


Software wachsen lassen 3/4
Eine Reise durch das Softwareuniversum: Hosts

Software soll Verhalten zeigen, das ihre Anwender produktiver macht. Das wird mit Logik erreicht: Logik stellt Funktionalität her — Software transformiert — und erfüllt auch nicht-funktionale Anforderungen — Software transformiert schnell oder benutzerfreundlich.
All die Logik wird jedoch leider alsbald unübersichtlich. Damit Entwickler nicht zu sehr an Produktivität verlieren, während sie sie kontinuierlich erweitern, muss Ordnung her. Die wird mit Strukturelementen wie Funktionen und Modulen hergestellt.
Damit könnte alles gut sein in der Software-Welt. Wenn nicht, ja, wenn nicht manche nicht-funktionalen Anforderungen widerspenstig wären. Logik hat einfach Grenzen bei der Erfüllung nicht-funktionaler Anforderungen. Für manche müssen Entwickler eine weitere Dimension der Programmierung betreten: die Verteilung.
4. Hosts - Verhalten skalieren
Logik wird von einem Prozessor (bzw. Prozessorkern) ausgeführt. Ihre Performance hängt von dessen Charakteristika ab. Darüber hinaus beeinflusst die Gestaltung des Algorithmus und seiner Datenstrukturen, wie performant sie ist (Stichwort algorithmische Komplexität).
Aber was, wenn auch der beste Algorithmus nicht zur gewünschten Performance führt? Was, wenn die nicht-funktionale Anforderung überhaupt nicht durch Logik erfüllt werden kann? Letzteres ist z.B. der Fall für Ausfallsicherheit: Logik, ausgeführt auf einem Prozessor, kann per Definition nicht kompensieren, dass dieser Prozessor ausfällt.
In diesen Fällen besteht die Lösung darin, die Ausführung von Logik auf mehrere Prozessoren zu verteilen. Das geschieht mit einer Hierarchie von Hosts, wie ich sie nenne.
Jeder Host “beherbergt” entweder Logik direkt, d.h. führt sie aus, oder er aggregiert andere Hosts. Aus meiner Sicht lassen sich mindestens die folgenden Hosts unterscheiden:
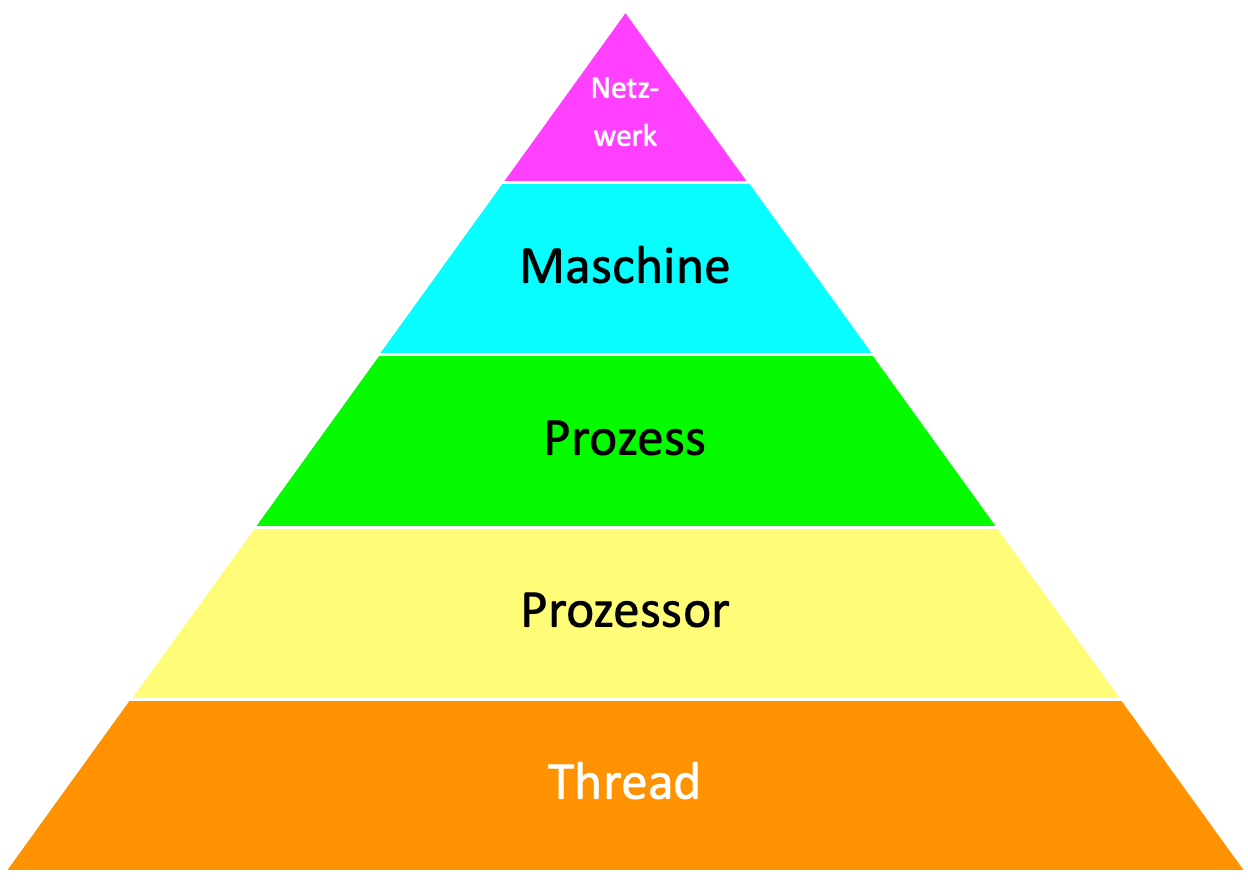
Die Verteilung von Logik beginnt mit Threads. Indem sie in mehreren Threads pseudo-parallel auf einem Prozessor ausgeführt wird, kann selbst ohne Veränderung von Logik die Reaktionsfähigkeit von Code gesteigert werden.
Wenn wirklich Performancesteigerung gegenüber single-threaded Logik erreicht werden soll, muss Logik in Threads gehostet werden, denen jeder ein eigener Prozessor (bzw. Kern) zugewiesen ist.
Eine Verteilung auf unterschiedliche Betriebssystemprozesse bietet weitere Vorteile. Der wesentliche ist die Isolation: Logik werden Ressourcen zugeordnet, auf die nur sie innerhalb des Prozesses Zugriff hat. Logik in anderen Prozessen ist ausgeschlossen; das befördert die Konsistenz von Daten und verhindert die Beeinträchtigung der Ausführung in einem Prozess, wenn etwas mit Logik in einem anderen schief geht.
Prozesse auf verschiedenen Maschinen erlaubt ein scale-out: statt zu versuchen, Logik isoliert performanter auf einer “dicker und dicker werdenden” Maschine zu betreiben (scale-up), kann sie viel billiger auf einer wachsenden Zahl kleinerer Maschinen ausgeführt werden. Zudem bieten auch Maschinen Isolation: Sollte eine ausfallen, kann Logik immer noch auf anderen weiterlaufen.1
Außerdem lässt sich Logik verteilt auf Maschinen näher an physischen Ressourcen, also am Ort eines materiellen Geschehens, betreiben, z.B. in Geräten wie Waschmaschine oder Fräse.Maschinen können schließlich in Netzwerken verbunden werden, um verteilte Logik miteinander kommunizieren zu lassen. Sind die Maschinen darin gleichberechtigt (Cluster), um Ausfallsicherheit zu gewährleisten? Sind die Peers oder bilden eine Hierarchie? Sind sie gar auf verschiedene Netzwerke verteilt? Die Verteilung in Netzwerken bietet sowohl die Möglichkeit der Isolation (Stichwort Firewall) wie auch Ressourcennähe.
Eine Lösung mit Problemen
Verteilung löst Probleme, die Logik allein nicht bewältigen kann. Gerade die Geschichte der Softwareentwicklung seit Mitte der 1990er ist eine der zunehmenden Verteilung von Code. Die Möglichkeit zur Verteilung ist ein Segen!
Allerdings wirft Verteilung selbst viele Probleme auf. Inkonsistenzen beim Zugriff auf gemeinsame in-memory Daten schon beim Multi-Threading sind da nur der Anfang. Das Wissen um die fallacies of distributed computing gehört deshalb zur Grundausbildung aller, die Code verteilen wollen. Hier die typischen Missverständnisse, die eine naive Herangehensweise an die Verteilung schnell in die Irre führen. Zitiert nach Wikipedia:
The network is reliable;
Latency is zero;
Bandwidth is infinite;
The network is secure;
Topology doesn't change;
There is one administrator;
Transport cost is zero;
The network is homogeneous.
Logik verteilt zu betreiben, ist also keine Kleinigkeit. Auch wenn zunehmend Technologien helfen, die Missverständnisse zu vermeiden oder die dahinter stehenden Probleme zu lösen… Verteilung bleibt schwierig. Sie zu beherrschen, ist für mich die 4. Kunst der Programmierung.
Anforderungen entwicklungsgerecht kategorisieren
In der Analyse werden Anforderungen gemeinhin als funktional und nicht-funktional kategorisiert. Das mag für den Kunden einen gewissen Informationswert haben. Ihm wird dadurch klar gemacht, dass eine Transformation entweder überhaupt vorhanden ist (funktionale Anforderung) bzw. in einer gewissen “Modalität”2 verfügbar ist (nicht-funktionale Anforderungen).
Aus Sicht der Entwicklung finde ich diese Kategorisierung jedoch nicht hilfreich. Was gibt sie einem Entwickler? Wie beeinflusst sie Entwurf oder Codierung? Alle Verhaltensanforderungen werden ohnehin mit Code umgesetzt.

Ich schlage daher vor, dass Entwickler Anforderungen für sich anderweitig kategorisieren. Für sie sind die Kategorien
Logik
Verteilung
informativ.
Eine Anforderung, die sich mit Logik umsetzen lässt, enthält weniger Risiko und braucht weniger Erfahrung mit speziellen Technologien. Darunter fallen alle funktionalen Anforderungen und einige nicht-funktionale.
Eine Anforderung jedoch, für die Verteilung hilfreich, gar unumgänglich ist, enthält gewöhnlich weit mehr Risiko zur Entwicklungs- wie zur Laufzeit. Sie umzusetzen braucht mehr Zeit und Geld. Womöglich muss sogar erst Kompetenz aufgebaut/eingekauft werden. Hier bewegt sich Entwicklung weit jenseits der Fachlichkeit (Domäne). Verteilung spielt natürlich nur bei nicht-funktionalen Anforderungen eine Rolle.
Solle eine Anforderung sowohl Logik wie Verteilung erfordern, liegt auch nahe, sie weiter zu unterteilen in Inkremente, die jeweils entweder nur Logik oder nur Verteilung erfordern.
In der Diskussion mit dem Kunden können Entwickler, die Anforderungen in dieser Weise kategorisieren, frühzeitig auf mögliche Komplikationen hinweisen oder sogar gegensteuern. Verteilung ist auch heute noch sehr schwierig. Die Physik ist unverändert; davon können selbst moderne Technologien nur bedingt abstrahieren.
Logik, Funktionen, Module, Hosts: Damit liegen alle Mittel der Programmierung auf dem Tisch. Jetzt gilt es, sie in Beziehung zu setzen. Das tue ich im nächsten Artikel, der all diese Dimensionen zum Softwareuniversum verbindet.
Ich bin noch unentschlossen, ob virtuelle Maschinen und Container eigene Ebenen in der Host-Hierarchie darstellen sollten. Mein Argument dagegen: Ihre Vorteile liegen nicht in der Erfüllung von Verhaltensanforderungen. Sie sind Mittel, um das Deployment zu vereinfachen; sie erhöhen die Produktivität von Entwicklern. Andererseits sind die keine Module, haben also nichts mit Ordnung zu tun. Zu den Stakeholdern Anwender und Entwickler gesellt sich also noch der Operator, d.h. derjenige, der Code vom Entwickler zum Anwender bringt und für ihn am Laufen hält. Damit verlasse ich allerdings das Reich von Clean Code Development und lasse diesen Gesichtspunkt außen vor.
Ich vermeide hier den Begriff Qualität, weil er sich sowohl auf funktionale wie nicht-funktionale Anforderungen anwenden lässt. “Modalität” scheint mir ein Ersatz, der dafür steht, “wie sich eine Transformation anfühlt”, z.B. performant, skalierbar, stabil…