

Do you know what object-orientation (OO) is? Really? Do you know, who invented the term? Do you know what he meant by it? Probably not, because… well, it’s usually not taught when you learn about OO programming with your favourite programming language.
But I think it’s quite important to look back and really, really try to understand what was meant. It might tell us, why many OO applications are disappointing in many regards, not least of them being lack of understandability and testability.
The person who invented the term is Alan Kay. And what he thought back in 1967 was:
“I thought of objects being like biological cells and/or individual computers on a network, only able to communicate with messages”, Alan Kay in an email conversation
If you find that cryptic, you’re not alone. But he really meant it. And he added:
“messaging came at the very beginning”
and emphasised later by saying
“The big idea is ‘messaging’“, Alan Kay in another email
So, OO is about something resembling “biological cells” communicating with something resembling “messenger molecules”.
Did you know that?
And even if you knew that, what does that actually mean for the code you’re writing in C#, C++, Java, Python, Typescript or some other OO language?
Or are that OO languages? Some doubt might be in order since Alan Kay reminded the OOPSLA 1997 audience:
“I made up the term object-oriented, and I can tell you I did not have C++ in mind. [Laughter and applause]”
Biological cells
Before trying to map Alan Kay’s analogy onto the realm of coding, let’s see what it is he was talking about. Here’s an image of a neuromuscular junction, a simple to understand example of biological cells “working together”.

What’s going on here? ChatGPT explains it like this:

Hm… does that help? Yes, because in the analogy there is something pretty obvious: passengers use the train (neuron) to get to town (muscle) only in one direction.

Neurotransmitters flow only from neuron to muscle. It’s a one way communication, a one way commute. And there is not even feedback, no acknowledgement from the muscle. Likewise the train does not wait for passengers to get back on in case their ticket is not accepted by the gatekeeper.
This is, what Alan Kay had in mind.
Exactly this.
That’s object-orientation. I call it Radical Object-Orientation because it goes back to the roots of the term.
“This big idea is ‘messaging’”, i.e. data flowing unidirectionally from one object (source) to another (sink).
Abstraction of the analogy
Analogies are great for a start. They are making things more tangible. But in the end they need to be overcome, to be transcended.
From analogy to programming leads abstraction. How does Alan Kay’s analogy look then? It’s very simple:

There are two “entities” — formerly biological cells, now just geometric shapes — connected in an unidirectional way — an arrow pointing from source to sink — along which the communication runs, i.e. neurotransmitter molecules flow.
From that abstraction it’s a small step into the realm of programming: the biological analogies just have to be replaced with technical concepts:

Biological cells become objects, molecules become messages.
This is the original image of object orientation, Alan Kay had in mind.
But does that resemble in any way what you’re routinely coding in your favourite OO language? How can this be implemented?
The principle behind object-orientation
The implementation seems obvious given the ability of OO languages to instantiate objects from classes and send messages from one to the other by calling functions.
Unfortunately this common view is falling short in mirroring Alan Kay’s idea. It does not really appreciate the analogy. There are two crucial aspects to understand:
Messages really just flow unidirectionally. Even though Alan Kay underlined the importance of messages he did not spell out the unidirectionality of their travel. For him that must have been self-evident.
Objects don’t have a clue about each other. Alan Kay did not mention this, but it’s implicit in the biological reality of how cells work. They are autonomous and “self-centered”: They react to molecules in the environment and they release molecules into the environment. However they don’t have a clue if any other cells are in their environment.
Evolution lead to a differentiation of cells, e.g. neurons and muscle cells. Multi-celluar organisms only exist, because all the different cells evolved in a symbiotic, cooperative manner sharing a “molecular contract”: the molecules produced by one type are consumed by another type.
But that does not entail one producing cell (type) knowing if or where another, receiving cell (type) is located. Each cell is just doing its job oblivious of any other. Each is reacting to molecules and producing molecules.
That’s also the reason why there is absolutely no request-response message exchange. No cell is asking another to do a job for it. No cell is waiting for an answer from another. They are not holding on to each other demanding services to be delivered.
This can be distilled into a basic principle of Radical Object-Orientation:
Principle of Mutual Oblivion (PoMO)
The PoMO is a formalization of Alan Kay’s analogy. It captures the crucial aspects hidden in it.
Alan Kay had the intuition that software should be organized in a way so that its “working parts” (objects) are connected in the same loose manner as biological cells. Yes, they would need to cooperate in order to create the required behavior of software, but for that purpose they should not depend on each other as service providers. Objects, like biological cells, are in no position to demand anything. They just react to whatever presents itself to them and fits their offering (interface).
As the abstracted image should make clear: object-orientation means data flow. Alan Kay must have envisioned software as consisting of a set, even maybe a network of data flows. That was his big idea — and that ran counter to mainstream programming languages. Back then Cobol, Fortran, Algol, Pascal, C, also Assembler, all did not offer abstractions looking even remotely like data flows. The closest around that time was Unix with its pipe operator.
And still 50+ years later that hasn’t changed at least for the languages that now call themselves object-oriented. Strange, isn’t it.
Does that mean, “proper” object oriented programming is not possible with object oriented languages?
How not to do object-orientation
Let’s see how object-orientation is usually understood. As an example a trivial C# program letting the user calculate the average of a list of numbers entered:

You probably wouldn’t even employ object-orientation for this scenario. But humour me and check out this code. It shows in a nutshell how objects are usually understood/used:

Two objects are created. They — or to be more precise: their classes — are connected like this. It seems.
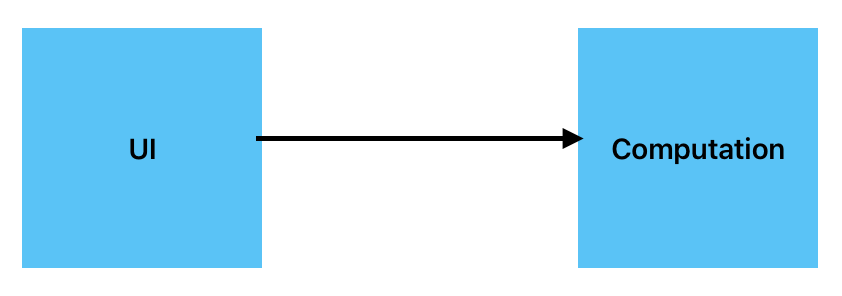
That looks like Alan Kay’s idea, doesn’t it.
But in fact it’s far from it. The simple reason: The arrow is not really unidirectional. Data flows in both directions. The truth is this:

And this is in contradiction with biology.
No biological cell sends a request to another and waits for a response to be sent back.
This is not how organisms work. This is… how human organizations work, but not networks of biological cells.
People are commandeering other people around and wait for services to be delivered. Not so biological cells. And hence — according to Alan Kay — objects shouldn’t do so either.
What’s the problem? The UI object has a job to do: ask for numbers, show average. But it also makes itself depend on another object, a Computation. Between it’s own responsibilities (red rectangles) it demands a service from another object.

This I call functional dependency: one function’s logic being dependent on another function.

And exactly that is in opposition to Alan Kay’s object-orientation. Functional dependencies are simply incompatible with his big idea “messaging”.
Where objects are functional dependent on each other, they have to know about each other. In the above case that’s the UI object knowing the Computation object.
The Computation object is oblivious to other objects. But UI is not. It can only do its job if it has gotten hold of a Computation object. For that purpose it even instantiates one. (Getting one injected or only knowing of an interface instead of a class does not change that. The DIP does not come to a rescue here.)
As you see: Just because you instantiate objects and let them call each other it’s not really object-oriented programming. It’s still pretty much just structured programming like in the 1980s with C and Pascal spiffed up with better memory allocation on the heap.
Ok, maybe that’s a little unfair. But I really want to make it clear: the big idea is missing from such coding practice. It’s still code based on control flow, not data flow. And that makes all the difference; that creates a ton of problems; that has led to a lot of symptom cures. The basic misunderstanding, though, hasn’t been identified in the OO camp.
Object-orientation true to Alan Kay’s big idea
What can be done about this? Are new programming languages needed? No. The existing ones are enough and they even provide great features for true Radical Object-Orientation. However they have to be used differently. Some self-restraint is in order.
Compare this implementation of the same requirements as above. It shows the necessary self-restraint. Computation hasn’t changed. It already was a “true” object. But UI needed to change. It had to give up its functional dependency on Computation.
How was that accomplished? By splitting it at the dependency:

What was done before the call to CalculateAverage() is now in Ask().
What was done after the call was moved to Display().
The logic itself in UI did not change. It’s still fulfilling the same responsibilities.

However now the object does not know anymore about any other objects. Its only job is to process certain messages (encoded as functions with their parameters).
This now can be expressed in a real data flow. All messages only flowing unidirectionally between objects:

Neither UI nor Computation know about each other; they are oblivious of other objects.
Each object is just waiting for messages fitting its offerings (interface) to arrive “from anywhere”.
Upon arrival of an input message an object does its job. Mostly that means it produces an output message. But it can also mean, it changes some state (produces a side effect).
This is fully in line with Alan Kay’s idea:
“OOP to me means only messaging, local retention and protection and hiding of state-process, […]”, Alan Kay
Biological cells have state, so do objects. There is no obsession with statelessness — but of course any state makes it more difficult to test an object’s message handling.
Now that UI is no longer functionally dependent, how is the message flow between the objects implemented? How can they create required behavior even though being oblivious of each other’s existence?
That’s what main() is responsible for. It integrates all objects into a new whole. It composes the data flow from complementary parts.

This is an application of the Integration Operation Segregation Principle (IOSP); a second distillate from Alan Kay’s analogy.

Switching to functions
What stands in the way of Radical Object-Orientation is a focus on classes. Hence it would seem more appropriate to call the current practice class-orientation.
For true object-orientation the focus should be switched from classes to functions. Functions first, classes second.
With functions as elements of composition data flows look much more naturally:

It’s immediately clear how the behavior is created as an interplay of different/complementary responsibilities. The flow of the transformation from input to output is obvious. Understandability is high. And the translation into code is trivial (see main() above).
Equally important is high testability. Logic is isolated in functions without any further dependencies. And logic is what needs to be tested.
It could be said: Functions are the new objects. But of course classes are still important. They provide the framework for functions to be aggregate in and keep/share state. Function are responsible for message handling on objects.
Conclusion
Object-oriented programming today mostly is not what it claims to be. That’s because it is not in accordance with the original idea of object-orientation. Alan Kay envisioned software to be made up of data flows. That means no processing step does know anything about any other upstream or downstream processing step.
Fortunately no new programming language needs to be invented to implement this idea. But a bit of self-restraint is necessary when using current OO languages. Practically speaking: functional dependencies are to be avoided.
Or conceptually speaking: the principles PoMO and IOSP have to be observed.
The benefits of true object-orientation as proposed in 1967 can be reaped immediately with current technology. Just let go of wrong assumptions of what OO means. Go back to its root. Look closely. And many of the problems ailing current code bases can be avoided.
It’s a paradigm shift. One that’s long overdue.
For more context see my blog on Radical Object-Orientation:

Wonderful article. Thanks Ralf. I just want to double check my understanding: Since integrations must not contain logic but are allowed to call operations (which contain logic), integrations are free from functional dependencies, right?