgabenstellung zu entnehmen. Aber wie groß ist p(e), also die Wahrscheinlichkeit, irgendein positives Resultat zu sehen?
Dazu sind zwei Wahrscheinlichkeiten zu addieren:
Einmal die Wahrscheinlichkeit, ein true positive zu bekommen. Das ist derselbe Wert wie im Zähler der Division.
Dazu kommt dann aber noch die Wahrscheinlichkeit, ein false positive Ergebnis zu bekommen. Die ergibt sich aus der Wahrscheinlichkeit, nicht allergisch zu sein (1-p(h)), und aus der Wahrscheinlichkeit eines dann fehlschlagenden Tests (1-pZ).

Tatsächlich, die Formel liefert dasselbe Ergebnis. Sehr schön!
Prävalenz unbekannt
So weit ein einfaches Beispiel, wie es so oder ähnlich in der Literatur steht. Dabei sind die Wahrscheinlichkeiten für die Äste auf beiden Ebenen gegeben. Insbesondere ist die Prävalenz gesetzt, hier: 1% aller Menschen sind Allergiker. (Wie man das herausgefunden hat, ist egal. Wahrscheinlich nicht mit dem in Frage stehenden Test.)
Aber was, wenn die Prävalenz fehlt? Man hat nur einen Test von bekannter Sensitivität und Spezifizität und weiß, wieviele Tests man mit welchen Ergebnissen gemacht hat.

Kann man jetzt die Formel anwenden, um herauszufinden, was p(h)=pP, also die Prävalenz ist? Ja, das geht tatsächlich, denn es gilt ja:

Auf der rechten Seite stehen die Formelteil, die zu den Werten in den beiden dunkelblauen Kästen führen (true und false positives). Da wird die Testanzahl jeweils multipliziert mit den kombinierten Wahrscheinlichkeiten von der in Frage stehenden Prävalenz (pP) und Sensitivität bzw. Spezifizität.
Diese Formel ist nun nach pP aufzulösen. Alle anderen Werte sind bekannt.

Das sieht noch knifflig aus, weil pP mal in der Klammer steht und mal außerhalb. Mit ein wenig Konzentration ist das aber kein Hexenwerk, sondern nur Schulmathematik bis Klasse 7.

Und da ist sie, die Prävalenz: 0,01 = 1%. So, wie sie im ursprünglichen Beispiel gegeben war.
Es geht also: Man kann aus absoluten Test- und Ergebniszahlen bei gegebener Testqualität auf die Prävalenz schließen.
Corona Prävalenz
Am Anfang habe ich die Frage gestellt: Wieviele Menschen sind eigentlich mit SARS-CoV-2 infiziert? Diese Frage lässt sich nun aufgrund der RKI-Daten und Aussagen zur PCR-Testgüte ermitteln. (Ich lasse dabei unberücksichtigt, dass die Getesteten wahrscheinlich eine positive Selektion darstellen. Sie bilden keine repräsentative Stichprobe, sondern sind tendenziell wohl schon irgendwie mit Symptomen auffällig geworden. Eine ermittelte Prävalenz ist deshalb wohl höher als die in der Gesamtbevölkerung.)
Was ist bekannt?
Anzahl der durchgeführten Tests: Laut Lagebericht des RKI vom 19.8.2020 wurden bisher 10.197.366 Tests durchgeführt.
Anzahl der positiven Tests: Laut demselben Lagebericht sind es 264.990. Das sind sowohl true wie false positives!
Sensitivität der Tests: Laut CORRECTIV-Recherche ist die Sensitivität 95% bis 100%; im Weiteren soll ein gehobener Mittelwert von 98% angenommen werden.
Spezifizität der Tests: Laut derselben Recherche ist die Spezifizität zwischen 95% und 98%; im Weiteren soll ein gehobener Mittelwert von 97% angenommen werden.
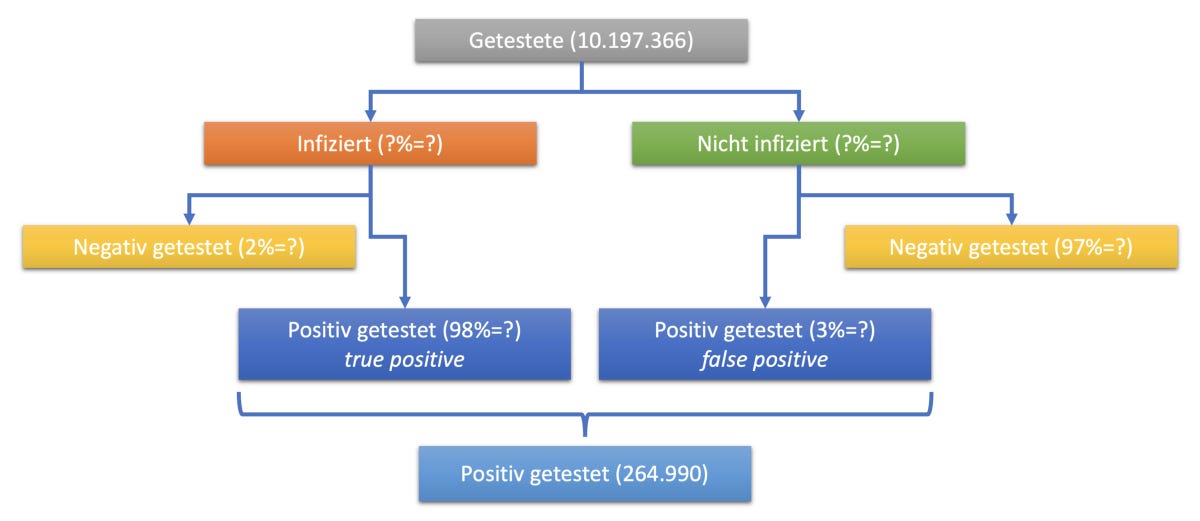
Die Positivrate über alle Tests hinweg ist laut RKI ca. 2,6%. Ist das aber die Prävalenz, also die Durchseuchung der Bevölkerung (oder auch nur der Getesteten)? Nein, natürlich nicht. Der Wert bringt die (unbekannte) Prävalenz und die Testgüte (Sensitivität, Spezifizität) nicht in Anschlag.
Also, wieder ran an die Mathematik. Die Formel ist dieselbe wie oben:

Aber jetzt will ich nicht nochmal mit dir durch die ganzen Umformungsschritte gehen. Ich habe die Formel deshalb einmal allgemein umgeformt und zusammengedampft auf:

Nur !pZ ist darin neu und steht für (1-pZ), d.h. den Anteil der false positive Ergebnisse.
Wenn ich nun in diese Formel die Daten von oben einsetze, ergibt sich folgendes Bild:

Und das Ergebnis der Kalkulation ist?

Aber was ist das? Die Prävalenz ist negativ? -4,3‰? Was bedeutet das? Das ist das Ergebnis bezogen auf alle Getesteten und alle positiven Tests bis KW 33.
Wenn ich die Zahlen jedoch nur für die KW 14 einsetze, in der die Positivrate am höchsten war mit 9,03%, dann kommt als Prävalenz 6,35% heraus. Das klingt irgendwie sinnig. Der Wert ist positiv, aber niedriger als die Positivrate. So soll es sein, wenn die Testgüte nicht optimal ist.
Für die KW 33, die mit der höchsten wöchentlichen Testanzahl, ist der Wert jedoch ebenfalls negativ: -2,15%. Die Positivrate ist in der Woche schon sehr klein (0,96%). Da die Testgüte suboptimal ist, muss die Prävalenz aber noch kleiner sein. Das ist -2,15% — nur, was ist eine Prävalenz <0%? Wo ist die Prävalenz hin, wenn sie in KW 14 noch mit einem Wert >0% da war und in KW 33 weg ist?
In KW 14 ist die Differenz zwischen Positivrate und Prävalenz 2,68%. In KW 33 ist sie 3,11%.
Eine Prävalenz <0% kann es aber nicht geben. Andererseits muss bei suboptimaler Testgüte eine Differenz zwischen Positivrate und Prävalenz sein. Was ist hier los?
Deutungsversuch
Ich glaube, die negativen Zahlen können auf zwei Weisen interpretiert werden:
Irgendeine Angabe stimmt nicht. Wenn die Formel korrekt ist, dann führt garbage in zu garbage out. Aber was stimmt nicht? Hat sich die Testgüte verbessert (Sensitivität, Spezifizität)? (Wenn ich beide mit 100% annehme, was nicht realistisch ist, wäre die Gesamtprävalenz 2,3%; bei 99%/99% wäre sie 1,63% usw. Es kommt also sehr auf die Testgüte an. Dass die übersteigert dargestellt wird, dafür gibt es ein Interesse. Die Angaben lt. CORRECTIV sind also eher optimistisch.) Oder gibt es weniger Tests als angegeben, denn dann wäre die Positivrate bei gegebenen positiven höher? (Dass man die positiven zu gering angibt, glaube ich nicht. Die Testzahl aufzublähen, liegt näher.)
Oder kann ich einfach annehmen, dass die Prävalenz so niedrig ist in Relation zur Testgüte, dass sich jetzt keine relevanten Aussagen mehr machen lassen? Wir sind im Rauschen angekommen? Das Virus ist im Grunde weg?
Das Ergebnis ist überraschend und verwirrt mich immer noch. Umso mehr wundert mich, dass ich bisher keine ähnliche Berechnung in den Medien gesehen habe. Das ist ja keine Raketenwissenschaft. Gerade angesichts fehlender repräsentativer Stichproben hätte man ja auf diese Weise mal eine grobe Obergrenze für die Durchseuchung ermitteln können. Die 6,35% für KW14 sind doch mal eine Ansage. Wenn man die in Beziehung setzt zur Vorauswahl (wieviele Symptomatiker waren unter den 408.348 Getesteten?), hätte man mal eine grobe Idee entwickeln können. Vielleicht wäre man bei 1–2% für die Prävalenz in der Bevölkerung angelangt?
Wenn ich mal 1% ganz grob ansetze als Durchschnitt während der „heißen Phase“ im April, die vielleicht ca. 5000 COVID-19 Tote gefordert hat. Und wenn ich dann annehme, dass in der Zeit nicht ständig dieselben 1% infiziert waren, sondern zuerst die einen, dann die nächsten und dann wieder andere, also die Infektion insgesamt z.B. durch 3% der Bevölkerung gerollt ist, dann komme ich auf ca. 2,5 Millionen Infizierte, die zu 5000 Todesfällen geführt haben. Das sind lediglich 2‰ (0,2%). Und das (!) ist die wirklich interessante Zahl. Die vom RKI genannten 4,1% sind völlig irrelevant. Völlig! Denn die beziehen sich nur auf einen beliebig gewählten Ausschnitt aus der Bevölkerung. Beliebig (als Gegenteil von repräsentativ) ist der Ausschnitt in der Testmenge und in der Auswahl der Getesteten.
Aber mit etwas Mathematik kann der RKI-Zahlennebel zum Glück zumindest ein wenig gelichtet werden. Die negativen Prävalenzen sind zwar merkwürdig, die Tendenz scheint mir jedoch klar: es gibt viele Infizierte und nur ganz, ganz wenige sterben. Und die gehören auch noch vor allem einer sehr engen Risikogruppe an.
Deshalb: Entspannen und den Sommer genießen. Und dann den Herbst und den Winter genießen. Mit guten Gefühlen stärkst du auch dein Immunsystem. Angst reduziert deine Abwehrkraft.
PS: Wer mal mit den Zahlen und der Berechnung spielen will, kann das in diesem Google Sheet tun: https://docs.google.com/spreadsheets/d/1Ca3Czg0ehDc9S5hemZyb0VGK1b2xfBIgcBSsyfzRHgc/edit#gid=1804019363